






 本文介绍了UniMERNet,一种专为解决数学表达式识别(MER)中复杂性和多样性挑战而设计的深度学习模型。文章详细描述了数据集UniMER的特点、模型架构及其实验结果,表明UniMERNet在处理各类数学表达式,包括印刷、屏幕捕获和手写表达式,具有显著优势。
本文介绍了UniMERNet,一种专为解决数学表达式识别(MER)中复杂性和多样性挑战而设计的深度学习模型。文章详细描述了数据集UniMER的特点、模型架构及其实验结果,表明UniMERNet在处理各类数学表达式,包括印刷、屏幕捕获和手写表达式,具有显著优势。
DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
引言:数学表达式识别的重要性与挑战
数学表达式识别(Mathematical Expression Recognition, MER)是文档分析中的一个关键任务,它旨在将基于图像的数学表达式转换为相应的标记语言,如LaTeX或Markdown。在科学文档提取等应用中,MER的重要性体现在其帮助维持文档逻辑连贯性的能力上。与典型的光学字符识别(Optical Character Recognition, OCR)任务不同,MER需要对复杂结构有更深入的理解,包括上标、下标和各种特殊符号。
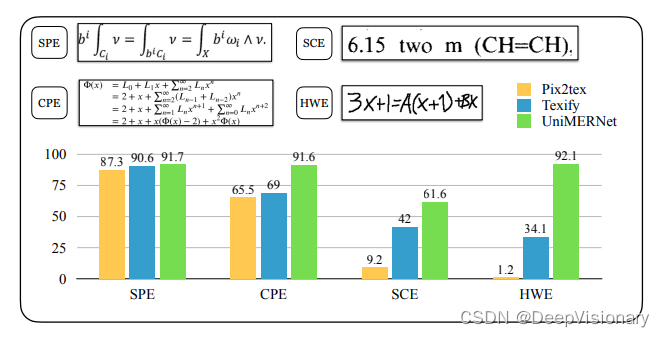
现有的研究主要集中在提高相对简单的渲染表达式和手写数据的识别准确性上,通过一系列MER算法实现这一目标。然而,现实世界的场景要求处理复杂、长的表达式以及来自扫描文档或网页截图的噪声、扭曲图像。为填补这一空白,我们引入了一个全面的基准测试,UniMER-Test,它扩展了现有测试集,包括更长和更多现实场景的表达式。我们的基准测试激励了MER在鲁棒性和实际使用中的进步。如图1所示,我们对现有的最先进的MER方法进行了全面评估,这些方法在识别简单的印刷表达式方面表现出了显著的能力。然而,当这些方法被测试在更复杂的印刷表达式,特别是长公式时,它们的性能明显下降。当这些方法应用于现实世界的表达式,如嵌入在噪声背景中的屏幕捕获表达式和手写表达式时,性能退化更加明显。
为了应对这些挑战,我们首先介绍了UniMER数据集,这是一个专为数学表达式识别(MER)量身定制的广泛收集,包括100万个精心策划的表达式。设计旨在补充和验证MER的进步,该数据集包括全面的UniMER-1M训练样本和彻底的UniMER-Test测试集,旨在通过提供与现有数据集相比更广泛的表达式多样性来激发进一步的研究。与数据集一起,我们提出了UniMERNet,这是一个调整到表达式序列长度的模型,它通过其额外的长度感知模块(LAM),在预测前利用关于表达式长度的上下文信息,使其能够生成与输入图像的视觉特征相匹配的表达式序列长度。通过图像增强技术进一步增强了该模型,显著提升了其在现实世界应用中的性能。
论文标题:UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition
机构:Shanghai AI Laboratory
论文链接:https://arxiv.org/pdf/2404.15254.pdf
项目地址:暂无提供
UniMER数据集的介绍与特点
UniMER数据集是为了应对现实世界中公式识别的多样性挑战而特别设计的。该数据集分为两个子集:UniMER-1M训练集和UniMER-Test测试集。UniMER-1M训练集涵盖了现实世界中遇到的各种数学表达式,而UniMER-Test则用于全面、准确、多维度的评估。
具体来说,UniMER-1M包含1,061,791个Latex-Image样本对,涵盖了从简短到复杂、长公式的表达式。其构建的一个关键方面是仔细平衡不同长度分布的需要。这种平衡对于训练在UniMER-1M上的模型来说,显著提高了整体识别准确性和泛化能力。UniMER-Test专门为现实世界场景中的MER进行全面评估而构建,提供了从四个维度详细评估MER的能力,包括6762个简单印刷表达式(SPE)、5921个复杂印刷表达式(CPE)、4774个屏幕捕获表达式(SCE)和6332个手写表达式(HWE)。这些多样化的表达式总数达到23789个样本,确保了对MER性能的彻底评估。
UniMERNet模型架构详解
UniMERNet是一个针对各类公式有效处理的新型架构。如图4所示,UniMERNet采用了基于变换器的编码器-解码器架构作为其基础框架。
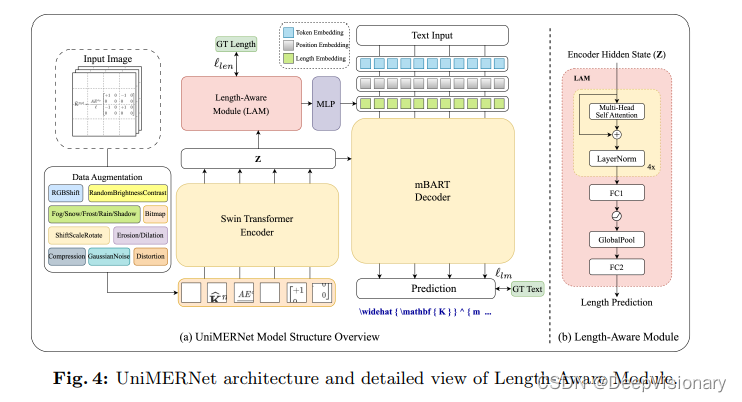
在训练阶段,每个输入的公式图像I ∈ R3×H0×W0会经过一个图像增强模块,该模块将单一图像表示转变为多样化的图像集,有效地应对现实世界场景中公式的多样化表现。接着,Swin Transformer编码器处理图像以生成特征向量Z,该向量被送入两个不同的模块。mBART解码器接收特征向量Z,并通过交叉注意机制与输出文本序列进行交互,促进预测公式的生成。同时,长度感知模块利用特征向量来估计原始公式图像对应的序列长度。这一长度信息被编码并整合到解码器的输入中,为解码器生成公式提供额外的上下文指导。解码器结合特征向量Z、令牌嵌入、位置嵌入和长度嵌入来预测公式。损失函数包括文本序列匹配损失和公式长度预测损失,其中ℓlm和ℓlen分别对应语言建模损失和长度损失。对于语言建模损失,我们采用交叉熵损失,以最小化预测的下一个令牌的概率分布与训练数据中观察到的实际分布之间的差异。同时,长度损失ℓlen使用SmoothL1 Loss来规范预测的数学表达式的长度,确保模型生成的长度预测与编码器的视觉特征相匹配。
UniMERNet通过其编码器-解码器变换器架构,提供了一个强大的解决方案,以应对多样化真实世界场景中的公式识别挑战。它结合了创新的长度感知模块(LAM)和图像增强技术,有效地应对了公式的多样化表现,展现出了卓越的鲁棒性和多功能性。

实验设置与评估指标
1. 实验设计
实验的主要目的是评估和验证UniMERNet模型在处理各种数学表达式识别任务中的效能。为此,我们使用了UniMER-1M数据集进行模型训练,并利用UniMER-Test数据集进行全面评估。UniMER-1M数据集包含了从简单到复杂的各种数学表达式,而UniMER-Test则专门设计用来测试模型在实际应用场景中的表现。
2. 评估指标
为了全面评估模型性能,我们采用了以下三种主要的评估指标:
- BLEU分数:原本用于评估机器翻译质量的BLEU分数,通过比较模型生成的输出和标准答案之间的n-gram重叠,用于量化模型在数学表达式识别任务中的表现。
- 编辑距离:这一指标衡量的是将模型输出转换为正确答案所需的最少字符修改次数,用以评估模型在字符级别的准确性。
- 表达式识别率(ExpRate):特别针对手写数学表达式识别任务,ExpRate表示模型完全正确预测数学表达式的百分比。
这些指标共同构成了一个多维度的评估框架,使我们能够从不同角度全面了解模型性能。

实验结果与分析
1. 实验结果
在使用UniMER-1M数据集训练后,UniMERNet在UniMER-Test上的表现如下:
- 在简单打印表达式(SPE)测试集上,模型展示了极高的BLEU分数,达到了0.926,显示出模型在处理简单情况下的强大能力。
- 对于复杂打印表达式(CPE)和屏幕捕获表达式(SCE),尽管这些场景更加复杂和嘈杂,模型的BLEU分数分别为0.790和0.545,表明模型具备处理复杂场景的能力。
- 在手写表达式(HWE)测试集上,模型也表现出良好的识别效果,BLEU分数为0.373。
2. 分析
- 数据集的多样性与质量:UniMER-1M的多样化和高质量训练数据为模型提供了充分的学习资源,这是模型能够在各种测试集上表现出色的关键因素之一。
- 图像增强技术:在训练过程中应用的图像增强技术,如图像膨胀、侵蚀和天气噪声模拟等,有效地提高了模型对现实世界图像变化的适应能力,这在SCE测试集上的表现尤为明显,BLEU分数提高了2.50%。
- 长度感知模块(LAM):LAM的加入显著提升了模型对长公式的处理能力,尤其是在复杂的CPE测试集上,BLEU分数提高了2%。
总体来看,UniMERNet模型在各种数学表达式识别任务中表现出色,特别是在处理复杂和多样化的表达式方面显示了其强大的潜力和实用价值。未来的工作将进一步优化模型架构和训练流程,以提高模型的准确性和鲁棒性。
与现有技术的比较
1. 基于机器学习的方法
在数学表达式识别(MER)的早期研究中,基于机器学习的方法主要依赖于手工特征和传统的模式识别技术。这些方法虽然在处理简单的数学表达式时表现尚可,但在复杂表达式和实际应用场景中的表现往往受限,特别是在处理包含噪声和扭曲的图像时。
2. 基于深度学习的方法
随着深度学习技术的发展,基于卷积神经网络(CNN)和Transformer的方法逐渐成为MER领域的主流。这些方法通过学习大量数据中的深层特征,显著提高了对复杂数学表达式的识别能力。尤其是Transformer基模型,因其强大的序列建模能力,在处理长公式和复杂结构时表现出色。
3. UniMERNet与现有技术的比较
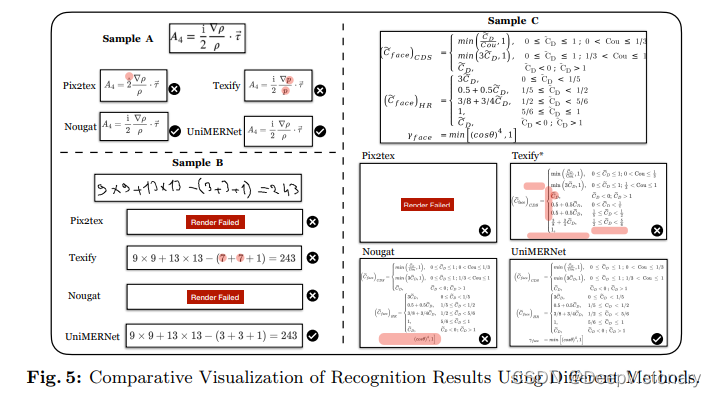
UniMERNet模型采用了创新的长度感知模块(LAM),这一设计使得模型能够在预测前获取表达式的长度信息,从而更准确地生成与输入图像视觉特征相匹配的数学表达式。此外,通过图像增强技术的应用,UniMERNet在真实世界的应用场景中表现出了更高的鲁棒性和适应性。在UniMER-Test基准测试中,UniMERNet在各种复杂场景下均显著优于现有的主流MER模型,包括在嘈杂背景和手写表达式的识别上。
总结与未来展望
本研究通过引入UniMER数据集和UniMERNet模型,为数学表达式识别(MER)领域提供了新的研究方向和技术基准。UniMER数据集的多样性和规模,为模型训练和评估提供了丰富的资源,而UniMERNet模型的设计则针对实际应用中的复杂性和多样性进行了优化。
未来的研究可以在以下几个方向进行深入:
- 模型融合与优化:探索将UniMERNet与大型视觉-语言模型(LVLMs)融合的可能性,以进一步提升模型在整体文档理解上的性能。
- 算法创新:继续优化模型结构和学习算法,特别是在处理极端复杂或极端长的数学表达式时的性能。
- 应用扩展:将MER技术应用于更广泛的场景,如智能教育、科学文献分析等,推动相关技术的商业化和实用化。
总之,UniMERNet的提出标志着MER研究向更高准确性、更强鲁棒性迈进了一大步,未来的研究将进一步推动这一领域的发展。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!















 3032
3032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









