







松果时序数据库将每个表、每天的数据存储在一个数据文件中,数据文件分为普通文件和压缩文件,他们的特点如下:
普通文件:支持写入,占用较多的磁盘空间;文件以页为单位进行管理,每个数据页只存储一个设备一段时间的数据,每个页固定为64KB。
压缩文件:不支持写入,数据使用两阶段压缩,占用较少的磁盘空间;数据存储到数据块中,每个数据块存储一个设备一段时间的数据,每个数据块大小不等;每个设备的数据在磁盘上连续存储,具备极高的顺序读取性能。
在松果时序数据库中,新写入的数据存储为普通文件,满足一定条件时(1.系统开启数据压缩;2.数据文件早于写入时间窗口)系统将普通文件转换为压缩文件。
本文档所有数据实例都是readings_20161115.cdat文件,文件生成过程参考博客:https://my.oschina.net/u/4204276/blog/3105248
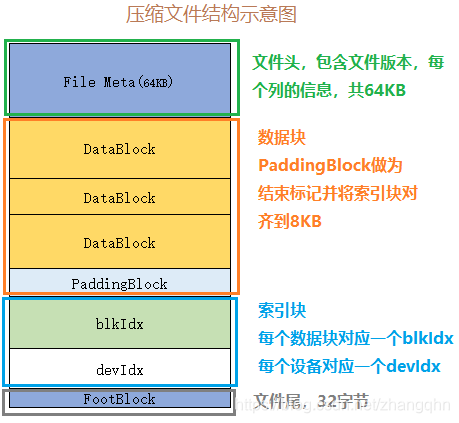
本文档详细描述松果时序数据库(PinusDB v1.3)压缩文件格式。压缩文件结构如下所示:
示例表的创建表的语句为:
create table readings
(
devid bigint,
tstamp datetime,
battery_level bigint,
battery_status string,
battery_temperature real3,
cpu_avg_1min real3,
cpu_avg_5min real3,
cpu_avg_15min real3,
mem_free bigint,
mem_used bigint,
rssi bigint
)1.文件头
文件头内容如下所示,备注:所有整数以小端序存储。
| 位置 | 大小(字节) | 描述 |
| 0 | 16 | 文件头字符串,目前版本存储字符串 "PDB COMPRESS 1" |
| 16 | 4 | 数据页大小,压缩文件未使用 |
| 20 | 4 | 字段数量 |
| 24 | 4 | 文件的天编码,即当前文件存储数据与1970-1-1之间的天数 |
| 28 | 4 | 文件类型,普通文件为1, 压缩文件为2 |
| 32 | 860 * 64 | 860个列信息,每个列包含: 列名:48字节,字段类型:4字节,填充12字节;每个列64字节 |
| 55072 | 10460 | 填充 |
| 65532 | 4 | 文件头前65532个字节的CRC |
文件头实例:


其中标记部分从上到下依次为:
0B 00 00 00: 字段数量,表示该表有11个字段
E0 42 00 00: 天编码,0x42E0 即 17120 也就是2016-11-15距离1970-1-1的天数
02 00 00 00: 文件编码,02 表示压缩文件
接下来的部分就是字段名和类型,最后是文件头的CRC。
2数据块
数据块是压缩文件中存储数据的基本单位,一个数据块存储一个设备一段时间的数据,数据内容使用zlib压缩,每个数据块大小不一。
数据块内的结构如下:
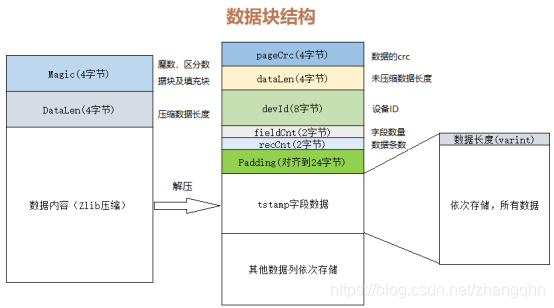
数据块结构内容
Magc: 4字节,魔数,用于区分数据块(0x7CEF82D9)和填充块(0xD9EF7C82).
DataLen: 4字节,使用zlib压缩后的数据长度。
数据内容解压后的结构
pageCrc: 4字节,整个数据的crc
dataLen: 4字节,未压缩数据的长度
devId: 8字节,设备ID
fieldCnt: 2字节,字段数量
recCnt: 数据条数
字段值存储结构
首先以varint编码存储所有数据的长度,然后依次存储所有的数据,存储方式如下:
tstamp: 由于tstamp的值递增,第一个数存储距离1970-1-1 0:0:0的毫秒数,其后存储与上一个数据的毫秒数的差值,以varint编码存储。
bool类型: 每个值占用一个bit,0表示false, 1表示true。
bigint类型:第一个数编码后存储,其后存储与上一个数的差,编码方式:先zigzag编码后varint编码。
其他类型的数据请参考源码。
实际的实例:这里以readings_20161115.cdat第一个数据页来说明。
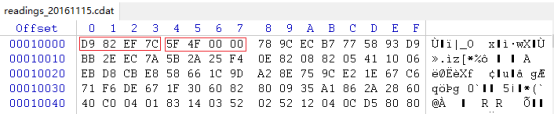
其中标记部分分别表示当前为数据块和数据块的长度(0x4F5F 即 20,319字节),接下来便是20,319字节使用zlib压缩后的数据。
下图:
上半部分为数据块解压后的前48个字节的内容;
下半部分为数据源devces_big_readings.csv 中demo000000 设备的前几条数据。
也就是下半部分的数据被编码存储到了上半部分中,截图中仅包含时间字段即tstamp。
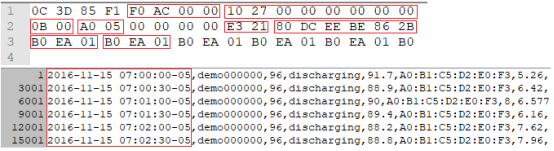
对应前述数据块结构,可知标记部分的含义如下:
F0 AC 00 00 : 未压缩的数据长度,即:44,272 也就是zlib将原始数据压缩到了一半以下。
10 27 00 00 00 00 00 00:设备ID,即:本数据库存储的设备Id为10000 的数据。
0B 00 : 表示每条数据有11个列。
A0 05: 表示这个数据页中包含的数据条数,即:本块存储 1440 条数据。
E3 21: 表示tstamp值,数据长度,以varint编码,即:接下来4323个字节存储的是1440条tstamp的值。
80 DC EE BE 86 2B: 第一个tstamp值,以varint编码,解码后为:1479211200000,表示距离1970-1-1 0:0:0 的毫秒数,转换成北京时间为:2016-11-15 20:0:0,和图下半部分第一条数据对应’2016-11-15 07:00:00-05’(注意时区)。
B0 EA 01: 表示当前值与上一个值的差,以varint编码,解码后为:30000 也就是30秒。
其他数据可以以此为参考结合代码进行分析。
压缩文件的两阶段压缩:
第一阶段:将数据以差值编码存储起来(不同数据类型对应不同的方式)。
第二阶段:将数据块进行压缩。
填充块
填充块仅块头的魔数与数据库不同,数据内容无意义。主要是将索引块对齐到8KB。
填充块也可以作为读取数据块结束的哨兵。
3 索引块和文件尾部
每个数据块对应一个blkIdx,每个设备的blkIdx按时间顺序存放在一起;
每个设备对应一个devIdx,devIdx指向该设备的blkIdx;所有的devIdx按照设备ID顺序存放。
文件尾部即压缩文件最后32字节的内容,包含设备数量,设备索引位置等信息,各部分结构如下:
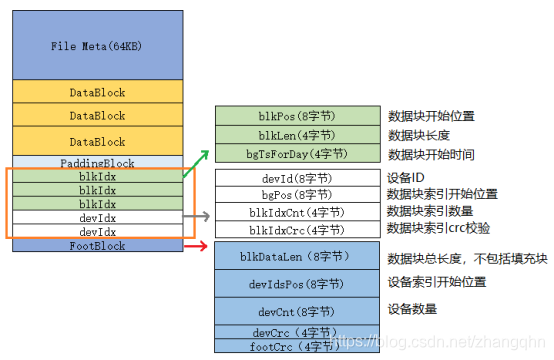
由于devId按顺序存放,查询数据时根据文件尾部的信息找到设备ID数组的开始位置和数量使用二分查找,查到指定的设备,获取该设备所有数据块索引的开始位置和数量,再次根据时间使用二分查找,获取到数据块的位置及大小。最后读取数据块并解析数据即可。
更多信息可以结合源码及生成的数据文件。

















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









