







R-CNN模型存在三个问题:
(1) 训练分为多个阶段,步骤繁琐: 微调卷积网络 + 训练SVM二分类器 + 训练边框回归器
(2) 训练耗时,占用磁盘空间大:5000 张图像产生几百G的特征文件
(3) 速度慢: 使用GPU, VGG16模型处理一张图像需要47s
SPP-NET相比于R-CNN大大加快目标检测的速度,但是依然存在两个问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络 + 训练SVM二分类器 + 训练边框回归器
(2) SPP-NET在微调网络的时候固定了卷积层,只对全连接层进行微调,而对于一个新的任务,有必要对卷积层也进行微调。(分类的模型提取的特征更注重高层语义,而目标检测任务除了语义信息还需要目标的位置信息)
针对这两个问题,RBG又提出Fast R-CNN, 一个精简而快速的目标检测框架。
2、把整张图片输入到全卷积的网络中,在最后一个卷积层上对每个ROI求映射关系,并用一个ROI pooling layer来统一到相同的大小,提取一个固定维度的特征表示。
3、 Fast R-CNN在网络微调的过程中,将部分卷积层也进行了微调,取得了更好的检测效果
(1) 训练分为多个阶段,步骤繁琐: 微调卷积网络 + 训练SVM二分类器 + 训练边框回归器
(2) 训练耗时,占用磁盘空间大:5000 张图像产生几百G的特征文件
(3) 速度慢: 使用GPU, VGG16模型处理一张图像需要47s
SPP-NET相比于R-CNN大大加快目标检测的速度,但是依然存在两个问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络 + 训练SVM二分类器 + 训练边框回归器
(2) SPP-NET在微调网络的时候固定了卷积层,只对全连接层进行微调,而对于一个新的任务,有必要对卷积层也进行微调。(分类的模型提取的特征更注重高层语义,而目标检测任务除了语义信息还需要目标的位置信息)
针对这两个问题,RBG又提出Fast R-CNN, 一个精简而快速的目标检测框架。
Fast R-CNN整体框架:
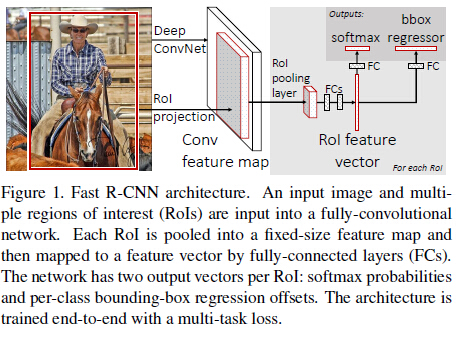
2、把整张图片输入到全卷积的网络中,在最后一个卷积层上对每个ROI求映射关系,并用一个ROI pooling layer来统一到相同的大小,提取一个固定维度的特征表示。
3、继续经过两个全连接层(FC)得到特征向量
4、特征向量经由各自的FC层,得到两个输出向量:softmax分类和边框回归
Fast R-CNN融合了R-CNN和SPP-NET的精髓,并且引入多任务损失函数,使整个网络的训练和测试变得十分方便。
相比R-CNN和SPPnet网络,FAST-RCNN有以下改进:
1、ROI pooling layer实际上是SPPnet的一个精简版,SPPnet对每个候选区域使用了不同大小的金字塔映射,而ROI pooling layer只需要下采样到一个特征图,例如VGG16网络,所有候选区域对应了一个7*7*512维度的特征向量作为全连接层的输入
2、R-CNN训练过程分为了三个阶段,而Fast R-CNN直接使用softmax替代SVM分类,同时利用多任务损失函数边框回归也加入到了网络中,这样整个的训练过程是端到端的(除去候选区域提取阶段)3、 Fast R-CNN在网络微调的过程中,将部分卷积层也进行了微调,取得了更好的检测效果















 3523
3523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









