







2015_11_25老文章了。思路依旧是【预训练的视觉模型+无标签的数据对=新的模态】
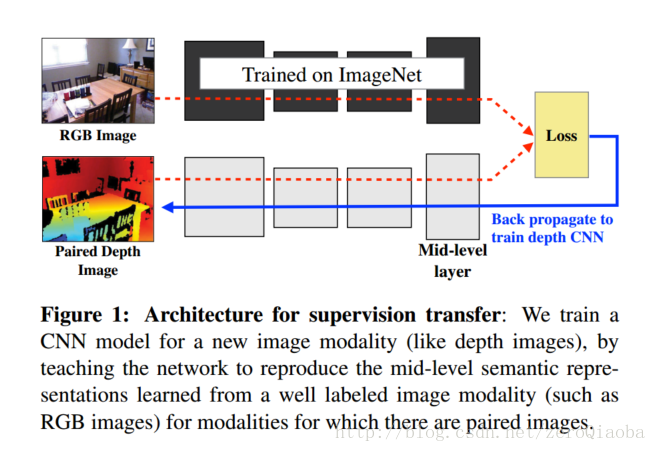
代码:https://github.com/s-gupta/fast-rcnn/tree/distillation
实验以pool5层计算loss。利用teacher model教会一个新的网络mid-level semantic representation. Loss choose L2 distance。

2016_10_27 这篇文章主要讲的是多任务迁移。【预训练的视觉模型+无标签的音视频对=好的音频模型】。也有原始代码,同时提供了他们整理的数据库,叫做Flickr-SoundNet。
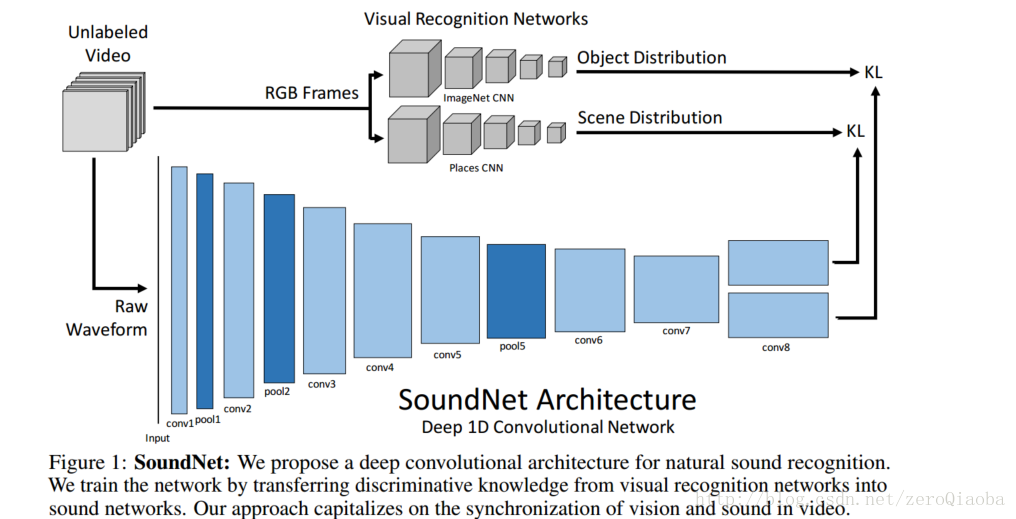
数据:从Flickr上下载了大量无标注的数据,200,0000训练。使用popular标签和字典中的关键词。语音信号预处理:转成MP3,下采样到22khz,8bit量化。损失采用KL散度。两个视觉层的模型都是预训练好的。

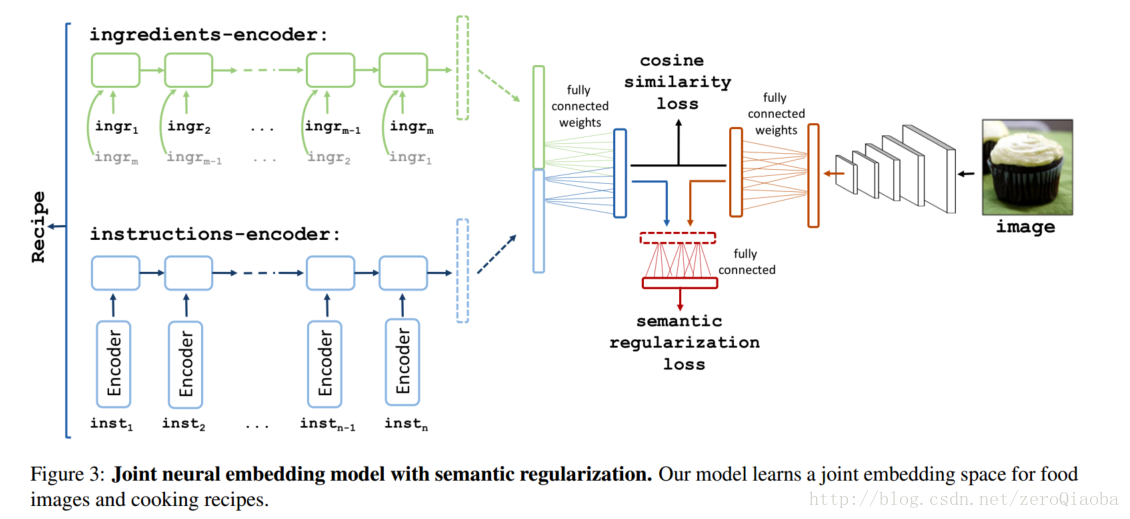
2017CVPR论文,讲的是recipes and image的检索。【这篇文章和See,Hear, and Read: Deep Aligned Representations很相似,一个有true label, 就用true label 对他们进一步区分;没有true label,就用teacher-student model进行联合处理。上层都要考虑中间表达层的损失】
Skip-thoughts 将中间句子编码到语义层,解码出前一个句子和后一个句子。参考的是arxiv 2015/6/22的一篇文章。用无监督的方式学习一个有顺序的句子的向量。文章中叫做skip-instructions vectors. 然后输入到一个LSTM中【因为有顺序】。
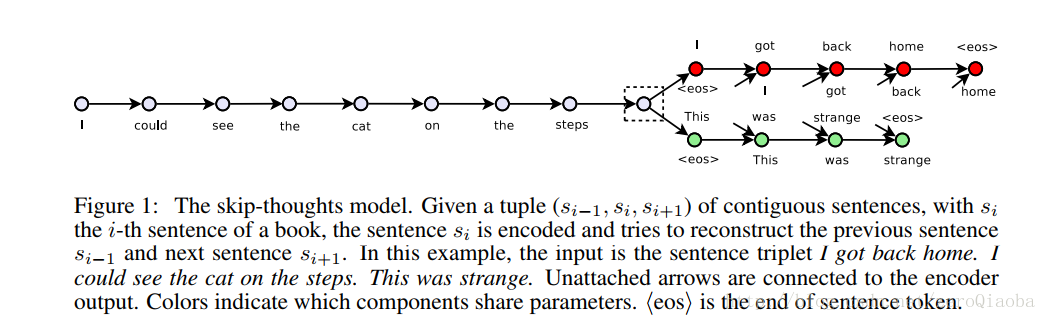
由于成分信息没有顺序,因此采用BLSTM。
损失采用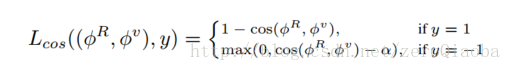
和See,Hear, and Read: Deep Aligned Representations 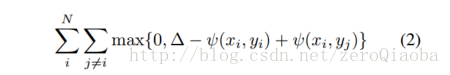
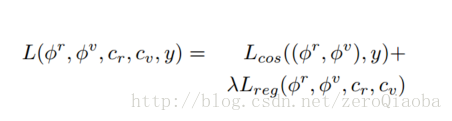
优化:分布优化。如果同时优化整体的模块,容易导致网络不收敛。之前的经验告诉我们,要先分布优化每一个子系统,再对完整的系统finetuning。

2017/6/3,主要用于跨模态的检索和迁移学习,得到三个模态对齐的不可逆的表示方式。我觉得这篇文章的创新点:【三模态迁移】
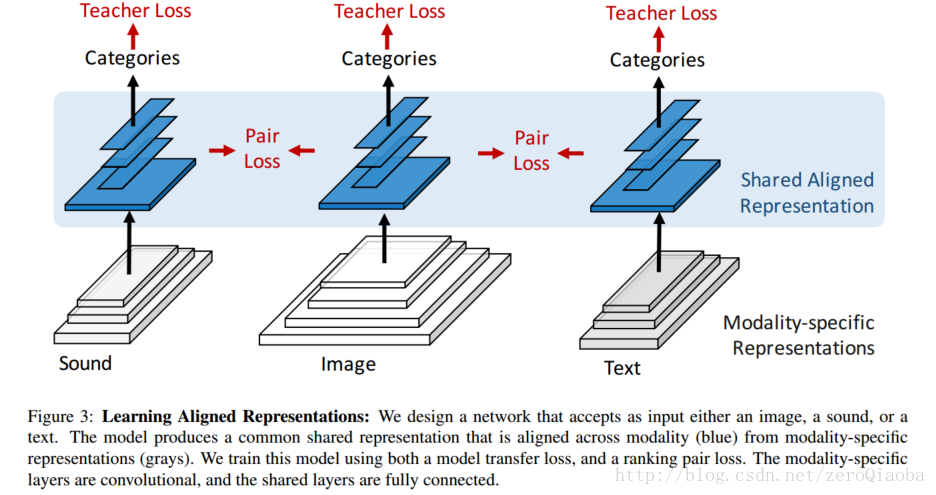
创新点:
双模态->三模态;
采用两个loss:teacher loss 和pair loss,保证他们的一致性和差异性;
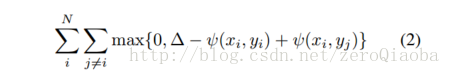
训练的时候,三模态统一的数据不好找,因此采用image-sound和image-text的数据训练,最后发现可以扩展到sound->text上去。

这篇文章2017/8/1发表的,比较新,才过去两个月。这篇文章不一样的地方在于,它利用AVC任务【学习音频和视频是不是匹配的】,学习sound和video的含义。
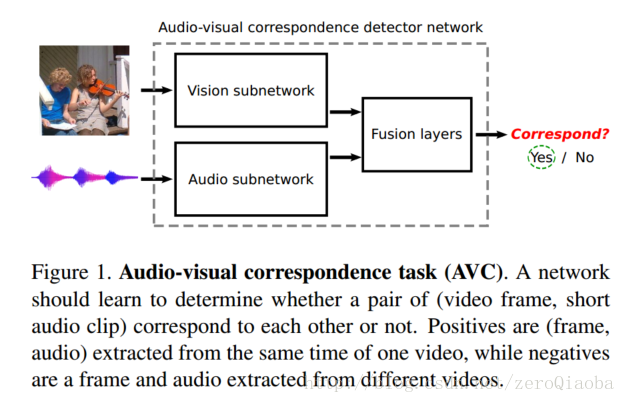
音频输入采用log spectrogram。48k audio ->log spectrogram->257*199*1 features.视频采用三通道的RGB图片,卷积后面加着BN和ReLU激活。用Flickr-SoundNet训练,然后用labeled Kinetics-Sounds作为评价。
迁移学习 transfer learning
最新推荐文章于 2024-08-15 09:50:04 发布

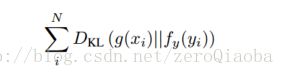















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









