









身为一个电控组的成员,我们当接触一个新的概念的时候首先应该去了解他的硬件,其次再者是软件,而且在学习新的应用时,也应该清楚什么我们要着重了解,什么我们要清楚即可,以can为例。我们先从他的硬件说起。Can硬件一共有两种接法,但核心还是两根信号线,一个h,一个l。先说不了解硬件的第一个问题,注意到两个电阻了没有,这个叫终端电阻。
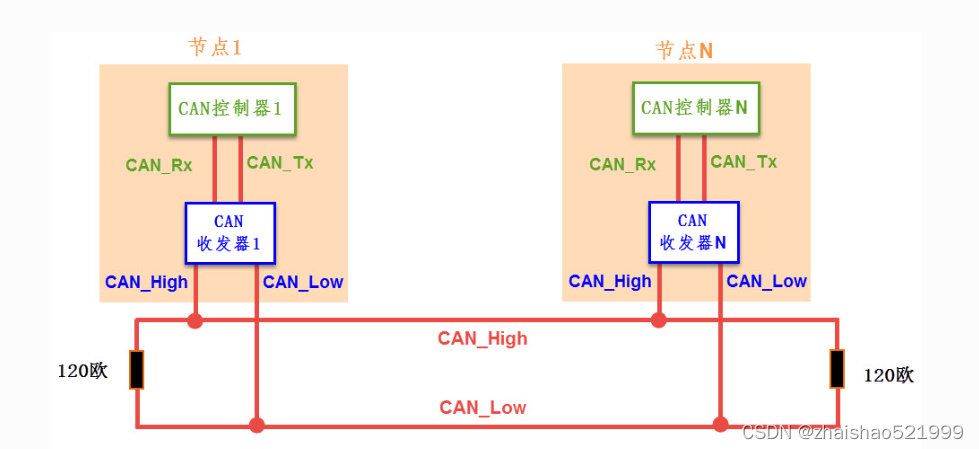
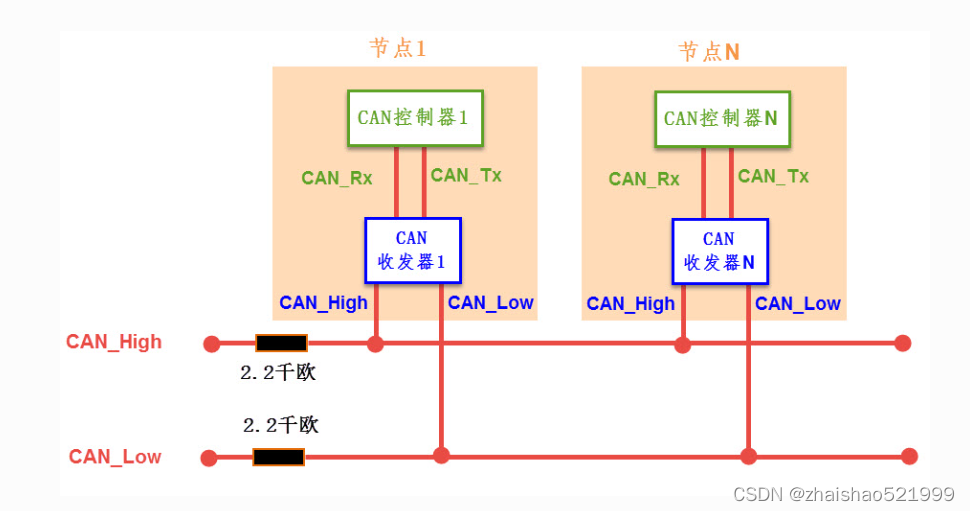
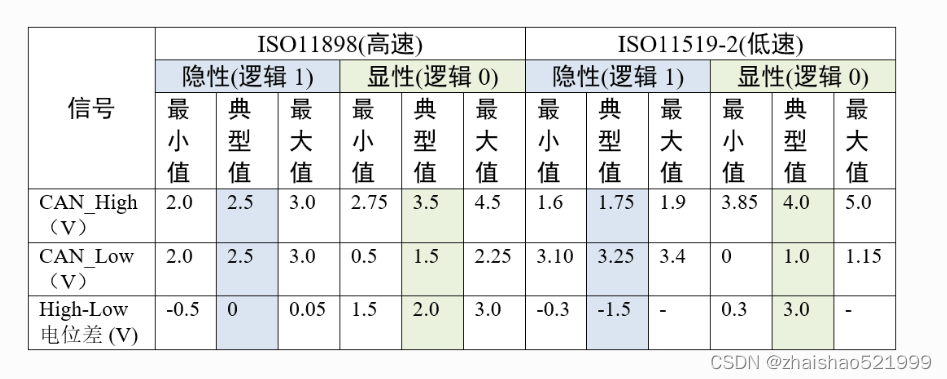
它的作用如下:1、提高抗干扰能力,让高频低能量的信号迅速走掉 2、确保总线快速进入隐性状态,让寄生电容的能量更快走掉; 3、提高信号质量,放置在总线的两端,让反射能量降低。这一部分其实,我们是属于了解部分,它的作用其实不了解,无伤大雅。但是我黑线画的部分,是集成在芯片内的。而两个电阻,是在can通讯模块上贴片的,假如再加一个can通讯模块,而不去除我们外加模块的电阻贴片的话,其实是会出问题的,这也体现了我们需要了解硬件的原因,这是结构方面。再者是数据传输方面,首先我们将传输的信息叫做报文,报文的首段是id,如果id与外设的id一致,那么我们这个外设就去接收这个信号,再者我们采用的是差分信号,差分信号就是用h和l上两个电压进行相减,最后的出来一个电压(这样当外界影响来临时,同时作用两根数据线,那么干扰将相应减少),用所得的电压对我们规定的高低电压区间范围来进行对照,如果是高电压范围,则为高,如果是低电压范围,则为第,再者说一下,所得出的低电压是显性(下文所得会加d)的,而所得出的d高电压是隐形的,这就意味着,d低电压控制权会比d高电压控制权高,也就是意味着,当报文来临时,如果报文中id部分0多,那么说明与之通讯的外设优先等级较高,也就是较为紧急。举个例子,can通讯被广泛应用在汽车领域,当我撞车时,我can发送一串0000000…直接把报文id拉到最高,此时我希望开启安全气囊还是放首歌,显而易见,安全气囊更加紧急。因此今后我们可以通过报文id的判断,来判断所连接的外设在整个通讯中的地位。其次是FIFO,这个FIFO就相当于我们发送接收邮箱,我们先把数据放到FIFO里,再通过移位寄存器,将其数据发送出去。或是通过移位寄存器,将信息移动到接收FIFO里其实这里有个细节,CAN有两个接受邮箱,3个发送邮箱,但是接收邮箱是我们所熟知的FIFO0,和FIFO1,但是发送邮箱并没有定义,这就是为什么我们每次发送数据时,需要额外定义,那么我们有没有办法去知道,它是从什么邮箱中发出去的呢?这个固件库和hal库有区别,hal库很简单,就是我们定义的,但固件库can发送函数是一个有返回值的,有0.1.2分别对应三个邮箱。到此为止,我们的硬件介绍的大差不差,其实你说这些身为一个电控成员,我们到底需不需要了解,我觉得其实很有必要,因为电控应该是软硬通吃的(小人认为)。
再者就是比较头疼的东西了,那就是软件方面,我们先来说一下,can的数据帧,你有没有想过,你设置了很多很多的bsp1,bsp2到底是什么,它为什么那样设置,还有sjw是什么?如果都了解的话,那就很厉害啦,下来就当复习一下叭!
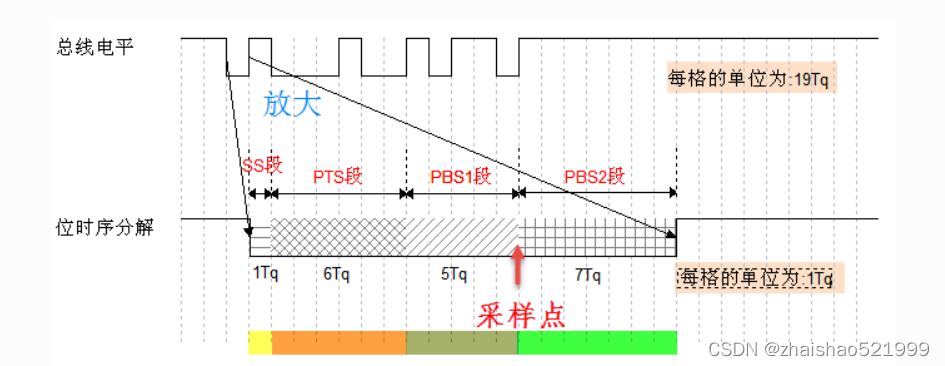
上面既是一个数据帧,但是can的数据帧不复杂,数据位却特别复杂,一个数据位占用的间,其实相当于很多tq的时间,而tq则是发送一个数据位的实践再除以总tq除,下面我口述可能不标准,我截取了一段网上的话:SS段(SYNC SEG)
SS译为同步段,若通讯节点检测到总线上信号的跳变沿被包含在SS段的范围之内,则表示节点与总线的时序是同步的, 当节点与总线同步时,采样点采集到的总线电平即可被确定为该位的电平。SS段的大小固定为1Tq。
PTS段(PROP SEG)
PTS译为传播时间段,这个时间段是用于补偿网络的物理延时时间。是总线上输入比较器延时和输出驱动器延时总和的两倍。PTS段的大小可以为1~8Tq。
PBS1段(PHASE SEG1),
PBS1译为相位缓冲段,主要用来补偿边沿阶段的误差,它的时间长度在重新同步的时候可以加长。PBS1段的初始大小可以为1~8Tq。
PBS2段(PHASE SEG2)
PBS2这是另一个相位缓冲段,也是用来补偿边沿阶段误差的,它的时间长度在重新同步时可以缩短。PBS2段的初始大小可以为2~8Tq
Pts其实最后和pbs1合并了
那我们所设置的sjw,其实就是每次补偿的位数,好比在pts的第2个tq出现了下降边沿,也就是晚到了两个tq,那么假如我们设置的sjw是2,它会自动在补偿段减去2tq的时间(本段,即pbs1),以保证数据在ps1和ps2中间被准确接收。从而达到更加准确接收数据的目的。
再者最为头疼的要来了can的滤波器,滤波顾名思义,过滤掉不必要的报文从而接收想要的报文,那么你有没有考虑过,我们报滤波器的报文为什么要那样设置,其实我们的滤波器,它并没有滤波,为什么,下来你就知道啦,滤波器一共分为掩码模式,和列表模式。
列表模式是要求我们的id和我们要配置的idh,idl里面的id位一致,为什么说id位一致呢?那idh和idl里面难道还有不是id的成分么,对。

中间还夹杂有其他东西,也就是说,当我们选择列表模式时,id与我们设置的id要一一对应,至于如何去设置这个idh和、,idl,等等会去讲解。
当我们配置成掩码模式的时候,我们会要去设置maskid,那么这个有什么作用的,当mskid对应位为1的时候,id对应的位可与idh或l相对应的id的那一位不相同,举个例子。
Mskid = 0x1111
Lskid = 0x1111
这就代表着,我们的id,必须与我们idh和idl里面相同,其实就是列表模式。
Mskid = 0x0000
Lskid = 0x1111
这就代表着,我们id的高位可以与idh的高位完全不一样,但是低位必须一样即可实现过滤。
例子
Id = 任意;
CAN_InitStructure.CAN_FilterIdHigh = (((ID<<3) | CAN_Id_Extended | CAN_RTR_Data)&0xFFFF0000)>>16;
CAN_InitStructure.CAN_FilterIdLow = (((ID<<3) | CAN_Id_Extended | CAN_RTR_Data)&0xFFFF);
CAN_InitStructure.CAN_FilterMaskIdHigh = 0x0000;
CAN_InitStructure.CAN_FilterMaskIdLow = 0xFFFF;
这种情况下,当我们id转化为idh之后与我们所设置的idh不同,但id转化为idl之后与我们所设置的idl相同(必须),滤波器也能将这条报文滤过(接收)。
有一种东西叫鸡肋,杨修说过,食之无味,弃之可惜。我们加入了学校的机器人战队,所学创造出来的荣誉,是整个团队的荣誉,而我们所学的知识,将会伴随我们一生,甚至以后工作,但假使很多东西我们都会的10成有4,那么将来几年会剩下10之有2,那时候我们脑中的知识,会不会像鸡肋一样,再去了解,又花费了更多的时间,为何不一开始就彻底去把他弄懂呢?我们可能不需要去掌握每一个细节,去深刻了解终端电阻的作用,但我们至少要知道它的存在,对于重点的内容,我们更是要去彻底吃透。但是cubmax方便的配置,到底是使你的知识掌握的更牢固了,还是更使你去固定反复去配相同的参数呢?
那些最后带不走的成为了团队的养分和你奋斗的岁月,带走了的,成为了你余生的黄金。















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









