






论文:DSOD: Learning Deeply Supervised Object Detectors from Scratch
论文地址:https://arxiv.org/abs/1708.01241
论文代码:https://github.com/szq0214/DSOD
目前,所有基于深度学习的目标检测方法都需要预先在 ImageNet 分类任务上预训练的模型作为初始权重。
这种预训练 + 微调 的方式主要存在以下几个问题:
1、缺乏灵活性。在ImageNet上预训练模型非常麻烦,如果只使用预训练好的模型,不能根据需要去调整模型结构;
2、Loss差异。由于ImageNet模型的类别和目标检测问题的类别分布差别较大,分类的目标函数和检测的目标函数也不一致,从预训练模型上微调可能和检测问题的有一定的优化学习偏差;
3、问题域不匹配。并不是所有检测任务都是在自然RGB图像上进行的,如医学图像、多谱图像的检测。
DSOD方法借助于DenseNet 隐式的deeply supervised的特性,结合其他一些设计原则,成功地实现了目标检测模型的从零开始训练。并且模型参数相比其他方法也要小很多。
DSOD是在SSD算法的基础上进行改进的,可以简单理解为SSD+DenseNet=DSOD(作者文中也曾尝试从0开始训练region proposal based的检测算法比如Faster RCNN,R-FCN等,发现模型很难收敛;而proposal-free的检测算法比如SSD却可以收敛,虽然效果一般,因此最后采用proposal-free的检测模型SSD。
DSOD的网络结构如下:
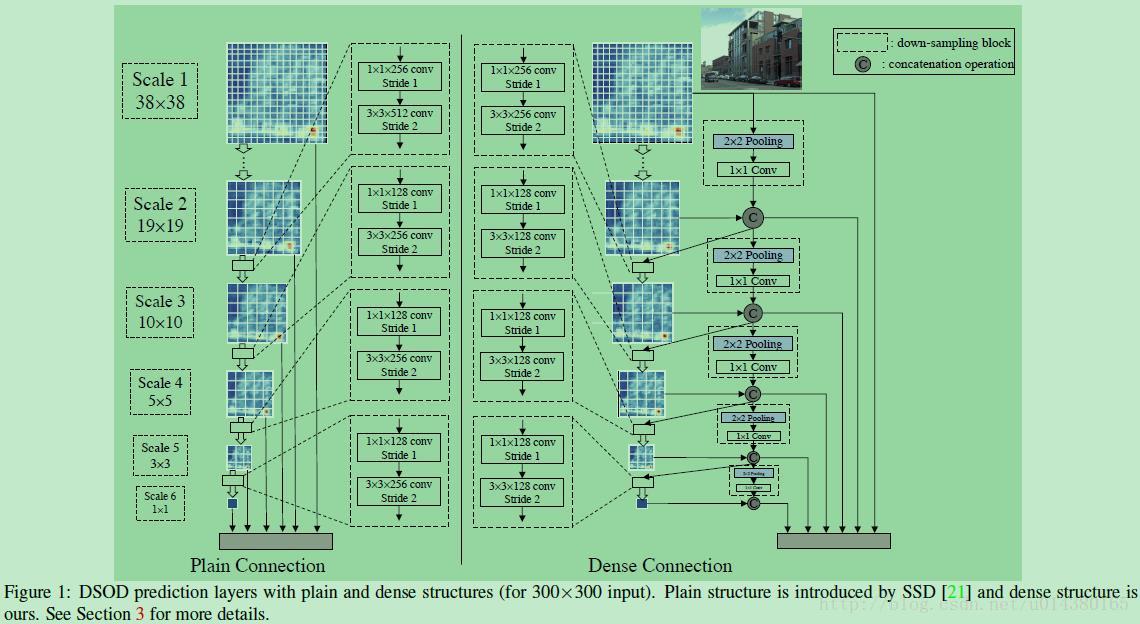
解释:
左边的plain connection表示SSD算法中的特征融合操作,这里对于300*300的输入图像而言,一共融合了6种不同scale的特征。在每个虚线矩形框内都有一个1*1的卷积和一个3*3的卷积操作,这其实就是一个bottleneck,也就是1*1的卷积主要起到降低channel个数从而降低3*3卷积计算量的作用。
右边的dense connection表示本文引入densenet思想的特征融合操作。dense connection部分左边的虚线矩形框部分和plain connection的右边虚线矩形框部分很像,差别在于channel个数(dense connection中3*3的channel个数是对应plain connection中3*3的channel个数的一半),主要是因为在plain connection中,每个bottleneck的输入直接是前一个bottleneck的输出,但是在dense connection中,每个bottleneck的输入是前面所有bottleneck的输出的concate。dense connection部分右边的矩形框是down sampling block,包含2*2的max pooling和一个1*1的卷积,作者也提到先进行降采样再进行1*1卷积主要可以减少计算量。因此可以看出DSOD是SSD+DenseNet的结果。
DSOD模型不仅参数更少(适合于手机、无人机等资源受限的设备)、性能更强,更重要的是不需要在大数据集(如ImageNet)上预训练,使得DSOD的网络结构设计非常灵活,根据自己的应用场景可以设计自己所需要的网络结构。















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









