







TexTeller:基于ViT的端到端公式识别模型,可以把图片转换为对应的latex公式。
TexTeller用了550K的图片-公式对进行训练(数据集可以在(https://huggingface.co/datasets/OleehyO/latex-formulas)获取),相比于LaTeX-OCR(使用了一个100K的数据集),TexTeller具有更强的泛化能力以及更高的准确率,可以覆盖大部分的使用场景(扫描图片,手写公式除外)。
前置条件
python=3.10
pytorch
注意: 只有CUDA版本>= 12.0被完全测试过,所以最好使用>= 12.0的CUDA版本
查看服务器配置
nvidia-smi
CUDA版本= 12.2,8张24g RTX 3090显卡。
开始
克隆本仓库:
git clone https://github.com/OleehyO/TexTeller
安装pytorch后,再安装本项目的依赖包:
pip install -r requirements.txt
安装huggingface hub包
pip install -U "huggingface_hub[cli]"
从Hugging Face上下载模型权重:
https://huggingface.co/OleehyO/TexTeller/tree/main
新建一个报存模型文件夹,将模型放入其中
mkdir formula_model
把包含权重的目录上传远端服务器,然后把TexTeller/src/models/ocr_model/model/TexTeller.py中的REPO_NAME = 'OleehyO/TexTeller’修改为REPO_NAME = ‘formula_model’
进入TexTeller/src目录,在终端运行以下命令进行推理:
python inference.py -img "/path/to/image.{jpg,png}"
运行
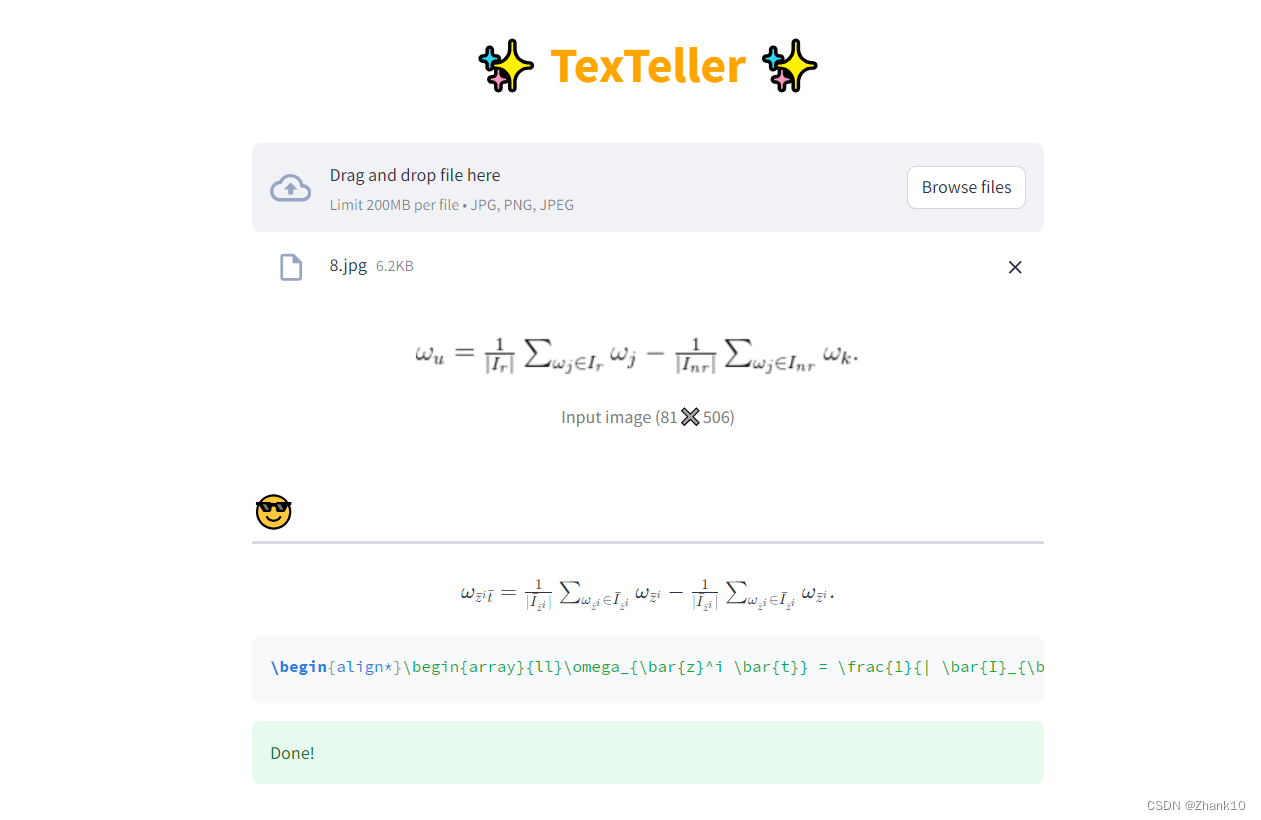
python3 inference.py -img "8.jpg"
模型识别结果

将识别的结果放入https://www.latexlive.com/home。得到如下
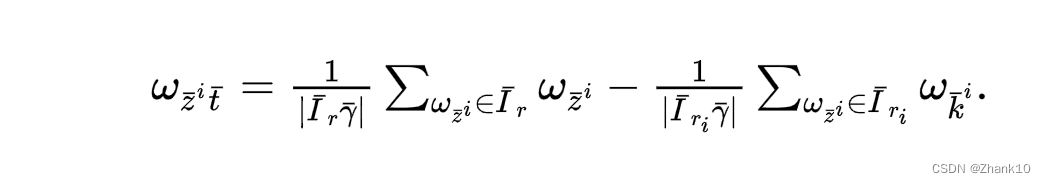
实际结果为:
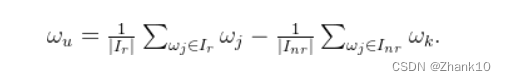
由此可见还是有一些差别,后续会持续优化模型。
web
要想启动web demo,你需要先进入 TexTeller/src 目录,然后运行以下命令:
./start_web.sh
然后在浏览器里输入http://localhost:8501就可以看到web demo
你可以改变start_web.sh的默认配置, 例如使用GPU进行推理(e.g. USE_CUDA=True) 或者增加beams的数量(e.g. NUM_BEAM=3)来获得更高的精确度


















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









