







论文地址:http://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
摘要
大多数性能优越的视觉目标跟踪器很难有实时速度。在这篇文章中,我们提出了孪生候选区域生成网络(Siamese region proposal network),简称Siamese-RPN,它能够利用大尺度的图像对离线端到端训练。具体来讲,这个结构包含用于特征提取的孪生子网络(Siamese subnetwork)和候选区域生成网络(region proposal subnetwork),其中候选区域生成网络包含分类和回归两条支路。在跟踪阶段,我们提出的方法被构造成为单样本检测任务(one-shot detection task)。
我们预先计算孪生子网络中的模板支路,也就是第一帧,并且将它构造成一个检测支路中区域提取网络里面的一个卷积层,用于在线跟踪。得益于这些改良,传统的多尺度测试和在线微调可以被舍弃,这样做也大大提高了速度。Siamese-RPN跑出了160FPS的速度,并且在VOT2015,VOT2016和VOT2017上取得了领先的成绩。
1.引言
与适当设计的最先进的基于相关滤波器的方法相比,基于离线训练的基于深度学习的跟踪器可以获得较好的结果。关键是候选的孪生候选区域生成网络(Siamese-RPN)。它由模板分支和检测分支组成,它们以端到端的方式对大规模图像对进行离线训练。受到最先进的候选区域提取方法RPN 的启发,我们对相关feature map进行提议提取。与标准RPN不同,我们使用两个分支的相关特征映射进行提议提取。在跟踪任务中,我们没有预定义的类别,因此我们需要模板分支将目标的外观信息编码到RPN要素图中以区分前景和背景。
在跟踪阶段,作者将此任务视为单目标检测任务(one-shot detection),什么意思呢,就是把第一帧的bb视为检测的样例,在其余帧里面检测与它相似的目标。
综上所述,作者的贡献有以下三点:
1.提出了Siamese region proposal network,能够利用ILSVRC和YouTube-BB大量的数据进行离线端到端训练。
2.在跟踪阶段将跟踪任务构造出局部单目标检测任务。
3.在VOT2015, VOT2016和VOT2017上取得了领先的性能,并且速度能都达到160fps。
2.相关工作
RPN详细介绍:区域候选网络RPN
SiamFC详细介绍:SiamFC:用于目标跟踪的全卷积孪生网络
2.1 RPN
RPN即Region Proposal Network,是用RON来选择感兴趣区域的,即proposal extraction。例如,如果一个区域的p>0.5,则认为这个区域中可能是80个类别中的某一类,具体是哪一类现在还不清楚。到此为止,网络只需要把这些可能含有物体的区域选取出来就可以了,这些被选取出来的区域又叫做ROI(Region of Interests),即感兴趣的区域。当然RPN同时也会在feature map上框定这些ROI感兴趣区域的大致位置,即输出Bounding Box。
RPN详细介绍:区域候选网络RPN
2.2 One-shot learning
最常见的例子就是人脸检测,只知道一张图片上的信息,用这些信息来匹配出要检测的图片,这就是单样本检测,也可以称之为一次学习。
3 Siamese-RPN framework
3.1 SiameseFC:
所谓的Siamese(孪生)网络,是指网络的主体结构分上下两支,这两支像双胞胎一样,共享卷积层的权值。上面一支(z)称为模板分支(template),用来提取模板帧的特征。φ表示一种特征提取方法,文中提取的是深度特征,经过全卷积网络后得到一个6×6×128的feature map φ(z)。下面一支(x)称为检测分支(search),是根据上一帧的结果在当前帧上crop出的search region。同样提取了深度特征之后得到一个22×22×128的feature map φ(x)。模版支的feature map在当前帧的检测区域的feature map上做匹配操作,可以看成是φ(z)在φ(x)上滑动搜索,最后得到一个响应图,图上响应最大的点就是对应这一帧目标的位置。

Siamese网络的优点在于,把tracking任务做成了一个检测/匹配任务,整个tracking过程不需要更新网络,这使得算法的速度可以很快(FPS:80+)。此外,续作CFNet将特征提取和特征判别这两个任务做成了一个端到端的任务,第一次将深度网络和相关滤波结合在一起学习。
Siamese也有明显的缺陷:
1. 模板支只在第一帧进行,这使得模版特征对目标的变化不是很适应,当目标发生较大变化时,来自第一帧的特征可能不足以表征目标的特征。至于为什么只在第一帧提取模版特征,我认为可能因为:
(1)第一帧的特征最可靠也最鲁棒,在tracking过程中无法确定哪一帧的结果可靠的情况下,只用第一帧特征足以得到不错的精度。
(2)只在第一帧提模板特征的算法更精简,速度更快。
2. Siamese的方法只能得到目标的中心位置,但是得不到目标的尺寸,所以只能采取简单的多尺度加回归,这即增加了计算量,同时也不够精确。
网络训练原理:

如图所示,上一帧的目标模板与下一帧的搜索区域可以构成很多对的模板-候选对(exemplar-candidate pair), 但是根据判别式跟踪原理,仅仅下一帧的目标与上一阵的目标区域(即 exemplar of T frame-exemplar of T+1 frame)属于模型的正样本,其余大量的exemplar-candidate pair都是负样本。这样就完成了网络结构的端到端的训练。
3.2 Siamese-RPN
左边是孪生网络结构,上下支路的网络结构和参数完全相同,上面是输入第一帧的bounding box,靠此信息检测候选区域中的目标,即模板帧。下面是待检测帧,显然,待检测帧的搜索区域比模板帧的区域大。中间是RPN结构,又分为两部分,上部分是分类支路,模板帧和检测帧的经过孪生网络后的特征再经过一个卷积层,模板帧特征经过卷积层后变为2k×256通道,k是anchor数量,因为分为两类,所以是2k。下面是边界框回归支路,因为有四个量[x, y, w, h],所以是4k右边是输出。

3.3 孪生特征提取子网络
预训练的AlexNet,剔除了conv2 conv4两层 。φ(z)是模板帧输出,φ(x)是检测帧输出
3.4 候选区域提取子网络
分类支路和回归支路分别对模板帧和检测帧的特征进行卷积运算:

![]() 包含2k个通道向量,中的每个点表示正负激励,通过交叉熵损失分类;
包含2k个通道向量,中的每个点表示正负激励,通过交叉熵损失分类;![]() 包含4k个通道向量,每个点表示anchor和gt之间的dx,dy,dw,dh,通过smooth L1 损失:
包含4k个通道向量,每个点表示anchor和gt之间的dx,dy,dw,dh,通过smooth L1 损失:
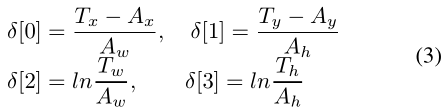
Ax, Ay, Aw, Ah是anchor boxes中心点坐标和长宽; Tx, Ty, Tw, Th是gt boxes,为什么要这样呢,因为不同图片之间的尺寸存在差异,要对它们做正规化。
smoothL1损失:

3.5 训练阶段:端到端训练孪生RPN
因为跟踪中连续两帧的变化并不是很大,所以anchor只采用一种尺度,5中不同的长宽比(与RPN中的3×3个anchor不同)。当IoU大于0.6时是前景,小于0.3时是背景.
4. Tracking as one-shot detection
平均损失函数L:

如上所述,让z表示模板patch,x表示检测patch,函数φ表示Siamese特征提取子网,函数ζ表示区域建议子网,则一次性检测任务可以表示为:
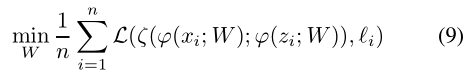

如图,紫色的部分像原始的Siamese网络,经过同一个CNN之后得到了两个feature map,蓝色的部分是RPN。模板帧在RPN中经过卷积层,![]() 和
和![]() 当作检测所用的核。
当作检测所用的核。
简单的说,就是预训练模版分支,利用第一帧的目标特征输出一系列weights,而这些weights,包涵了目标的信息,作为检测分支RPN网络的参数去detect目标。这样做的好处是:
(1)模板支能学到一个encode了目标的特征,用这个特征去寻找目标,这会比直接用第一帧的feature map去做匹配更鲁棒。
(2)相比原始的Siamese网络,RPN网络可以直接回归出目标的坐标和尺寸,既精确,又不需要像multi-scale一样浪费时间。
经过网络后,我们将分类和回归特征映射表示为点集:

这里,i∈[0,w),j∈[0,h),l∈[0,2k),p∈[0,k) 。
由于分类特征图上的奇数通道代表正激活,我们收集所有![]() 中的前K个点,其中l是奇数,并表示点集为:
中的前K个点,其中l是奇数,并表示点集为:
![]()
其中I,J,L是一些索引集。
变量i和j分别编码相应锚点的位置,l编码相应锚点的比率,因此我们可以导出相应的锚点集合为:
![]()
此外,我们发现![]() 上ANC*的激活得到相应的细化坐标为
上ANC*的激活得到相应的细化坐标为
REG*=![]()
因为是分类,![]() 选前k个点,分两步选择:
选前k个点,分两步选择:
第一步,舍弃掉距离中心太远的bb,只在一个比原始特征图小的固定正方形范围里选择,如下图:

中心距离为7,仔细看图可以看出,每个网格都有k个矩形。
第二步,用余弦窗(抑制距离过大的)和尺度变化惩罚(抑制尺度大变化)来对proposal进行排序,选最好的。具体公式可看论文。
用这些点对应的anchor box结合回归结果得出bounding box:

an就是anchor的框,pro是最终得出的回归后的边界框 至此,proposals set就选好了。
然后再通过非极大抑制(NMS),顾名思义,就是将不是极大的框都去除掉,由于anchor一般是有重叠的overlap,因此,相同object的proposals也存在重叠。为了解决重叠proposal问题,采用NMS算法处理:两个proposal间IoU大于预设阈值,则丢弃score较低的proposal。
IoU阈值的预设需要谨慎处理,如果IoU值太小,可能丢失objects的一些 proposals;如果IoU值过大,可能会导致objects出现很多proposals。IoU典型值为0.6。
5.实施细节:
我们使用从ImageNet [28]预训练的改进的AlexNet,前三个卷积层的参数固定,只调整Siamese-RPN中的最后两个卷积层。这些参数是通过使用SGD优化等式5中的损耗函数而获得的。共执行了50个epoch,log space的学习率从10-2降低到10-6。我们从VID和Youtube-BB中提取图像对,通过选择间隔小于100的帧并执行进一步的裁剪程序。如果目标边界框的大小表示为(w,h),我们以大小A×A为中心裁剪模板补丁,其定义如下。
![]()
其中p =(w + h)/2
之后将其调整为127×127。以相同的方式在当前帧上裁剪检测补丁,其大小是模板补丁的两倍,然后调整为255×255。
在推理阶段,由于我们将在线跟踪制定为一次性检测任务,因此没有在线适应。我们的实验是在带有Intel i7,12G RAM,NVidia GTX 1060的PC上使用PyTorch实现的。
学习更多编程知识,请关注我的公众号:

















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











