







今天对接的是Mintegral广告reporting api接口,拉取广告收益回来自己做统计。记录分享给大家
首先是文档地址,进入到Mintegral后台就能看到文档地址以及参数:
文档地址:https://cdn-adn-https.rayjump.com/cdn-adn/reporting_api/MintegralRA.html
在这里插入图片描述
接入这些第三方广告平台,流程基本上一样,拿好参数之后可以直接开始对接了,我直接贴代码出来:
const serverHost = "https://api.mintegral.com/reporting/v2/data";
$channel_date = date('Ymd', strtotime($date));
$param = [
'skey' => self::Skey,
'group_by' => 'date,app_id,platform,placement_id,unit_id',
'time' => time(),
'start' => $channel_date,
'end' => $channel_date,
'app_id' => implode(',', array_keys($third_apps))
];
$param['sign'] = md5(self::Api_Key . md5($param['time']));
$request_uri = self::serverHost . '?' . http_build_query($param);
$client = new Client();
$response = $client->request('GET', $request_uri);
$result = json_decode($response->getBody()->getContents(), true);
$model_type = [
'android' => 1,
'ios' => 2,
];
......下面是自己的逻辑代码
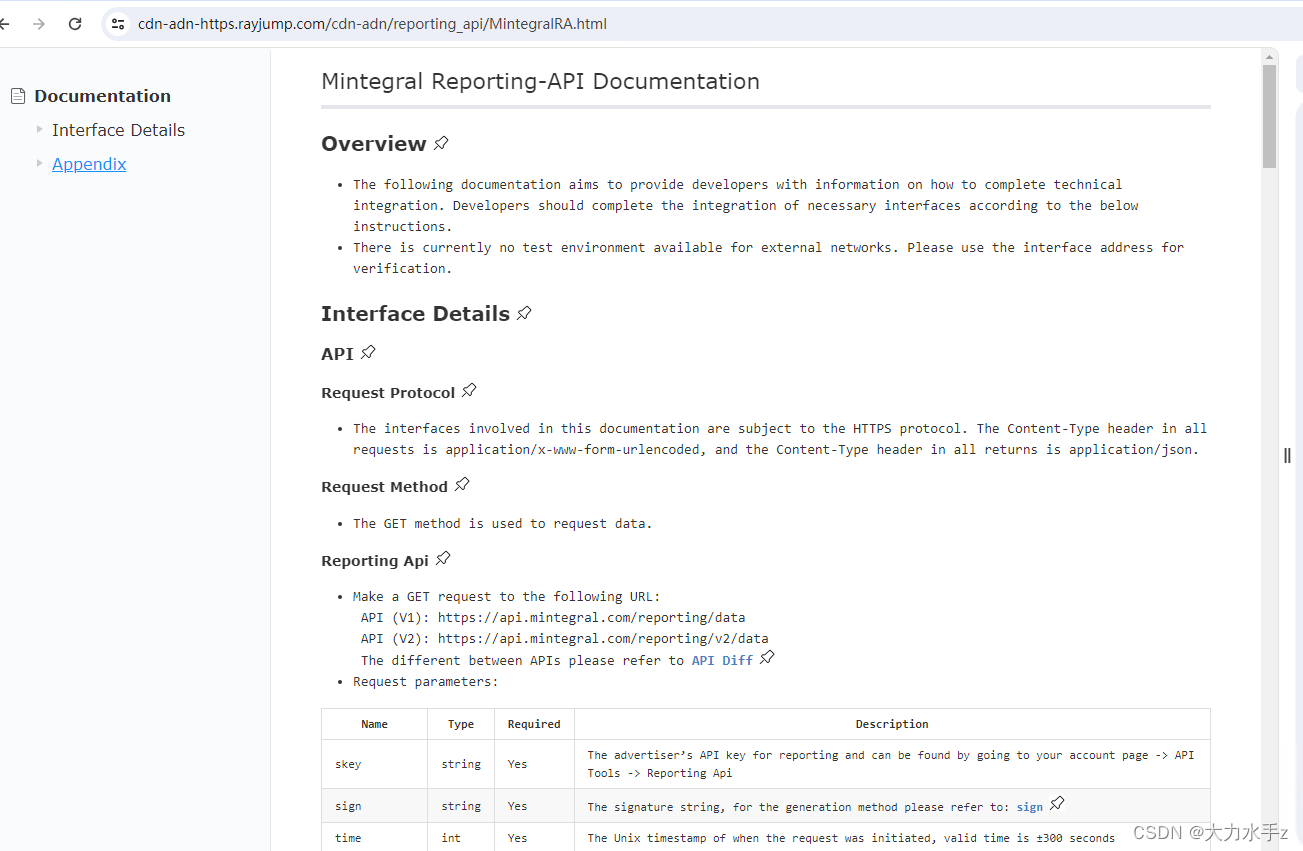
Mintegral的对接文档,感觉简单一些,基本上组装好参数之后,GET请求就能拿到相应的数据,
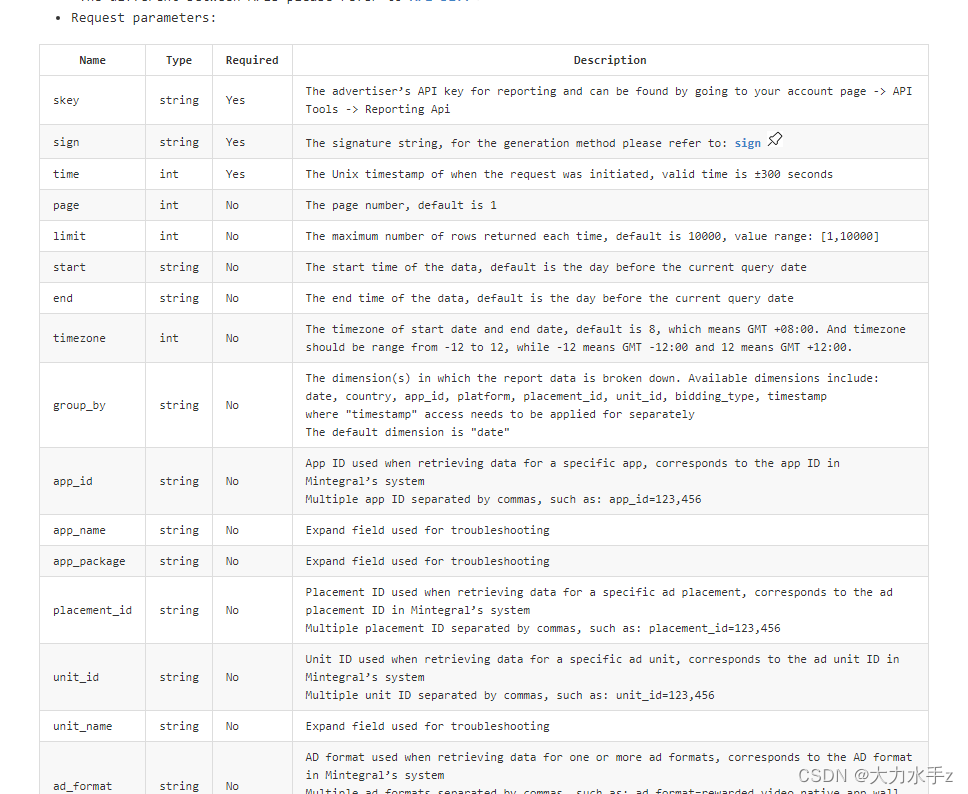
请求参数有这些,大家根据自己的需求添加
下面是请求参数,有些是必选的,有些是过滤指标,相关参数,大家根据自己需要选择
支持的参数有下面这些
$model_type = [
'android' => 1,
'ios' => 2,
];
然后就是返回设备类型,安卓返回的是android,苹果返回的是ios,大家根据自己的需要存储
以上是我对接Mintegral广告收益接口代码,欢迎大家交流学习,希望能对你有帮助。


















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











