







Session-Based Recommendation with Graph Neural Networks
1.SR-GNN
具体步骤是:
- 生成 session graph
- 生成 node embedding
- 生成 session embedding
- 进行预测
用到的技术有:gate GNN,soft-attention
1.1 摘要
**背景:**基于会话的推荐问题旨在基于匿名会话预测用户的行为。
**不足:**以前的方法将会话建模为序列,并估计除项表示外的用户表示以提出建议。虽然取得了令人满意的结果,但它们不足以获得准确的会话用户向量,并且忽略了项目的复杂转换。
**提出的方法:**为了获得准确的项目嵌入,并考虑到项目的复杂迁移,我们提出了一种新的方法,即基于会话的推荐与图神经网络,简称SR-GNN。
步骤:在该方法中,会话序列被建模为图结构数据。基于会话图,GNN可以捕捉到以往传统序列方法难以揭示的复杂项目迁移。然后使用注意力网络将每个会话表示为全局偏好和该会话当前兴趣的组合。
**结论:**在两个真实数据集上进行的大量实验表明,SR-GNN明显优于最先进的基于会话的推荐方法。
1.2 引言
1.2.1 领域中存在的问题
会话领域,有限行为建模。大多数现有的推荐系统都假定用户的个人资料和过去的活动是持续不断记录的。然而,在许多服务中,用户标识可能是未知的,只有正在进行的会话期间的用户行为历史是可用的。因此,对一个会话中的有限行为进行建模并生成相应的建议是非常重要的。相反,传统的推荐方法依赖于充分的用户-物品交互,在这种情况下产生准确的结果存在问题。
1.2.2 原有方法
1.基于马尔可夫链,一些工作基于用户的下一个行为来预测用户的下一个行为。在强独立性假设下,过去分量的独立组合限制了预测精度。
2.近年来,大部分研究将递归神经网络(rnn)应用于基于会话的推荐系统,并获得了令人满意的结果。这项工作首先提出了一种递归神经网络方法,然后通过数据增强和考虑用户行为的时间变化来增强模型。最近,NARM 设计了一个全局和局部RNN推荐器,以同时捕获用户的顺序行为和主要目的。与NARM、STAMP 相似通过采用简单的MLP网络和注意的网络,还捕获了用户的一般兴趣和当前兴趣。
1.2.3 不足
上述方法虽然取得了满意的效果,成为目前的最先进的方法,但仍有一定的局限性。首先,如果在一个会话中没有足够的用户行为,这些方法很难估计用户表示。通常,这些RNN方法的隐藏向量被视为用户表示,这样就可以基于这些表示生成推荐,例如NARM的全局推荐。然而,在基于会话的推荐系统中,会话大多是匿名且数量众多的,会话点击中涉及的用户行为通常是有限的。因此,很难准确地估计每个会话中每个用户的表示。其次,先前的研究表明,项目转换模式很重要,可以作为一个局部因素在基于会话的推荐中,但是这些方法总是建模连续项目之间的单向转换,而忽略上下文之间的转换,即会话中的其他项目。因此**,这些方法常常忽略了远距离项目之间的复杂转换。**也就是说:
1.当一个会话中用户的行为数量十分有限时,这些方法难以获取准确的用户行为表示。如当使用RNN模型时,用户行为的表示即最后一个单元的输出,作者认为只有这样并非十分准确。
2.根据先前的工作发现,物品之间的转换模式在会话推荐中是十分重要的特征,但RNN和马尔可夫过程只对相邻的两个物品的单向转移关系进行建模,而忽略了会话中其他项。
1.2.4 解决挑战:SR-GNN方法
探索项目之间丰富的转换,并生成准确的项目隐向量。
步骤:
1.对于基于会话的推荐,我们首先从历史会话序列构造有向图。
2.基于会话图,GNN能够捕获项目的过渡,并相应生成准确的项目嵌入向量,这是传统的序列方法(如基于mc的方法和基于rnn的方法)难以揭示的。
3.基于精确的项目嵌入向量,本文提出的SR-GNN构建了更可靠的会话表示,可以推断出下一个点击的项目。
下面模型图中说明了提出的SRGNN方法的工作流程。首先,所有会话序列都建模为有向会话图,其中每个会话序列都可以视为一个子图。然后,依次处理每个会话图,通过门控图神经网络获得每个图中涉及的所有节点的隐向量。之后,我们将每个会话表示为全局偏好和用户在该会话中的当前兴趣的组合,其中这些全局和局部会话嵌入向量都由节点的隐向量组成。最后,对于每个会话,我们预测每个项目成为下一个点击的概率。在真实世界的代表性数据集上进行的大量实验证明了所提出的方法对状态的有效性。
本工作的主要贡献总结如下:
• 我们将分离的会话序列建模为图结构数据,并使用图神经网络来捕获复杂的项目转换。据我们所知,它为基于会话的推荐场景的建模提供了一种新颖的视角。
• 生成基于会话的建议,我们没有依赖于用户表示,但使用会话嵌入,它可以仅仅基于每个会话中涉及的项目的隐向量来获得。
• 在真实世界数据集上进行的大量实验表明,SR-GNN明显优于最先进的方法
1.2.5 模型图

提出的SR-GNN方法的工作流程:我们将所有会话序列建模为会话图。然后,对每个会话图逐一进行处理,通过门控图神经网络得到结果节点向量。之后,每个会话都使用注意网络被表示为该会话的全局偏好和当前兴趣的组合。最后,我们预测每个会话中出现的下一个点击项目的概率。
1.3 相关工作
1.3.1 传统的推方法
- 矩阵分解:是推荐系统的通用方法。基本目标是将用户-物品评价矩阵分解为两个低秩矩阵,每个矩阵表示用户或物品的隐因素。它不太适合基于会话的推荐,因为用户偏好只由一些积极的点击提供。
- 基于项目的邻域方法:是一种自然的解决方案,其中项目相似度是根据同一会话中的共现性来计算的。这些方法在考虑项目的顺序和仅基于最后一次点击生成预测方面存在困难。
- 基于马尔可夫链的序列方法,该方法根据用户的前一个行为预测用户的下一个行为。将推荐生成视为一个顺序优化问题,采用马尔可夫决策过程(mdp)来解决该问题。通过对用户个性化概率转移矩阵的分解,FPMC 对每两个相邻点击之间的顺序行为进行了建模,并为每个序列提供了更准确的预测。然而,基于马尔可夫链的模型的主要缺点是它们独立地组合了过去的组件。这种独立性假设太强,因而限制了预测的准确性。
1.3.2 深度学习方法(神经网路RNN)
1.对于基于会话的推荐,提出了循环神经网络RNN方法,然后扩展到并行rnn 的架构,该架构可以基于点击和 点击项目的特征对会话进行建模。
2.与传统方法结合:Jannach和Ludewig(2017)将循环方法和基于邻域的方法结合在一起,混合了序列模式和共现信号。Tuan和Phuong(2017)将会话点击与内容特征(如项目描述和项目类别)结合起来,通过使用三维卷积神经网络生成推荐。此外,列表智能深度神经网络(Wu and Yan 2017)对每个会话中的有限用户行为进行建模,并使用列表智能排名模型为每个会话生成推荐。
3.此外,具有编码器-解码器架构的神经关注推荐机NARM利用RNN上的注意机制来捕捉用户的顺序行为和主要目的特征。然后,提出了使用简单MLP网络和关注网络的短期注意力优先级模型(STAMP) ,以有效地捕获用户的一般兴趣和当前兴趣。
1.3.3 图上的神经网络(GNN)
神经网络已被用于生成图结构数据的表示
- word2vec
- 无监督算法DeepWalk :基于随机行走学习图节点的表示
- 无监督网络嵌入算法LINE、node2vec
- CNN、RNN
不足:这些方法只能在无向图上实现
- GNNs:递归神经网络的形式,是对有向图进行操作的
- 门控GNN:使用门通循环单元,并使用时间反向传播(BPTT)来计算梯度。
1.4 提出的方法SR-GNN
1.4.1 第一步:符号
基于会话的推荐旨在预测用户下一步将单击哪个项目,仅基于用户当前的连续会话数据,而不访问长期首选项配置文件。
在基于会话的推荐中,让V = {v1, v2,…, vm}表示由所有会话中涉及的所有唯一项组成的集合。匿名会话序列s可以用列表s = [vs,1, vs,2,…, vs,n]按时间戳排序来表示,其中vs,i∈V表示用户在会话s中点击的一项。基于会话的推荐的目标是预测会话s的下一次点击,即序列标签vs,n+10。在基于会话的推荐模型下,对于会话s,我们输出所有可能项目的概率y^,其中向量y ^ 的元素值是相应项目的推荐分数。在y^中具有前k值的项目将成为推荐的候选项目。
1.4.2 构造会画图
每个会话序列s可以建模为一个有向图Gs = (Vs, Es)。在这个会话图中,每个节点代表一个项目vs,i∈V。每条边(vs,i−1,vs,i)∈Es表示用户在会话s中点击项vs,i后vs,i−1。由于序列中可能会重复出现多个项,因此我们为每条边分配一个归一化加权值,该加权值计算为该边的出现次数除以该边的起始节点的出线度。我们将每个项目v∈V嵌入到一个统一的嵌入空间中,节点向量v∈R d表示通过图神经网络学习到的项目v的潜在向量,其中d为维数。基于节点向量,每个会话可以用嵌入向量表示,嵌入向量由该图中使用的节点向量组成。
1.4.3 学习会话图上的项目嵌入
然后,我们给出了如何利用图神经网络获取节点的潜在向量。普通的图神经网络是由Scarselli等人(2009)提出,扩展了处理图结构数据的神经网络方法。Li等(2015)进一步引入门控循环单元,提出了门控GNN。图神经网络非常适合基于会话的推荐,因为它可以在考虑富节点连接的情况下自动提取会话图的特征。我们首先演示了会话图中节点向量的学习过程。形式上,对于图Gs的节点vs,i,更新函数如下:

其中H∈R d×2d控制权值,zs,i, rs,i分别为复位门和更新门,[v t−1 1,…, v t−1 n]是会话s中的节点向量列表,σ(·)是sigmoid函数,⊙是元素乘法算子。vi∈R d表示节点vs,i的潜在向量。连接矩阵As∈R n×2n决定了图中节点之间的通信方式,**As,i:**∈R 1×2n是节点vs,i对应的As中的两列块。
这里定义As为两个邻接矩阵A(out) s和A(in) s的连接,分别表示会话图中出边和入边的加权连接。例如,考虑一个会话s = [v1, v2, v3, v2, v4],对应的图G和矩阵a如图2所示。请注意,对于各种构造的会话图,SR-GNN可以支持不同的连接矩阵A。如果使用不同的会话图构建策略,连接矩阵a也会发生相应的变化。此外,当节点存在描述、分类信息等内容特征时,可以进一步推广该方法。具体来说,我们可以将特征与节点向量连接起来处理这些信息。
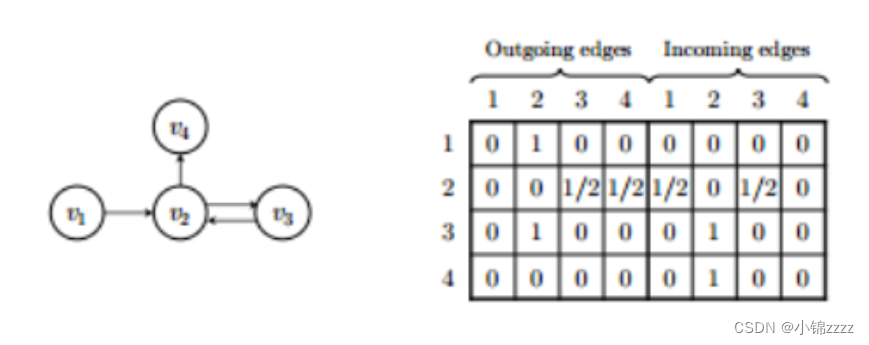
**图2:**会话图和连接矩阵a的示例
对于每个会话。相反,本文提出的SR-GNN方法没有对该向量做任何假设。相反,会话由该会话中涉及的节点直接表示。为了更好地预测用户的下一次点击,我们计划制定一种策略,将会话的长期偏好和当前兴趣结合起来,并将这种组合嵌入作为会话嵌入。
将所有的会话图输入到门控图神经网络中,得到所有节点的向量。然后,为了将每个会话表示为嵌入向量s∈R d,我们首先考虑会话s的局部嵌入sl。对于会话s = [vs,1, vs,2,…, vs,n],则局部嵌入可以简单定义为最后点击项vs,n的vn,即sl = vn。
然后,我们通过聚合所有节点向量来考虑会话图g的全局嵌入sg。考虑到这些嵌入中的信息可能具有不同的优先级,我们进一步采用软注意机制来更好地表示全局会话偏好:

其中参数q∈Rd, W1,W2∈R d×d控制项目嵌入向量的权值。
最后,我们通过对局部和全局嵌入向量的拼接进行线性变换来计算混合嵌入sh:
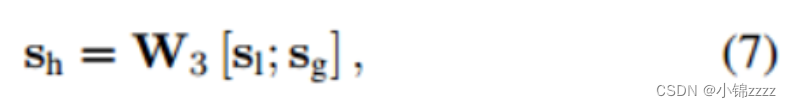
其中矩阵W3∈R d×2d将两个组合的嵌入向量压缩到隐空间Rd中。
1.4.4 提出推荐和模型训练
在获得每个会话的嵌入后,我们将每个候选项目vi∈V的嵌入vi乘以会话表示sh,计算得分z^i,其定义为:

然后我们应用一个softmax函数得到模型y的输出向量:

其中z^∈R m表示所有候选项目的推荐分数,y^∈R m表示在会话s中出现下一个点击的节点的概率。
对于每个会话图,损失函数被定义为预测值和真实值的交叉熵。他可以被表示为:
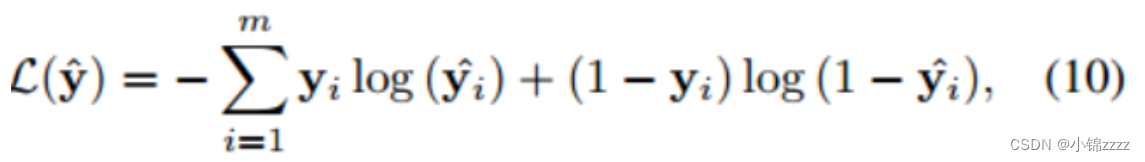
式中,y^为基真值项的单热编码向量。
最后,我们使用时间反向传播(BPTT)算法来训练所提出的SR-GNN模型。
请注意,在基于会话的推荐场景中,大多数会话的长度相对较短。因此,建议选择相对较少的训练步数,防止过拟合。
1.4 试验和分析
在本节中,我们首先描述了实验中使用的数据集、比较方法和评估指标。
然后,我们将提出的SR-GNN与其他比较方法进行了比较。最后,对不同实验条件下的SRGNN进行了详细分析。
1.4.1 数据集
我们在两个真实世界的代表性数据集(即Yoochoose2和diginetic3)上对所提出的方法进行了评估。Yoochoose数据集来自RecSys挑战2015,其中包含6个月内用户在电子商务网站的点击流。Diginetica数据集来自2016年CIKM杯,仅使用其交易数据。
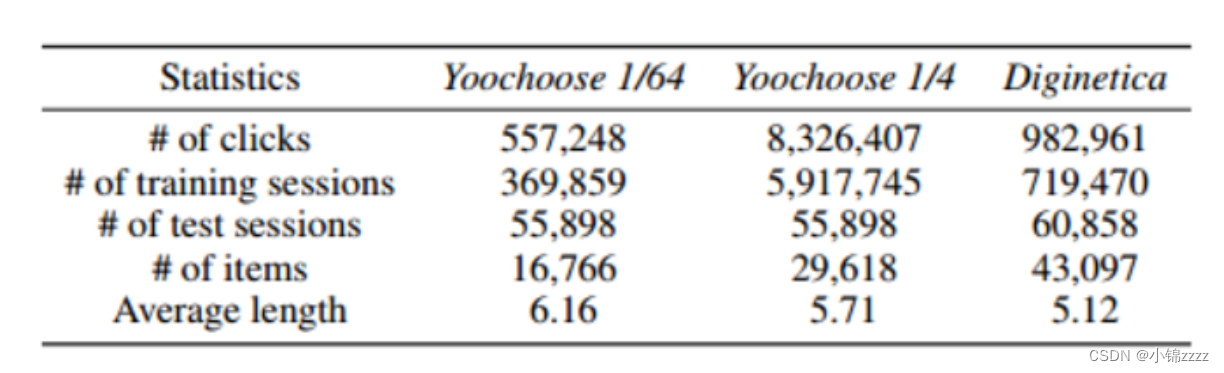
为了公平比较,我们过滤掉长度为1的所有会话和在两个数据集中出现少于5次的项目。剩下的7,981,580个会话和37,483个条目构成了Yoochoose数据集,而204,771个会话和43097个条目构成了Diginetica数据集。此外,我们通过分割输入序列来生成序列和相应的标签。具体地说,我们将随后几天的会话设置为Yoochoose的测试集,将随后几周的会话设置为Diginetiva的测试集。例如,对于一个输入会话s = [vs,1, vs,2,…, vs,n],我们生成一系列序列和标签([vs,1], vs,2),([vs,1, vs,2], vs,3),…(1, 1, 2,…), vs,n−1],vs,n),其中[vs,1, vs,2,…], vs,n−1]为生成的序列,vs,n为下一个点击项,即序列的标签。我们也使用了Yoochoose训练序列的最新分数1/64和1/4。
数据集统计汇总如表1所示:
表1:实验中使用的数据集的统计
1.4.2 BaseLine算法
为了评估所提出方法的性能,我们将其与以下代表性基线进行比较:
- POP和S-POP分别推荐训练集中和当前会话中最频繁的n个项目。
- item - knn (Sarwar et al . 2001)推荐与会话中先前点击的项目相似的项目,其中相似性定义为会话向量之间的余弦相似性。
- BPR-MF (Rendle et al . 2009)通过随机梯度下降优化成对排序目标函数。
- FPMC (Rendle, Freudenthaler, and Schmidt-Thieme 2010)是一种基于马尔可夫链的序列预测方法
- GRU4REC (Hidasi等人2016a)使用rnn对基于会话的推荐的用户序列建模。
- NARM (Li et al . 2017a)采用带有注意力机制的rnn来捕捉用户的主要目的和顺序行为。
- STAMP (Liu et al . 2018)捕获用户当前会话的一般兴趣和上次点击的当前兴趣。
1.4.3 评价指标
- **P@20(**精度)被广泛用作预测精度的度量。它表示前20个项目中正确推荐的项目的比例。
- **MRR@20(**平均倒数排名)是正确推荐项目的倒数排名的平均值。当排名超过20时,倒数排名设置为0。
MRR度量考虑推荐排名的顺序,其中MRR值大表示排名列表顶部的正确推荐。
1.4.4 参数设置
沿用以往的方法,我们为两个数据集设置潜在向量的维数d = 100。此外,我们在验证集上选择其他超参数,该验证集是训练集的10%随机子集。使用均值为0,标准差为0.1的高斯分布初始化所有参数。使用mini-batch Adam优化器来优化这些参数,其中初始学习率设置为0.001,每3个epoch后衰减0.1。此外,批大小和L2惩罚分别设置为100和10−5。
1.4.5 与基线方法的比较
为了证明所提模型的整体性能,我们将其与其他基于会话的推荐方法进行了比较。以P@20和MRR@20计算的总体性能如表2所示,最佳结果以黑体字突出显示。请注意,如(Li et al . 2017a)所述,由于初始化FPMC的内存不足,未报告Yoochoose 1/4上的性能。
表2:SR-GNN与其他基线方法在三个数据集上的性能比较

SR-GNN将分离的会话序列聚合成图结构数据。在此模型中,我们共同考虑全局会话偏好以及局部兴趣。实验结果表明,本文提出的SR-GNN方法在P@20和MRR@20这三个数据集上的性能都是最好的。验证了所提方法的有效性。
传统的POP和S-POP算法的性能相对较差。这种简单的模型仅基于重复的共出现项或连续的项进行推荐,这在基于会话的推荐场景中是有问题的。即便如此,S-POP仍然优于它的对手,如POP、BPR-MF和FPMC,这表明会话上下文信息的重要性。Item-KNN比基于马尔可夫链的FPMC有更好的效果。请注意,Item-KNN只利用项目之间的相似性,而不考虑顺序信息。这说明传统的基于mc的方法所依赖的连续项目的独立性假设是不现实的。
基于神经网络的方法,如NARM和STAMP,优于传统方法,证明了在该领域采用深度学习的力量。短期/长期记忆模型,如GRU4REC和NARM,使用循环单元来捕捉用户的一般兴趣,而STAMP通过利用最后点击的项目来改善短期记忆。这些方法显式地对用户的全局行为偏好进行建模,并考虑用户之前的操作和下一次点击之间的转换,从而比这些传统方法具有更好的性能。然而,它们的性能仍然不如所提出的方法。与NARM和STAMP等最先进的方法相比,SR-GNN进一步考虑了会话中项目之间的转换,从而将每个会话建模为一个图,这可以捕获用户点击之间更复杂和隐含的联系。而在NARM和GRU4REC中,它们显式地对每个用户建模,并通过分离的会话序列获得用户表示,忽略了项目之间可能的交互关系。因此,推荐的模型对会话行为建模更强大。
此外,SR-GNN采用软注意机制生成会话表示,自动选择最重要的项目过渡,忽略当前会话中嘈杂和无效的用户动作。相反,STAMP只使用lastclicked项和上一个操作之间的转换,这可能是不够的。其他RNN模型,如GRU4REC和NARM,在传播过程中也不能选择有影响的信息。他们使用所有之前的项目来获得一个代表用户一般兴趣的向量。当用户的行为是漫无目的的,或者他的兴趣在当前会话中迅速漂移时,传统的模型就无法应对嘈杂的会话。
1.4.6 连接方案变体的比较
所提出的SR-GNN方法在构建图中项目之间的连接关系方面具有灵活性。为了评估每个会话图中项目之间的关系,我们展示了另外两个连接变体。首先,我们将所有的会话序列聚集在一起,并将其建模为一个有向的整体项目图,下文称之为全局图。在全局图中,每个节点表示一个唯一的项,每个边表示从一个项到另一个项的有向过渡。其次,我们将一个会话中项目之间的所有高阶关系显式地建模为直接连接。综上所述,本文提出了以下两种连接方案与SR-GNN进行比较:
- 基于SR-GNN的归一化全局连接SR-GNN (SR-GNN-NGC)用从全局图中提取的边权替换连接矩阵。
- 全连接SR-GNN (SR-GNN- fc)使用布尔权重表示所有高阶关系,并将其相应的连接矩阵附加到SR-GNN的连接矩阵中。

图3:不同连接方案的性能
不同连接方案的结果如图3所示。从图中可以看出,所有三种连接方案都实现了与最先进的STAMP和NARM方法更好或几乎相同的性能,这证实了将会话建模为图的有用性。
与SR-GNN相比,对于每个会话,SR-GNN-NGC除了考虑当前会话中的项外,还考虑了其他会话的影响,从而减少了当前会话图中与节点连接度高的边的影响。这种融合方法明显影响当前会话的完整性,特别是当图中边缘的权重变化时,导致性能下降。
对于SR-GNN和SR-GNN- fc,前者仅对连续项之间的精确关系进行建模,后者进一步明确地将所有高阶关系视为直接连接。据报道,虽然两种方法的实验结果相差不大,但SR-GNN- fc的性能比SR-GNN差。如此小的结果差异表明,在大多数推荐场景中,并不是每个高阶转换都可以直接转换为直接连接,高阶项目之间的中间阶段仍然是必要的。例如,考虑到用户在浏览网站时浏览了以下页面:a→B→C,不需要中间页面B,直接在a之后推荐C页面是不合适的,因为a和C之间缺乏直接联系。
1.4.7 不同会话嵌入的比较
我们将会话嵌入策略与以下三种方法进行了比较:
(1)仅局部嵌入(SR-GNN-L),
(2)带有平均池化的全局嵌入(SR-GNN-AVG),
(3)带有注意机制的全局嵌入(SR-GNN-ATT)。
三种不同嵌入策略的结果如图4所示。

图4:不同会话表示的性能
从图中可以看出,混合嵌入方法SR-GNN在所有三个数据集上都取得了最好的结果,这验证了明确地将当前会话兴趣与长期偏好结合起来的重要性。此外,数据显示SR-GNN-ATT在三个数据集上的平均池化性能优于SR-GNN-AVG。它表明会话可能包含一些不能独立处理的噪声行为。此外,注意机制有助于从会话数据中提取重要行为以构建长期偏好。
请注意,SR-GNN的降级版本SR-GNN-L仍然优于SR-GNN-AVG,并且实现了与SR-GNN-ATT几乎相同的性能,这表明当前兴趣和长期偏好对于基于会话的推荐至关重要。
1.4.8 会话序列长度分析
我们进一步分析了不同模型处理不同长度会话的能力。为了比较,我们将Yoochoose 1/64和Diginetica的会话分成两组,其中“Short”表示会话长度小于等于5个,而“Long”表示每个会话的长度大于5个。枢轴值5是所有数据集中最接近会话平均长度的整数。属于短组和长组的会话百分比为0.701和0.299,为0.764和0.236。对于每种方法,我们在表3中报告了根据P@20评估的结果。
**表3:**使用P@20对不同会话长度的不同方法的性能进行评估
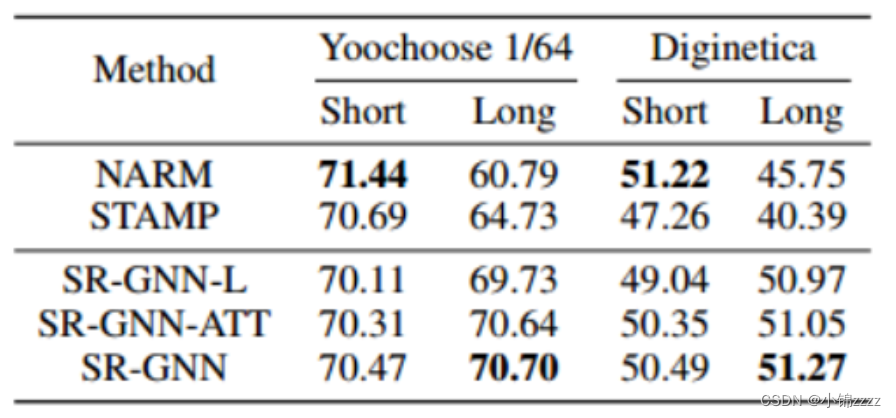
我们提出的SR-GNN及其变体在两个具有不同会话长度的数据集上运行稳定。实验证明了该方法的优越性和图神经网络在基于会话的推荐中的适应性。相反,NARM和STAMP的性能在短、长组中变化很大。STAMP根据复制的操作解释了这种差异。它采用注意机制,在获取用户表示时可以忽略复制项。与STAMP类似,NARM在短组上获得了良好的性能,但随着会话长度的增加,性能下降很快,部分原因是RNN模型难以应对长序列。
然后分析了不同会话表示下SR-GNN- l、SRGNN-ATT和SR-GNN的性能。与STAMP和NARM相比,这三种方法都取得了令人满意的效果。这可能是因为基于图神经网络的学习框架,我们的方法可以获得更精确的节点向量。
这种节点嵌入方法不仅捕获了节点的潜在特征,而且对节点连接进行了全局建模。在此基础上,SRGNN变体的性能是稳定的,而两种最先进的方法的性能在短数据集和长数据集上波动很大。此外,从表中可以看出,SR-GNN-L也可以取得很好的效果,尽管这种变体只使用了局部会话嵌入向量。这可能是因为SR-GNN-L还隐式地考虑了会话图中一阶和高阶节点的性质。图4也验证了这一结果,其中SR-GNN-L和SR-GNNATT都实现了接近最优的性能。
1.5 结论
在难以获得用户偏好和历史记录的情况下,基于会话的推荐是必不可少的。本文提出了一种新的基于会话的推荐体系结构,该体系结构将图模型用于表示会话序列。该方法不仅考虑了会话序列项目之间的复杂结构和转换,而且开发了一种将会话的长期偏好和当前兴趣相结合的策略,以更好地预测用户的下一步行动。全面的实验证明,该算法始终优于其他最先进的方法。















 5265
5265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









