




 本文介绍了从SNE到TSNE的演进过程,并详细解析了TSNE算法的工作原理,包括其如何通过保持样本间的概率分布来实现高效的数据降维。
本文介绍了从SNE到TSNE的演进过程,并详细解析了TSNE算法的工作原理,包括其如何通过保持样本间的概率分布来实现高效的数据降维。
TSNE是由SNE衍生出的一种算法,SNE最早出现在2002年,它改变了MDS和ISOMAP中基于距离不变的思想,将高维映射到低维的同时,尽量保证相互之间的分布概率不变,SNE将高维和低维中的样本分布都看作高斯分布,而Tsne将低维中的坐标当做T分布,这样做的好处是为了让距离大的簇之间距离拉大,从而解决了拥挤问题。从SNE到TSNE之间,还有一个对称SNE,其对SNE有部分改进作用。
- SNE算法
- 对称SNE算法
- TSNE算法(***)
1、SNE
高维数据用X表示,Xi表示第i个样本,低维数据用Y表示,则高维中的分布概率矩阵P定义如下:
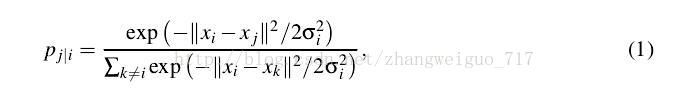
P(i,j)表示第i个样本分布在样本j周围的概率。delta是依据最大熵原理来决定,entropy=sum(pi*log(pi)),以每个样本点作为中心的delta都需要使得最后分布的熵较小,通常以log(k)为上限,k为你所决定的邻域点的个数。
低维中的分布概率矩阵计算如下:

这里我们把低维中的分布看作是均衡的,每个delta都是0.5,由此可以基本判断最后降维之后生成的分布也是一个相对均匀的分布。
随机给定一个初始化的Y,进行优化,使得Y的分布矩阵逼近X的分布矩阵。我们给定目的函数,用KL散度来定义两个不同分布之间的差距:
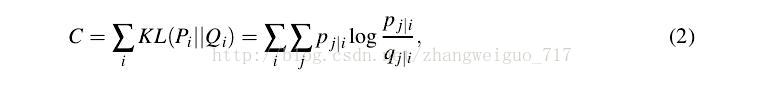
则可以计算梯度为:
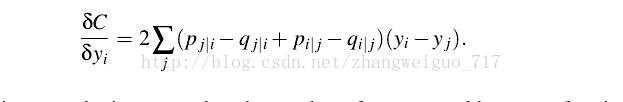
每次梯度下降的步长可设定固定或者自适应、随机等,也可以加上一个动量的梯度,初始值一般设为1e-4的随机正态分布。
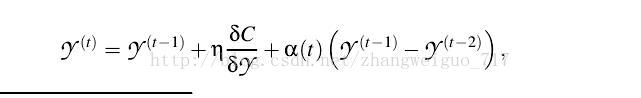
2、对称SNE
顾名思义,就是让高维和低维中的概率分布矩阵是对称的,能方便运算,但是对拥挤问题无改进。
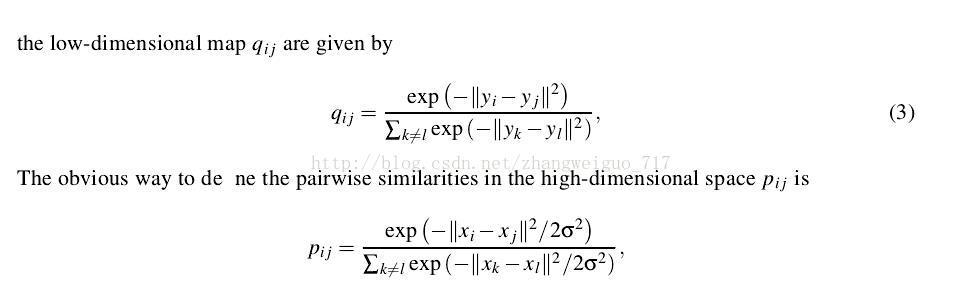
同样采用KL散度作为两个分布之间的差异标准,只是梯度有一些改变:
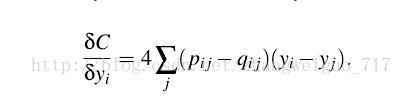
3、TSNE
TSNE对高维中的分布采用对称SNE中的做法,低维中的分布则采用更一般的T分布,也是对称的,我们可以发现sum(P)=sum(Q)=1。
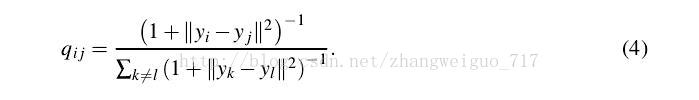
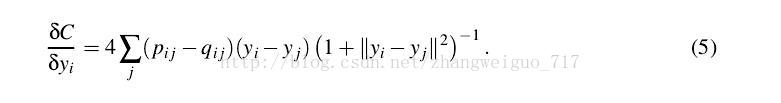
TSNE算法流程如下:

自TSNE极大改良了SNE,但它们都有一个非常通用的毛病,耗时耗力。样本较多时,构建网络及其困难,梯度下降太慢,TSNE的程序及可视化见下一篇,TSNE的改良Largevis见下下篇。

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









