








论文地址:论文地址
一、目前存在的问题及相应的改进
1、3D卷积来提取时序特征的计算量问题
**问题:**在视频任务下,传统卷积方法中为了更好的提取时序特征,一般采用3D的卷积方式,其中的计算量不管怎么改进也避免不了计算量大的问题。
**改进:**文中使用最新的2D结构来提取空间信息,然后在结果特征上采用注意力机制来添加时序信息。此方法的输入只需要RGB视频帧流即可,不需要类似光流这样的其他流。
2、针对长序列时序信息的提取
**问题:**Transformers一开始用于具有连续性的语言模型上,在视频任务中由于视频帧也具有连续性,所以也同样可以使用。但还是有个问题是,视频太长了,怎么处理长时间的序列问题是个需要研究的地方,最近的工作都没有从这方面下手。
**改进:**基于Longformer,其提出的注意力机制方式能够超越短片段处理,保持全局性,并可以注意所有输入序列的标记。

3、关于速度和精确性的提高
对比其他算法,本文的算法能够在同样的epoch训练下获得最高的精度,并且训练的速度比最新的快16.1倍。
4、同期方法
**(1)Non-local Neural Networks:**利用注意力计算输入的不同位置的联系,表明了注意力机制在视频任务中有着很好的表现。
但是他需要预计算的特征信息,不能够有效的支持端到端的特征提取网络。
(2)SlowFast:探索了一条流下两个不同速率的分支来分别提取空间和长短的时序特征。
(3)X3D:基于SlowFast,介绍了一种拓展维度的结构,包括时序、帧速、宽度、深度、bottleneck宽度。与SlowFast相比,他在相同精确的条件下能够更加轻量。
**(4)Transformer在其他领域的方法:**图像分类中的ViT和DeiT;目标检测的DETR
二、本文内容
1、主要结构
(1)2D的空间骨干网络可以使用任意的,用于特征提取
(2)基于注意力的模块可以堆叠更多的层,或者设置不同的Transformer模型,这样可以处理长序列。
(3)分类的head能够被修改为处理不同的视频任务,比如动作识别。
下图为文章主要结构:
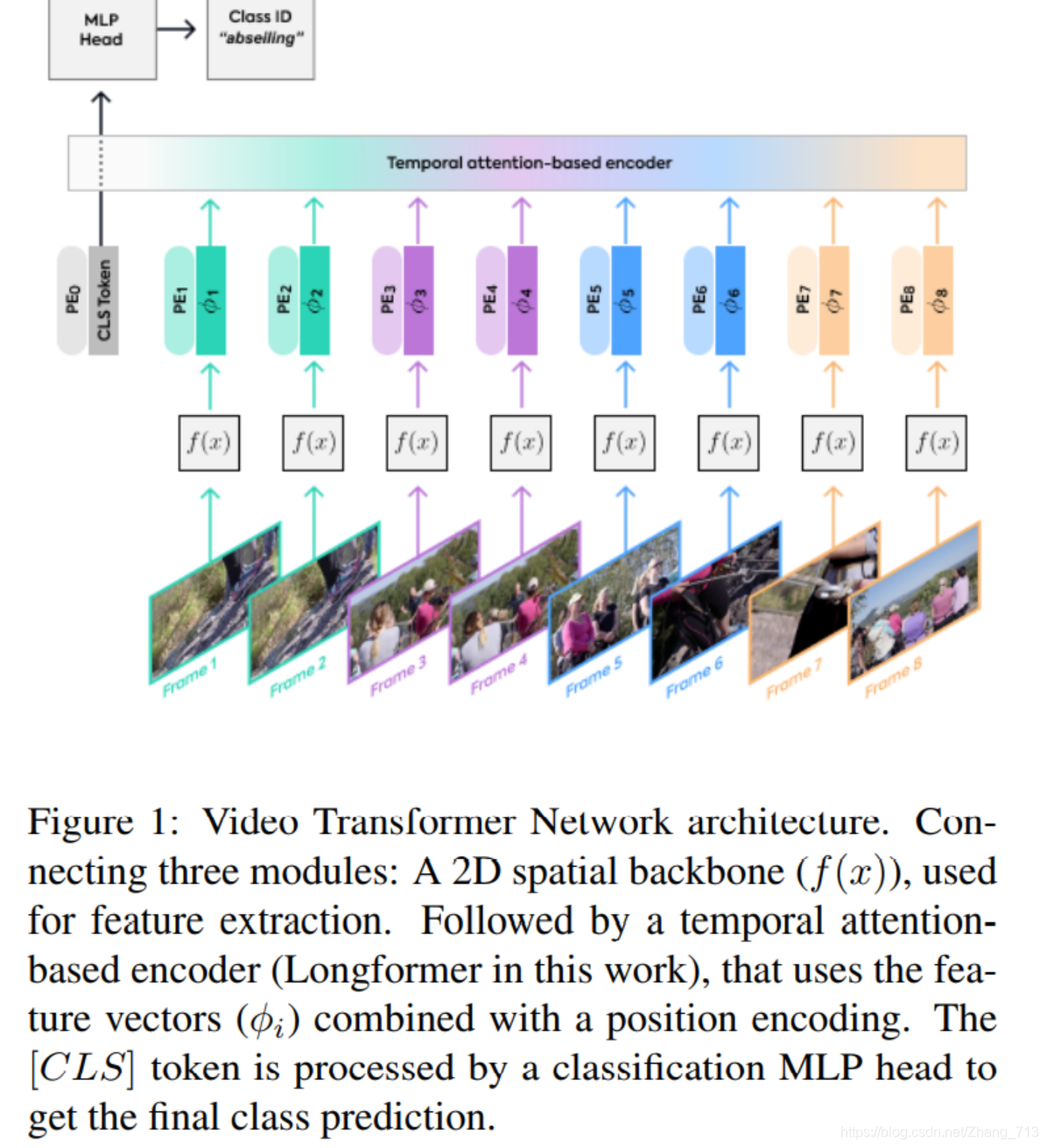
f(x)是个2D空间网络,用于特征提取;接着是一个基于时间注意力的编码器,使用特征向量φi并结合位置编码。CLS由分类MLP head处理来得到最终的分类预测。
2、对于空间骨干网络的选取
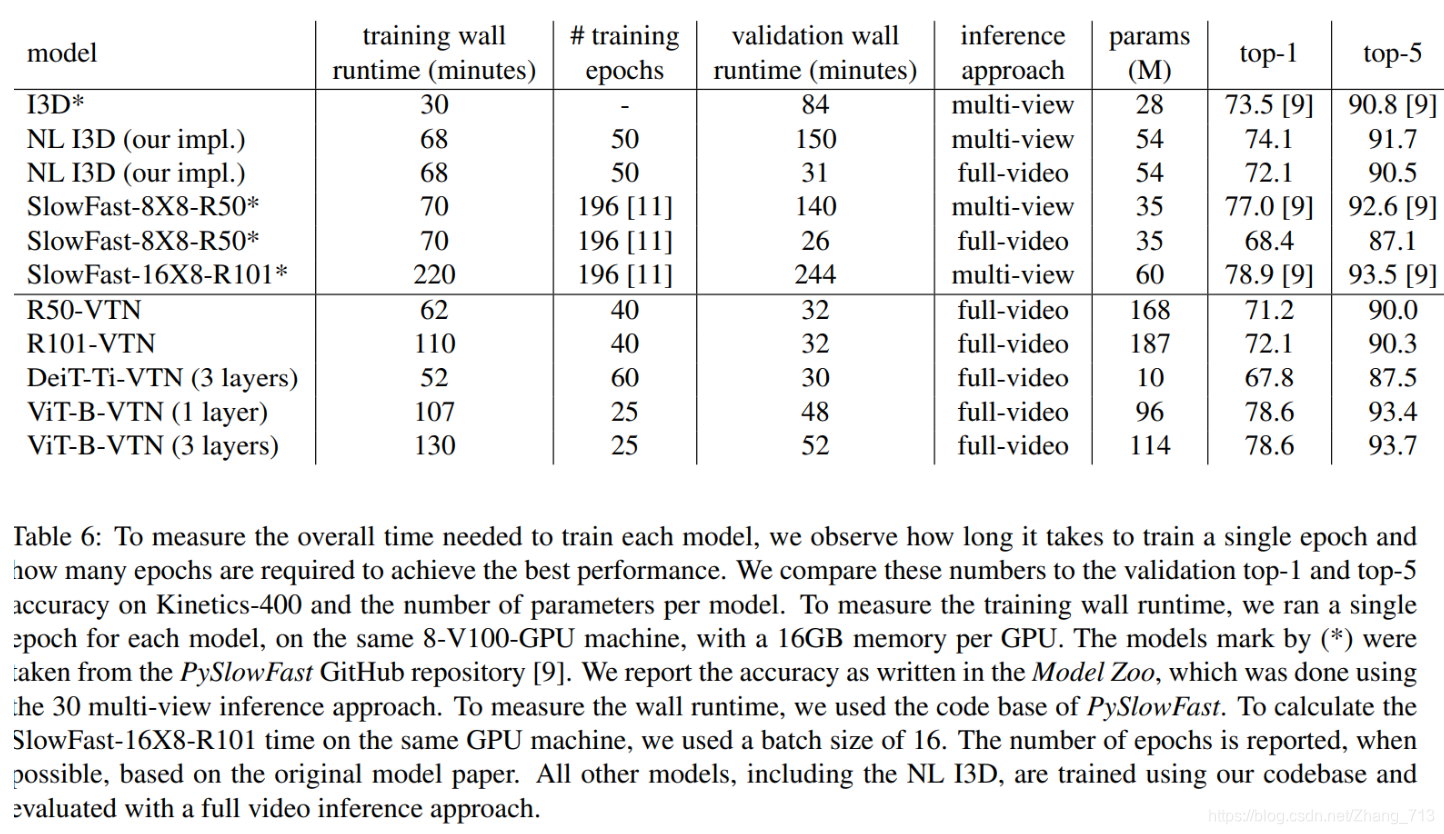
由下图作出了对比。

三、实验
使用了预训练模型ImageNet,用的数据集为Kinetics-400,为了表现出文中方法的优越性,作出了一下对比。ViT-B-VTN方法与SlowFast最好的效果对比的情况下,训练的epoch只需25即可达到这样的效果,并且训练和验证的时间也只是130和52.当然参数量还是一个问题。
四、总结
后续可基于VTN作出一些工作,效果要比3D卷积好特别多。文中的方法在计算量、运行时间、精确度都有着非常好的进步,足以可以见Transformer在视频任务中的表现是很不错的。
积好特别多。文中的方法在计算量、运行时间、精确度都有着非常好的进步,足以可以见Transformer在视频任务中的表现是很不错的。














 3279
3279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









