







 本文深入介绍了GPU编程,特别是Ogre框架中的可编程流水线,包括固定功能流水线与可编程流水线的区别,以及GPU的渲染流程。详细阐述了顶点着色器和片段着色器的工作原理,包括顶点坐标变换、光照计算、裁剪、光栅化和像素颜色计算。通过示例展示了顶点和片段着色程序的定义、声明及Cg和HLSL语言的使用。最后,讨论了如何在应用程序中向着色器传递参数,实现更复杂的操作。
本文深入介绍了GPU编程,特别是Ogre框架中的可编程流水线,包括固定功能流水线与可编程流水线的区别,以及GPU的渲染流程。详细阐述了顶点着色器和片段着色器的工作原理,包括顶点坐标变换、光照计算、裁剪、光栅化和像素颜色计算。通过示例展示了顶点和片段着色程序的定义、声明及Cg和HLSL语言的使用。最后,讨论了如何在应用程序中向着色器传递参数,实现更复杂的操作。
从本章开始,将进入可编程流水线的学习。一般在图形渲染时可以通过两种途径来实现,一种称为固定功能流水线(Fixed Function Pipeline),另一种就是从本章开始要介绍的可编程流水线(Programmable Pipeline),使用可编程流水线技术进行的程序设计我们也可以称为GPU编程。
在前面的示例程序中我们所采用的方法都是固定功能流水线,当我们使用固定功能流水线时,我们通常是在程序中通过相应函数调用来设置不同的渲染状态。而使用可编程流水线技术,我们可以在源程序之外,编写另外的程序代码,直接操作顶点或像素,这样可以大大提高程序的灵活性。
16.1 GPU 图形绘制管线
首先,我们先来了解一下GPU渲染流程。图形绘制管线描述了GPU的渲染流程,即“给定视点、三维物体、光源、照明模式和纹理等元素,如何绘制一幅二维图像”。在计算机图形学中,通常将图形绘制管线分为三个主要阶段:应用程序阶段、几何阶段、光栅阶段。
应用程序阶段,使用高级编程语言(如C、C++、Java等)进行开发,主要和CPU、内存打交道,诸如碰撞检测、场景图建立、空间八叉树更新、视锥裁剪等都在此阶段执行。在该阶段的末端,几何体数据(顶点坐标、法向量、纹理坐标、纹理等)通过数据总线传送到图形硬件。
几何阶段,主要负责顶点坐标变换、光照、裁剪、投影以及屏幕映射,该阶段基于GPU进行运算,在该阶段的末端得到了经过变换和投影之后的顶点坐标、颜色以及纹理坐标。
光栅阶段,基于几何阶段的输出数据,为像素正确配色,以便绘制完整图像,该阶段进行的都是单个像素的操作,每个像素的信息存储在颜色缓冲器或帧缓冲器中。
值得注意的是:光照计算属于几何阶段,因为光照计算涉及视点、光源和物体的世界坐标,所以通常放在世界坐标系中进行计算;而雾化以及涉及物体透明度的计算属于光栅化阶段,因为上述两种计算都需要深度值信息(Z值),而深度值是在几何阶段中计算,并传递到光栅阶段的。
应用程序阶段我们一直在使用,相信我们都已经比较熟悉,下面我们具体阐述一下从几何阶段到光栅化阶段的流程。
几何阶段
几何阶段的主要工作是“变换三维顶点坐标”和“光照计算”,由于输入到计算机中的是一系列三维坐标点,但是我们最终需要看到的是从视点出发观察到的显示在二维屏幕上的点。一般情况下,GPU帮我们自动完成了这个转换。而基于GPU的顶点程序为开发人员提供了控制顶点坐标空间转换的方法。
根据顶点坐标变换的先后顺序,主要有如下几个坐标空间(或者说坐标类型):Object Space(模型坐标空间);World Space(世界坐标空间);Eye Space(观察坐标空间);Clip and Project Space(屏幕坐标空间)。下图中表述了GPU的整个处理流程,其中茶色区域所展示的就是顶点坐标空间的变化流程。

从object space 到world space
Object Space Coordinate就是模型文件中的顶点值,这些值是在模型建模时得到的,例如,用3DMAX建立一个球体模型并导出为.max文件,这个文件中包含的数据就是Object Space Coordinate,它与其它物体没有任何参照关系。而无论在现实世界,还是在计算机的虚拟空间中,物体都必须和一个固定的坐标原点进行参照才能确定自己所在的位置,这就是World Space Coordinate的实际意义所在。
毫无疑问,我们将一个模型导入计算机后,就应该给它一个相对于坐标原点的位置,那么这个位置就是World Space Coordinate,从Object Space Coordinate到World Space Coordinate的变换过程由一个四阶矩阵控制,通常称之为World Matrix。
光照计算通常是在世界坐标空间中进行的,这也符合人类的生活常识。当然,也可以在Eye Coordinate Space中得到相同的光照效果,因为,在同一观察空间中物体之间的相对关系是保存不变的。
需要高度注意的是:顶点法向量在模型文件中属于Object Space,在GPU的顶点程序中必须将法向量转换到World Space中才能使用,如同必须将顶点坐标从Object Space转换到World Space中一样,但两者的转换矩阵是不同的,准确的说,法向量从Object Space到World Space的转换矩阵是World Matrix的转置矩阵的逆矩阵(参阅潘李亮的3D变换中法向量变换矩阵的推导一文),可以阅读电子工业出版社的《计算机图形学(第二版)》第11 章,进一步了解三维顶点变换具体的计算方法,如果对矩阵运算感到陌生,则有必要复习一下线性代数。
从world space 到eye space
每个人都是从各自的视点出发观察这个世界,无论是主观世界还是客观世界。同样,在计算机中每次只能从唯一的视角出发渲染物体。在游戏中,都会提供视点漫游的功能,屏幕显示的内容随着视点的变换而变换。这是因为GPU将物体顶点坐标从World Space转换到了Eye Space。
所谓Eye Space,即以camera(视点或相机)为原点,由视线方向、视角和远近屏幕,共同组成一个梯形体的三维空间,称之为viewing frustum(视锥),如下图所示,近平面,是梯形体较小的矩形面,作为投影平面,远平面是梯形体较大的矩形,在这个梯形体中的所有顶点数据是可见的,而超过这个梯形体之外的场景数据,会被视点去除(Frustum Culling,也称之为视锥裁剪)。

从eye space 到project andclip space
一旦顶点坐标被转换到Eye Space中,就需要判断哪些点是视点可见的。位于viewing frustum梯形体以内的顶点,被认定为可见,而超出这个梯形体之外的场景数据会被视点去除(Frustum Culling,也称之为视锥裁剪)。这一步通常称之为“clip(裁剪)”,识别指定区域内或区域外的图形部分的过程称之为裁剪算法。
光栅化阶段
光栅化:决定哪些像素被集合图元覆盖的过程,经过上面诸多坐标转换之后,现在我们得到了每个点的屏幕坐标值,也知道我们需要绘制的图元(点、线、面)。但此时还存在两个问题:点的屏幕坐标值是浮点数,但像素都是由整数点来表示的,如何确定屏幕坐标值所对应的像素?在屏幕上需要绘制的有点、线、面,如何根据两个已经确定位置的两个像素点绘制一条线段,如何根据已经确定了位置的三个像素点绘制了一个三角形面片?
对于第一个问题,“绘制的位置只能接近两指定端点间的实际线段位置,例如,一条线段的位置是(10.48,20.51),转换为像素位置则是(10,21)”。
对于第二个问题,涉及到具体的画线算法,以及区域图元填充算法。通常的画线算法有DDA 算法、Bresenham 画线算法;区域图元填充算法有,扫描线多边形填充算法、边界填充算法等,具体请参阅计算机图形学中的相关内容。
这个过程结束之后,顶点以及绘制图元(线、面)已经对应到像素。下面阐述的是“如何处理像素,即:给像素赋予颜色值”。
Pixel Operation
Pixel operation 又称为Raster Operation,是在更新帧缓存之前,执行最后一系列针对每个片段的操作,其目的是:计算出每个像素的颜色值。在这个阶段,被遮挡面通过一个被称为深度测的过程而消除。总体来讲Pixel Operation主要包括:消除遮挡面、纹理操作(也就是根据像素的纹理坐标,查询对应的纹理值)、Blending(混色)、Filtering(滤波或者滤镜),该阶段之后,像素的颜色值被写入帧缓存中。下面是像素操作的流程:
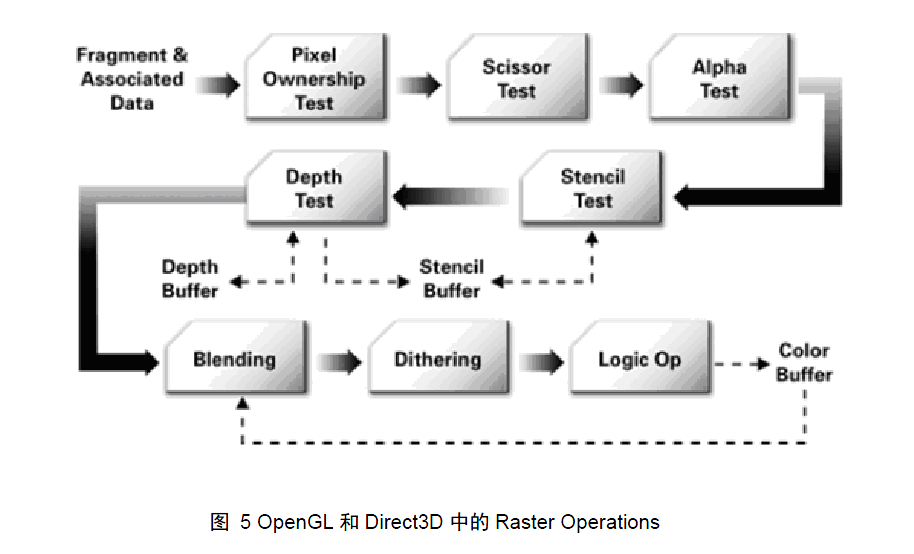
| 笔者注: 前面这些陆陆续续向大家介绍了GPU图形绘制管线的一下知识,图形绘制管线是GPU编程的基础,事实上顶点着色程序和片段着色程序正在按照图形绘制管线而划分的,由于本书并不是一本介绍计算机图形学的书籍,所以关于计算机图形学里的很多内容我们不可能在这里面面俱到都给大家讲详细,读者朋友如果想深入学习的话还需要多多涉猎计算机图形书籍学习相关知识,这对我们今后对整个图形渲染流程架构的理解十分有帮助。 |
一般可编程流水线都分为可编程顶点渲染(programmable vertexshader)流水线和可编程像素渲染(programmable pixel shader)流水线,简称顶点渲染(vertex shader)和像素渲染(pixel shader),它们取代了固定功能流水线中的顶点处理流水线(顶点坐标变换、光照、纹理坐标变换)以及部分像素光栅化处理过程。对每一种三维数据模型,图形程序设计人员都可以对它定义特定的顶点坐标变换和光照计算程序以及像素渲染方法,应用程序最终会根据每种数据特定的渲染计算方法(指定顶点渲染或像素渲染)进行渲染,从而极大地增加了三维图形程序设计的灵活性,并且针对特定数据编写的渲染程序能够有效地提高图形程序的执行效率。可编程流水线就是将顶点处理和像素处理的第一部分以可编程的方式实现,在这些具体的步骤中运行自己定义的函数,这样可以灵活的扩展图形渲染流水线的功能。
Shader Language
Shader Language,称为着色语言,在GPU编程发展的早起,shader language的提出目标是加强对图形处理算法的控制,所以对shaderlanguage的定义是:基于物体本身属性和光照条件,计算每个像素的颜色值。但随着技术的进步,目前的shaderlanguage早已经用于通用计算研究。
使用shader language编写的程序称之为shader program(着色程序)。着色程序分为两类:vertex shader program(顶点着色程序)和fragmentshader program(片段着色程序)。为了清楚的解释顶点着色和片段着色的含义,我们首先从阐述GPU上的两个组件:Programmable Vertex Processor(可编程顶点处理器,又称为顶点着色器)和Programmable Fragment Processor(可编程片段处理器,又称为片段着色器)顶点和片段处理器被分离成可编程单元,可编程顶点处理器是一个硬件单元,可以运行顶点程序,而可编程片段处理器则是一个可以运行片段程序的单元。顶点和片段处理器都拥有非常强大的并行计算能力,并且非常擅长于矩阵(不高于4 阶)计算,片段处理器还可以高速查询纹理信息。
如上所述,顶点程序运行在顶点处理器上,片段程序运行在片段处理器上,那么它们究竟控制了GPU 渲染的哪个过程。下图展示了可编程图形渲染管线。
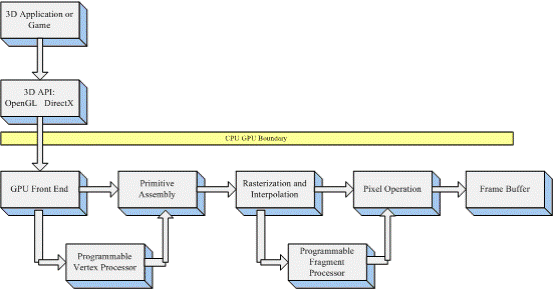
可编程图形渲染管线
对比前面的GPU 渲染管线,可以看出,顶点着色器控制顶点坐标转换过程;片段着色器控制像素颜色计算过程。这样就区分出顶点着色程序和片段着色程序的各自分工:Vertex program 负责顶点坐标变换;Fragment program负责像素颜色计算;前者的输出是后者的输入。
Vertex Shader Program
Vertex shader program(顶点着色程序)和Fragment shaderprogram(片断着色程序)分别被ProgrammableVertex Processor(可编程顶点处理器)和
Programmable Fragment Processo(可编程片断处理器)所执行。
顶点着色程序从GPU 前端模块(寄存器)中提取图元信息(顶点位置、法向量、纹理坐标等),并完成顶点坐标空间转换、法向量空间转换、光照计算等
操作,最后将计算好的数据传送到指定寄存器中;然后片断着色程序从中获取需要的数据,通常为“纹理坐标、光照信息等”,并根据这些信息以及从应用程序传
递的纹理信息(如果有的话)进行每个片断的颜色计算,最后将处理后的数据送光栅操作模块。
下图展示了在顶点着色器和像素着色器的数据处理流程。在应用程序中设定的图元信息(顶点位置坐标、颜色、纹理坐标等)传递到vertex buffer 中;纹
理信息传递到texture buffer 中。其中虚线表示目前还没有实现的数据传递。当前的顶点程序还不能处理纹理信息,纹理信息只能在片断程序中读入。
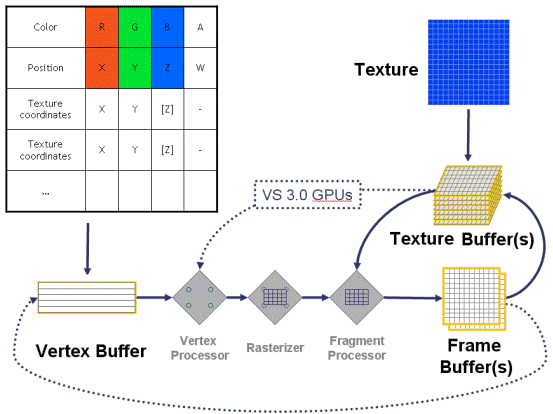
顶点着色器和像素着色器的数据处理流程
顶点着色程序与片断着色程序通常是同时存在,相互配合,前者的输出作为后者的输入。不过,也可以只有顶点着色程序。如果只有顶点着色程序,那么只对输入的顶点进行操作,而顶点内部的点则按照硬件默认的方式自动插值。例如,输入一个三角面片,顶点着色程序对其进行phong 光照计算,只计算三个顶点的光照颜色,而三角面片内部点的颜色按照硬件默认的算法(Gourand 明暗处理或者快速phong 明暗处理)进行插值,如果图形硬件比较先进,默认的处理算法较好(快速phong 明暗处理),则效果也会较好;如果图形硬件使用Gourand 明暗处理算法,则会出现马赫带效应(条带化)。而片断着色程序是对每个片断进行独立的颜色计算,并且算法由自己编写,不但可控性好,而且可以达到更好的效果。由于GPU 对数据进行并行处理,所以每个数据都会执行一次shader 程序程序。即,每个顶点数据都会执行一次顶点程序;每个片段都会执行一次片段程序。
Fragment Shader Program
片断着色程序对每个片断进行独立的颜色计算,最后输出颜色值的就是该片段最终显示的颜色。可以这样说,顶点着色程序主要进行几何方面的运算,而片段着色程序主要针对最终的颜色值进行计算。
片段着色程序还有一个突出的特点是:拥有检索纹理的能力。对于GPU 而言,纹理等价于数组,这意味着,如果要做通用计算,例如数组排序、字符串检索等,就必须使用到片段着色程序。让顶点着色器也拥有检索纹理的能力,是目前的一个研究方向。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









