






Session-based Recommendation with Graph Neural Networks
摘要
背景:基于会话的推荐问题是基于匿名会话预测用户行为。
方法:将会话建模为一个序列,并在项目表示之外估计用户表示以提出建议。
不足:忽视了项目的复杂过渡。
目的:精确获得项目嵌入,考虑项目的复杂迁移。
方法:基于会话的神经网络推荐,SR-GNN。
步骤:将会话序列建模为图结构数据(会话图)。GNN可捕获复杂项目转换(传统顺序方法难以解决)。然后利用一个注意力网络,将每个会话表示为全局偏好和当前兴趣的组成。
结论/效果:在两个数据集上实验,优于state-of-the-art方法。
引言
领域中存在的问题:会话领域,有限行为建模
推荐系统缓解了信息超载问题,成为web应用的基础。
现有方法大多假设用户资料和活动被持续记录。
然而,许多服务中用户身份可能未知,且只有正在进行的会话期间的用户行为历史是可用的。
因此,在一个会话中对有限行为进行建模并生成相应的推荐是非常重要的。
相反,传统推荐方法依赖于充分的用户-项目交互,很难产生准确结果。
问题的解决方法:基于会话的推荐方法
马尔科夫链:基于前一个行为预测用户的下一个行为;
不足:在强独立假设下,过去分量的独立组合限制了预测的准确性。
RNN及其变种:全局RNN,局部RNN,注意力
先前方法有哪些挑战:缺陷
缺陷:
1.当一个会话中用户的行为数量十分有限时,这些方法难以获取准确的用户行为表示。如当使用RNN模型时,用户行为的表示即最后一个单元的输出,作者认为只有这样并非十分准确。
2.根据先前的工作发现,物品之间的转移模式在会话推荐中是十分重要的特征,但RNN和马尔可夫过程只对相邻的两个物品的单向转移关系进行建模,而忽略了会话中其他项。
解决挑战:SR-GNN方法
探索项目之间丰富的转换,并生成准确的项目潜在向量。
图神经网络:生成图的表示
步骤;
1.对于基于会话的推荐,我们首先从历史会话序列构造有向图。
2.基于会话图,GNN能够捕获项目的转换,并相应地生成精确的项目嵌入向量,这是传统的时序方法难以揭示的,如基于mc和基于rnn的方法。
3.基于精确的项目嵌入向量,提出的SR-GNN构造更可靠的会话表示,并可以推断下一步点击的条目。
模型框架:
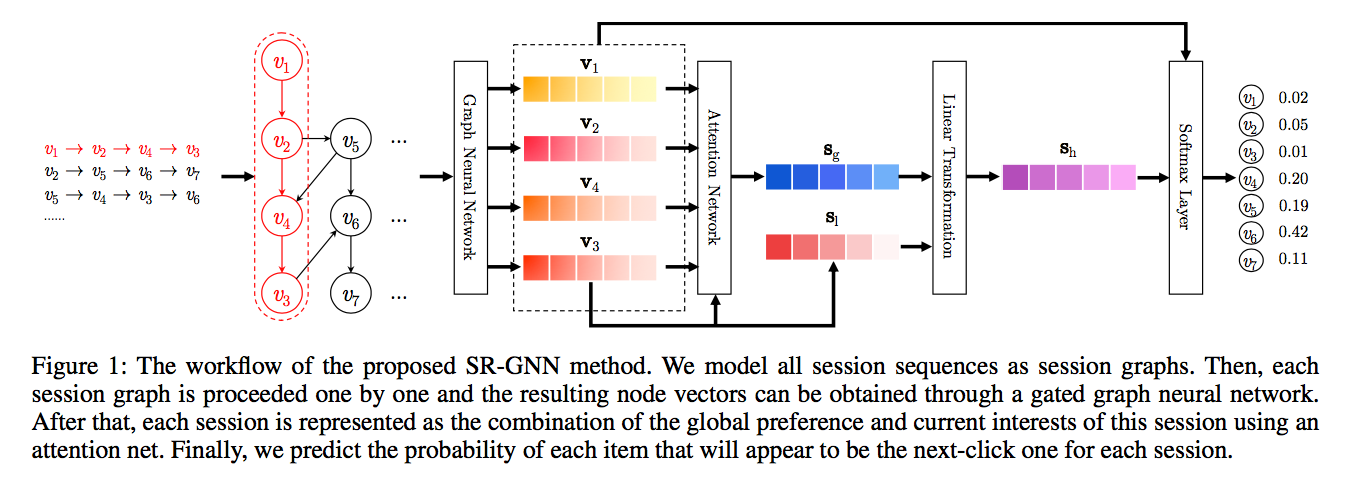
贡献:SR-GNN方法
1.将分离的会话序列建模为图结构数据,并使用图神经网络来捕获复杂的项目转换。
2.不依赖于用户表示,而是使用会话嵌入,它可以仅根据每个会话中涉及的项目的潜在向量获得。
3.效果优于state-of-art methods。
相关工作
传统推荐方法
矩阵分解:基本目标是将用户物品评价矩阵分解为两个低秩矩阵,每个低秩矩阵表示用户或物品的潜在因素。
不足:它不太适合基于会话的推荐,因为用户首选项仅由一些积极的点击提供。
基于物品的邻域方法:物品的相似性是在同一会话的共现上计算的。
不足:难以考虑项目的顺序,仅根据最后一次点击产生预测。
MCs:将推荐生成视为顺序优化问题,采用马尔可夫决策过程求解。
不足:独立性假设过于强烈,限制了预测准确性。
基于深度学习方法
RNN
扩展到并行RNN
与传统方法的结合
与注意力机制结合:获取一般兴趣+MLP和注意力:获取当前兴趣
图上的神经网络
神经网络已被用于生成图结构数据的表示
word2vec
无监督算法DeepWalk :基于随机行走学习图节点的表示
无监督网络嵌入算法LINE、node2vec
CNN、RNN
不足:这些方法只能在无向图上实现
GNNs:递归神经网络的形式,对有向图操作
门控GNN:使用门通循环单元,并使用时间反向传播(BPTT)来计算梯度。
SR-GNN方法:5步
第1步:符号
基于会话的推荐旨在预测用户下一步将单击哪个项目,仅基于用户当前的连续会话数据,而不访问长期首选项配置文件。
V
=
{
v
1
,
v
2
,
.
.
.
,
v
m
}
V=\{v_1~,v_2,...,v_m\}
V={v1 ,v2,...,vm}代表所有的物品;
s
=
{
v
s
,
1
,
v
s
,
2
,
.
.
.
,
v
s
,
n
}
s=\{v_{s,1},v_{s,2},...,v_{s,n}\}
s={vs,1,vs,2,...,vs,n}代表一个匿名会话序列;
目标:预测用户下一个要点击的物品
v
s
,
n
+
1
v_{s,n+1}
vs,n+1
输出的是所有可能项目的概率,选择top-K值为推荐候选项
第2步:子图构建 (每个会话图认为是全图的一个子图)
为每一个Session构建一个子图,并获得它对应的出度和入度矩阵。
图:

节点:

边:
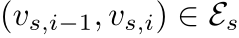
假设一个点击序列是v1->v2->v4->v3,那么它得到的子图如下图中红色部分所示:

再假设一个点击序列是v1->v2->v3->v2->v4,那么它得到的子图如下:
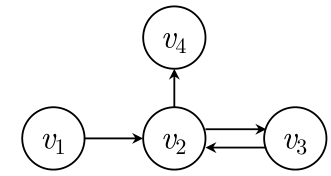
同时,我们会为每一个子图构建一个出度和入度矩阵,并对出度和入度矩阵的每一行进行归一化,如我们序列v1->v2->v3->v2->v4对应的矩阵
A
s
A_{s}
As 如下:

基于每个节点的词嵌入向量的表示形式,每个会话s就可以用嵌入向量表示:各个节点的词嵌入向量按时间顺序拼接而成。
第3步:学习会话图上物品的嵌入向量(门控GNN)
信息传播的过程。
更新函数:

步骤(1):

(1)式是用于在关系矩阵
A
s
A_{s}
As 的监督下进行不同节点间的信息传播,具体而言就是对于每个节点提取其相邻节点的关系生成隐向量输入后续的GNN中。
SRGNN是随机初始化的embedding,然后再通过权重矩阵
H
\mathbf{H}
H映射为hidden state。
使用刚才的序列v1->v2->v3->v2->v4来一点点分析输入的过程。
1)
a
s
,
i
t
a^t_{s,i}
as,it 是 t 时刻,会话 s 中第 i 个点击对应的输入()时间步的输入向量
2)
A
s
,
i
:
A_{s,i:}
As,i: 是图的邻接关系的一种表示。
A
s
A_s
As是由两个邻接矩阵,即入度和出度
A
(
i
n
)
A_(in)
A(in)和
A
(
o
u
t
)
A_(out)
A(out)矩阵拼接而成的(n, 2n)的矩阵,而
A
s
,
i
A_{s,i}
As,i可以理解成矩阵的第i行(1, 2n)。
3)
v
i
t
−
1
v^{t-1}_i
vit−1 是点击物品的序列,上一个时间步的状态向量。可以理解为序列中第 i 个物品,在训练过程中对应的嵌入向量,这个向量随着模型的训练不断变化,可以理解为隐藏层的状态,是一个d维向量。
4)H 是
d
∗
2
d
d*2d
d∗2d 的权重向量,为某条便的出现次数除以[出/入]度。也可以看作是一个分块的矩阵,可以理解为
H
=
[
H
i
n
∣
H
o
u
t
]
H=[H_{in}|H_{out}]
H=[Hin∣Hout],每一块都是
d
∗
d
d*d
d∗d的向量。
计算过程:
1)
[
v
1
t
−
1
,
.
.
.
,
v
n
t
−
1
]
[v^{t-1}_1,...,v^{t-1}_n]
[v1t−1,...,vnt−1],结果是 dn 的矩阵,转置之后是 nd 的矩阵,计作
v
t
−
1
v^{t-1}
vt−1
2)
A
s
,
i
:
v
t
−
1
H
A_{s,i:}v^{t-1}H
As,i:vt−1H相当于
V
[
A
s
,
i
:
,
i
n
v
t
−
1
H
i
n
,
A
s
,
i
:
,
o
u
t
v
t
−
1
H
o
u
t
]
V
V[A_{s,i:,in}v^{t-1}H_{in} , A_{s,i:,out}v^{t-1}H_{out}]V
V[As,i:,invt−1Hin,As,i:,outvt−1Hout]V,即拆开之后相乘再拼接,因此结果是一个1 * 2d的向量。
计算过程充分考虑了图的信息。
步骤(2)-(5):

后重置门和更新门分别决定哪些信息需要丢弃和保留。
用(4)式中的目前状态,之前的状态和重置门计算候选状态
根据(5)式用候选状态,前一状态和更新门计算表出最后的状态。
重复上述过程直至收敛,即可得到最后的各个节点的词嵌入向量。
GRU单元

整个学习的过程就是每个物品的向量独自进行循环,但是在每次输入的时候,会充分考虑图中的信息,示意图如下:

输出:节点的最终嵌入向量
第4 步:生成Session对应的嵌入向量:全局+局部
本文未考虑潜在用户的表示。相反,会话由该会话中涉及的节点直接表示。
我们计划开发一种策略,将会话的长期偏好与当前兴趣相结合,并将这种组合嵌入作为会话嵌入。
使用GNN网络对图进行信息的抽取挖掘,训练好GNN后,我们可以获取session图中每个点击物品的embedding_1向量化表示 [v1,v2,…,vn],其中每个Vi都是一个向量,对应下图红框中的结果。
 对于获得的每个物品的 向量化表示,实际上只有最后一个时刻物品是比较重要的【最后一次最能体现当前时间用户的兴趣】,我们单独将其取出为s1,而其他的信息,我们也会加以利用,但是是使用一种注意力分配的机制,添加了attention策略,根据前面几个物品跟最后一次点击的相似度,来进行注意力权值的附加,然后将这些最后一次之间的信息附加权重后加在一起,成为向量sg。
对于获得的每个物品的 向量化表示,实际上只有最后一个时刻物品是比较重要的【最后一次最能体现当前时间用户的兴趣】,我们单独将其取出为s1,而其他的信息,我们也会加以利用,但是是使用一种注意力分配的机制,添加了attention策略,根据前面几个物品跟最后一次点击的相似度,来进行注意力权值的附加,然后将这些最后一次之间的信息附加权重后加在一起,成为向量sg。

全局偏好:

最后,将s1和sg、进行横向拼接,并进行线性变换,得到
s
h
s_h
sh:

给出推荐结果及模型训练
在得到了每个会话的嵌入后,可以根据此计算出对于物品集中所有物品下一次点击的预测分数,具体来说就是通过该物品的特征嵌入和会话特征嵌入得到:

并通过一个softmax得到最终每个物品的点击概率:

损失函数是交叉熵损失函数:

最后,使用BPTT算法来训练提出的SR-GNN模型。
实验和分析
POP and S-POP:分别推荐训练集和当前时段最常出现的前n个项目
Item-KNN:在会话中推荐与之前单击的项相似的项,其中相似度定义为会话向量之间的余弦相似度。
BPR-MF:通过随机梯度下降优化两两排序的目标函数。
FPMC:是一种基于马尔可夫链的序列预测方法。
GRU4REC:用RNNs为基于会话的推荐建立用户序列模型。
NARM:使用具有注意机制的RNNs来捕捉用户的主要目的和顺序行为。
STAMP:获取用户当前会话的一般兴趣和最后一次单击的当前兴趣。
效果评判:
**P@20(精度)**被广泛用作预测精度的度量。它表示前20个项目中正确推荐的项目所占的比例。
MRR@20(**平均倒数排名)**是正确推荐项目倒数排名的平均值。当秩超过20时,倒数秩被设置为0。MRR度量考虑推荐排名的顺序,其中较大的MRR值表示正确的推荐位于排名列表的顶部。



结论
难于获得用户偏好和历史记录的情况下,基于会话的推荐是必不可少的。
本文不仅考虑了会话序列之间复杂的转移信息,还考虑了长期偏好与当前兴趣相结合,更好的预测用户下一步的行为
问题:
1.基于会话图学习节点的表示时,每个会话图中相同节点的表示应该不一样吧?
答:代码中在数据预处理时将所有会话的节点重新编号,每个session中节点的编号是相对于所有节点的。
2.文章中说的全局是指一个会话中的所有项目,还是所有项目?
答:这里的全局是指每个会话的全局。计算时是将100会话分为一组,计算一组的损失,所有组损失相加为总体损失,利用总体损失的收敛训练模型。
3.公式1包含了图的信息(邻域关系等),公式2-5体现了GRU处理向量更新。
3.如果项目是整体的,那不同会话中相同项目的编号应该一样,怎么解决的?
答:答案如2问所示。代码中的前向传播是分组进行的
4.代码中hidden部分看不太明白。
答:hidden的初始值为第一个session
6.信息的传播是怎么实现的,包括在公式中和代码中?
代码:
代码中将1000多个会话分为了13组,每组100条会话,循环计算13组会话的A,hidden;
hidden的初始值为节点的原始信息;
数据分批:generate_batch()
每批次数据获得A,items,mask,targets:get_slice()
训练函数:train_test(),循环训练每批次数据,循环过程使用forward(i)
前向传播:forward(),首先使用get_slice(i)获得批次i的信息,然后利用gnn计算hidden,获得预测分数
参考:
1.https://www.jianshu.com/p/9186b2e40178.
2.推荐系统 - SR GNN架构详解(包含图神经网络GNN和门控图神经网络GGNN的介绍).
3.代码分析:https://blog.csdn.net/hhmy77.
4.https://blog.csdn.net/weiwei935707936.
5.【论文精读】门控图神经网络GGNN及SRGNN:比2更清晰.
6.完整代码逐行笔记.
7.(推荐必看)门控图神经网络及PyTorch实现.















 5265
5265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









