









code : https://github.com/ryankiros/layer-norm
本文主要是针对 batch normalization 存在的问题 提出了 Layer Normalization 进行改进的。
这里首先来回顾一下 batch normalization :
对于前馈神经网络第 l 隐层,神经元的输入为 a, 激活函数为 f, 激活函数输出为 h。权值 w 通过 SGD学习得到。 如下面的公式所示:
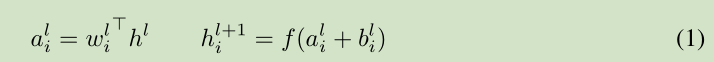
深度学习中的一个挑战就是对于上面公式中 一层的权值 w 的梯度 高度依赖于前一层神经元的输出,特别是当这些输出的改变高度相关的时候。(梯度容易受样本数据的影响,导致权值难以快速的收敛,一会向东,一会向西,走来走去,走了半天也没走多少路啊,这样走到全局最优值要走到哪天。这个问题有个名字,叫 covariate shift)。 针对此问题 [Ioffe and Szegedy, 2015] 提出了 Batch normalization 来降低这个 covariate shift 的影响。对于每个隐层的神经元,我们在所有的训练样本上归一化该神经元的输入。
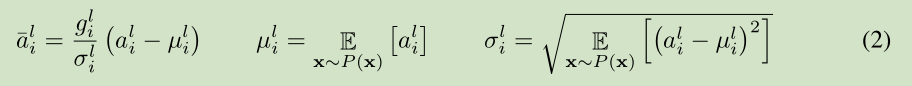
在整个训练样本上计算均值方差,然后对神经元的输入进行归一化。由于对整个训练样本计算均值方差不太有效率(对于训练来说),所以提出了 在最小训练批次上估计 均值方差。 current mini-batch 。 这个约束导致Batch normalization 难以应用于 recurrent neural networks。
3 Layer normalization
针对前面提到的 Batch normalization 的问题,我们提出了 Layer normalization。
注意到一层输出的改变会产生下一层输入的高相关性改变,特别是当使用 ReLU,其输出改变很大。那么我们可以通过固定一层神经元的输入均值和方差来降低 covariate shift 的影响。
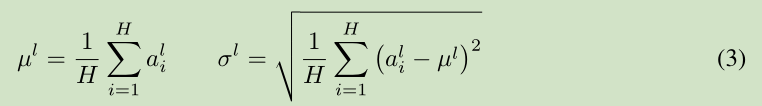
上面公式中 H 是 一层神经元的个数。这里一层网络 共享一个均值和方差,不同训练样本对应不同的均值和方差,这是和 Batch normalization 的最大区别。
Layer normalization 对于recurrent neural networks 的帮助最大。
Layer normalization 对于 Convolutional Networks 作用不是很大,后续研究可以提高其作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









