






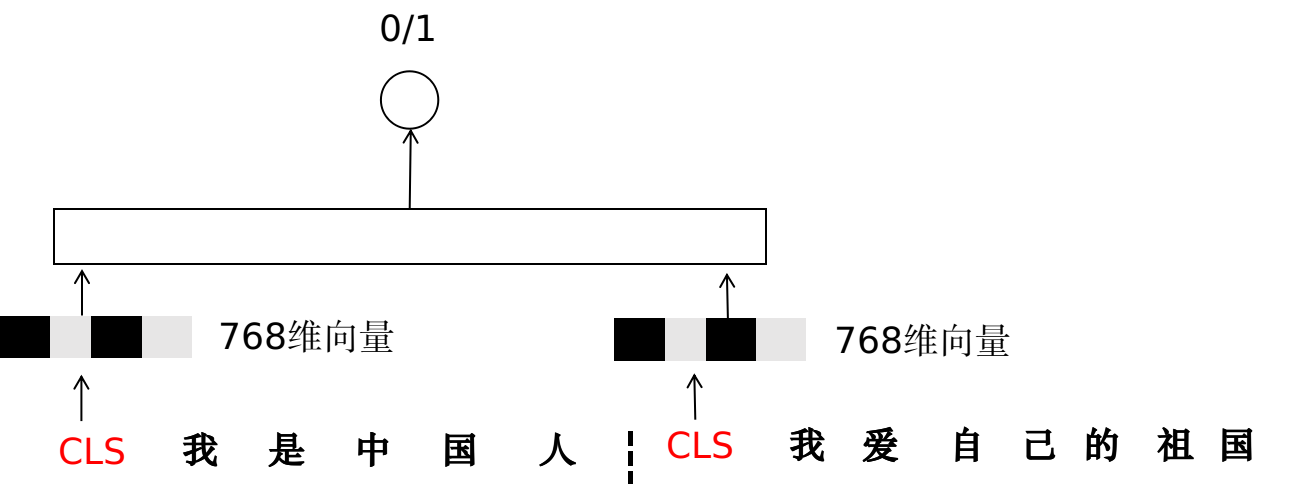
Bert的NSP任务是预测上句和下句的关系。对一个句子的表征可以用CLS的embedding,bert的NSP任务,NSP 是一个预测两段文本是否在原文本中连续出现的二元分类损失。NSP 是一种二进制分类损失,用于预测原始文本中是否有两个片段连续出现,如下所示:通过从训练语料库中获取连续片段来创建正样本;通过将来自不同文档的句段配对而创建负样本; 正样本和负样本均以相同的概率 (概率各自为 0.5)采样。NSP任务在单个任务中融合了主题预测和连贯性预测,同一篇文档里的句子,更侧重是一个主题,前后两个句子的连贯更有利于连贯性的学习,不同文章中的句子很大概率表达的是不同的主题,学习起来难度比较小。















 8301
8301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









