







【问题描述】
从file_in.csv文件中读取各部门职工薪资数据,计算各个部门平均薪资,并写入file_out.csv文件中。
【输入形式】
保存职工薪资数据文件file_in.csv位于当前目录下(注意:程序中使用open()函数打开文件时,文件位置描述只写文件名和扩展名,比如open(“file_in.csv”,“r”))。
file_in.csv
【输出形式】
将各个部门平均薪资写入到file_out.csv文件中,每个部门数据单独占一行。
【样例输入】
假设文件file_in.csv中部分内容为:
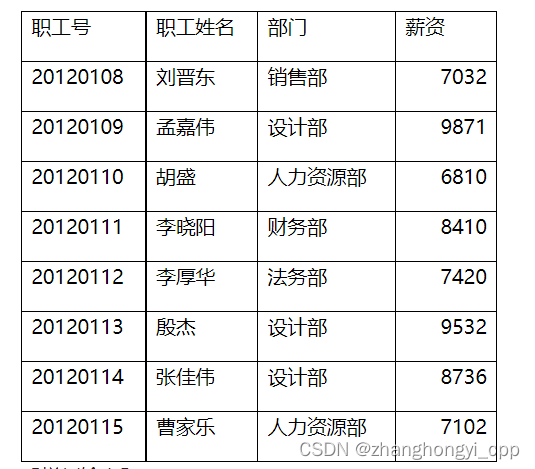
【样例输出】
file_out.csv中内容为:
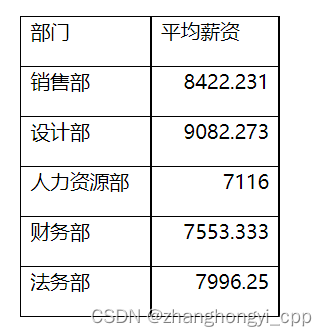
import csv
data = [["部门", "平均薪资"],["销售部", 8422.23076923077],["设计部", 9082.272727272728],["人力资源部", 7116.0],["财务部", 7553.333333333333],["法务部", 7996.25]]
with open('file_out.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
for row in data:
writer.writerow(row)
#with open("file_in.csv","r",encoding="utf-8")as f:
# b=f.read().split("\n")
# c = []
# d = {}
# for j in b:
# c.append(j.split(","))
# for i in c:
# if i[3] == "薪资":
# continue
# if i[2] in d.keys():
# d[i[2]][0] += int(i[3])
# d[i[2]][1] += 1
# else:
# d[i[2]] = []
# d[i[2]].append(int(i[3]))
# d[i[2]].append(1)
#for c in d.keys():
# d[c][0] = d[c][0] / d[c][1]
#with open('file_out.csv', 'w', encoding='gbk', newline='') as e:
# writer = csv.writer(e)
# writer.writerow(['部门', '平均薪资'])
#
# for key, value in d.items():
# writer.writerow([key, value[0]])

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









