









1 简介
本文根据2018年《NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS》翻译总结的。通过标题可以看出来Tacotron 2包括Tacotron 和WAVENET。
Tacotron 2是一个可以直接从文本合成语音的神经网络模型。有两部分构成,第一部分是循环序列到序列的特征预测网络,其将字符embedding转换为mel-scale 频谱(SPECTROGRAM);第二部分是修改的WaveNet模型,其作为语音合成器,将mel-scale 频谱合成为时域的波形(waveform)。这两部分别进行训练。
2 模型结构
下图蓝色部分encoder加橙色部分decoder是第一部分,即循环序列到序列的特征预测网络,mel-scale 频谱(SPECTROGRAM)预测网络;绿色部分是第二部分,修改的WaveNet模型。我们使用mel- frequency spectrograms 连接两部分模型。
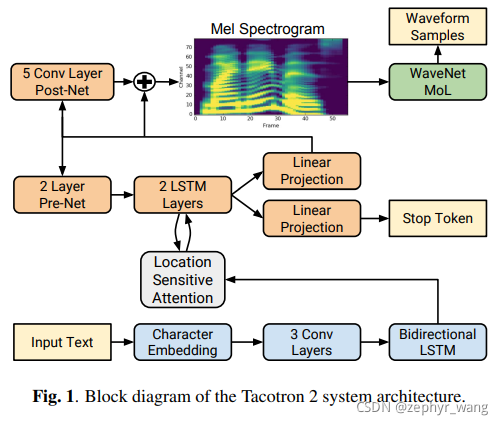
2.1 中间特征-- mel-scale 频谱(SPECTROGRAM)
我们使用mel- frequency spectrograms 连接两部分模型。
mel- frequency spectrograms和linear- frequency spectrograms相关的,即 short-time Fourier transform (STFT)。灵感来自于人类听觉系统,用较少的维度去总结frequency,强度低frequency,不强调高frequency。
2.2 mel-scale 频谱(SPECTROGRAM)预测网络
包括encoder和带注意力的decoder。
Decoder是一个自回归循环神经网络。
使用的 location-sensitive attention,其扩展了相加attention机制,使用来自前一个decoder time steps的累计attention权重。
在pre-net之前和之后,最小化summed mean squared error (MSE),帮助收敛。
增加了“stop token”预测。
相比原来的tacotron,我们在encoder和decoder中使用 vanilla LSTM and convolutional layers,而不是“CBHG” stacks and GRU recurrent layers。
2.3 WaveNet Vocoder
将mel-scale 频谱合成为时域的波形(waveform)。
WaveNet比Griffin-Lim生成更高质量的声音。
3 实验结果
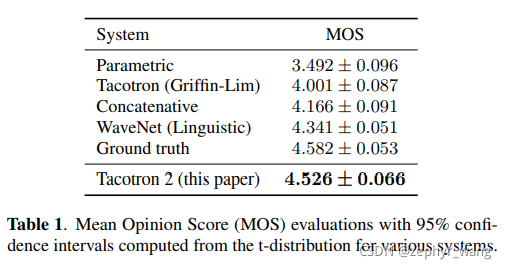
可以看到tacotron2效果比tacotron、WaveNet、参数化模型、连接模型等效果好。
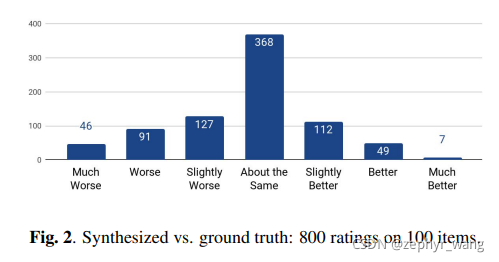
tacotron2生成的声音也和原音大部分感觉一样。














 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









