









 本文介绍了NLP的下游应用,包括NLU和NLG,着重探讨了大模型在信息检索、机器问答和文本生成中的应用,如Cross-Encoder和Dual-Encoder架构,以及传统方法如BM25和神经网络方法面临的挑战。文章还提及了预训练、强化学习筛选和跨领域迁移等前沿热点。
本文介绍了NLP的下游应用,包括NLU和NLG,着重探讨了大模型在信息检索、机器问答和文本生成中的应用,如Cross-Encoder和Dual-Encoder架构,以及传统方法如BM25和神经网络方法面临的挑战。文章还提及了预训练、强化学习筛选和跨领域迁移等前沿热点。
介绍
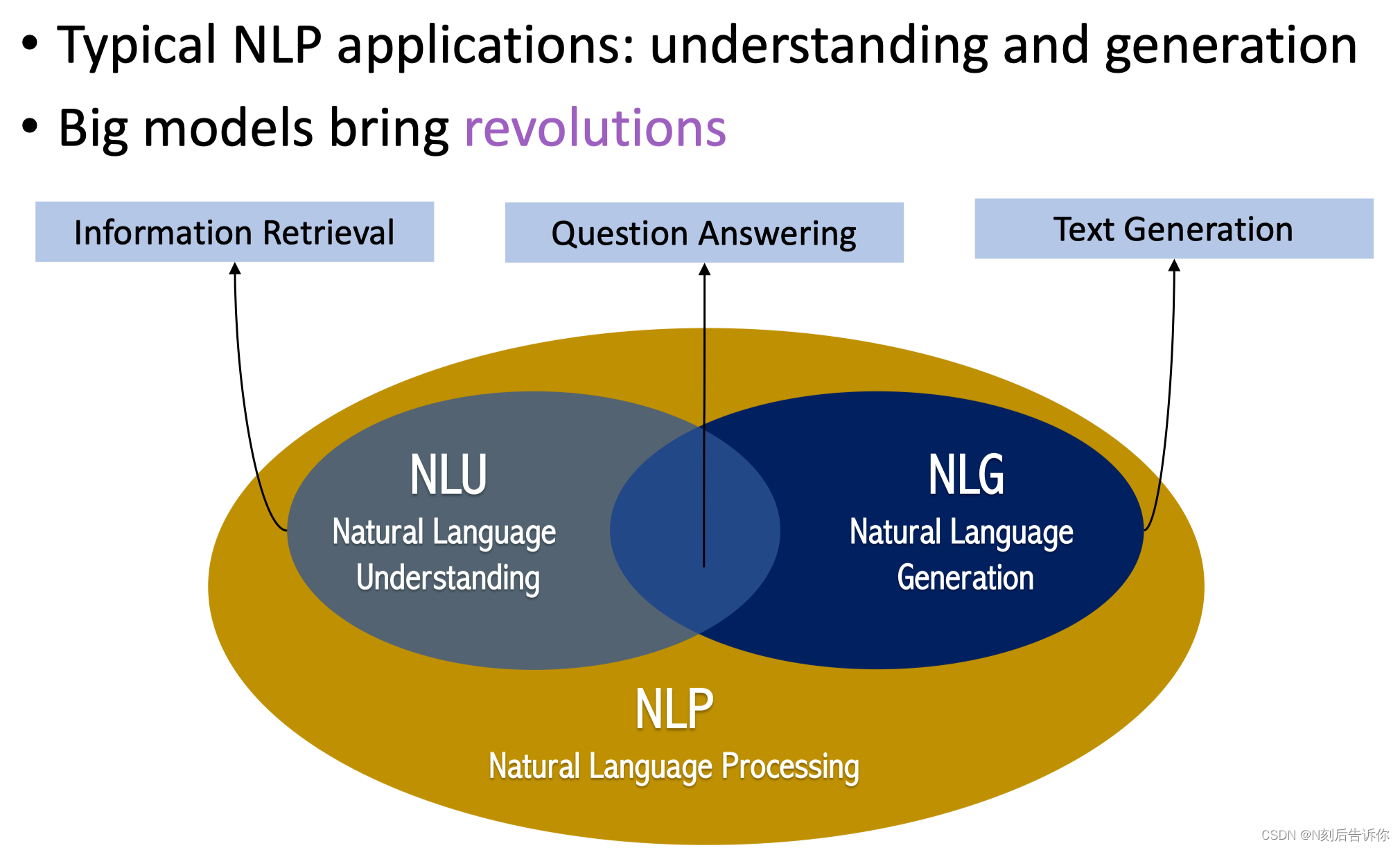
NLP的下游运用可以分为:NLU(理解)和NLG(生成)
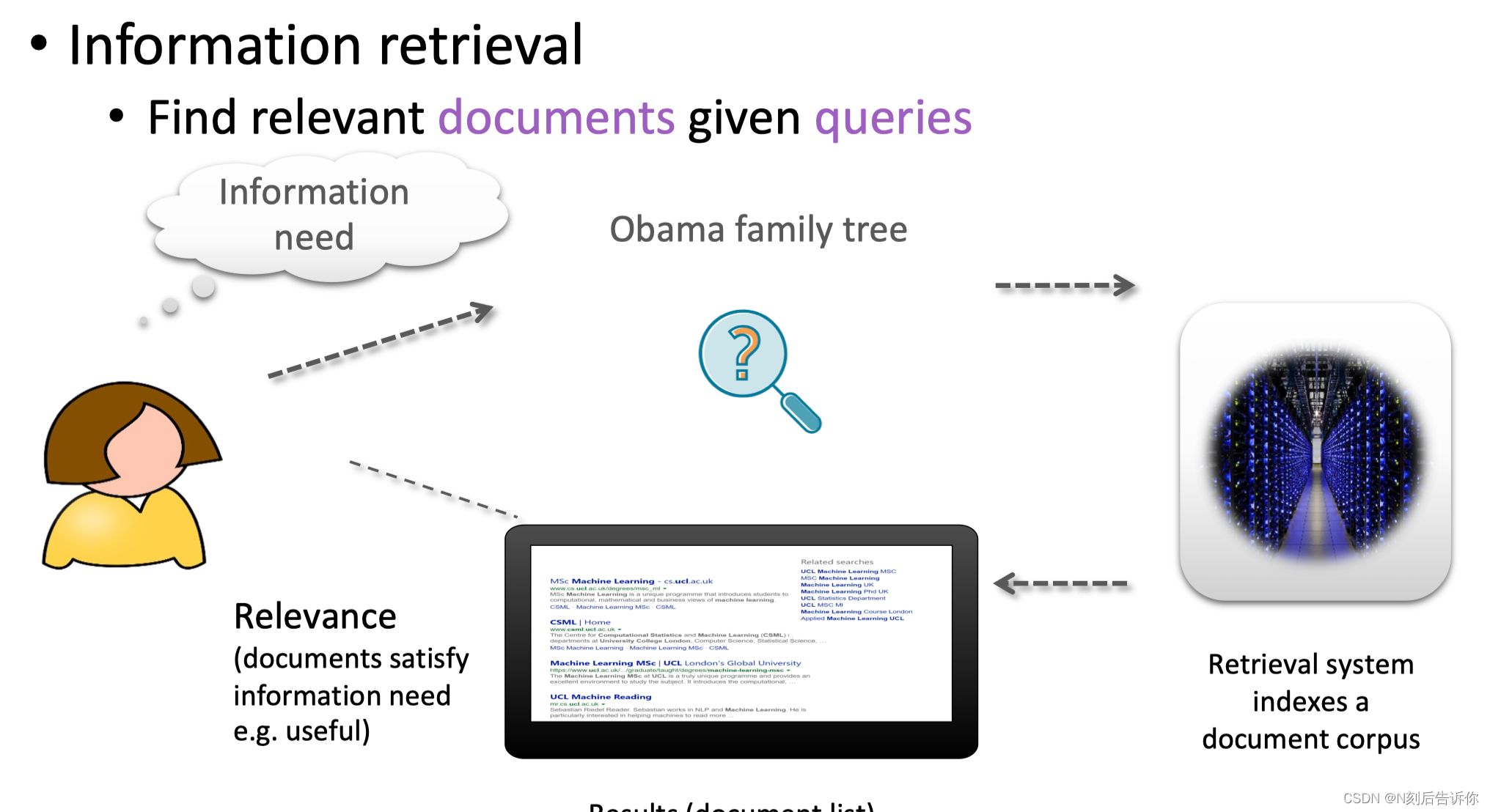
信息检索:NLU
文本生成:NLG
机器问答:NLU+NLG
大模型在信息检索

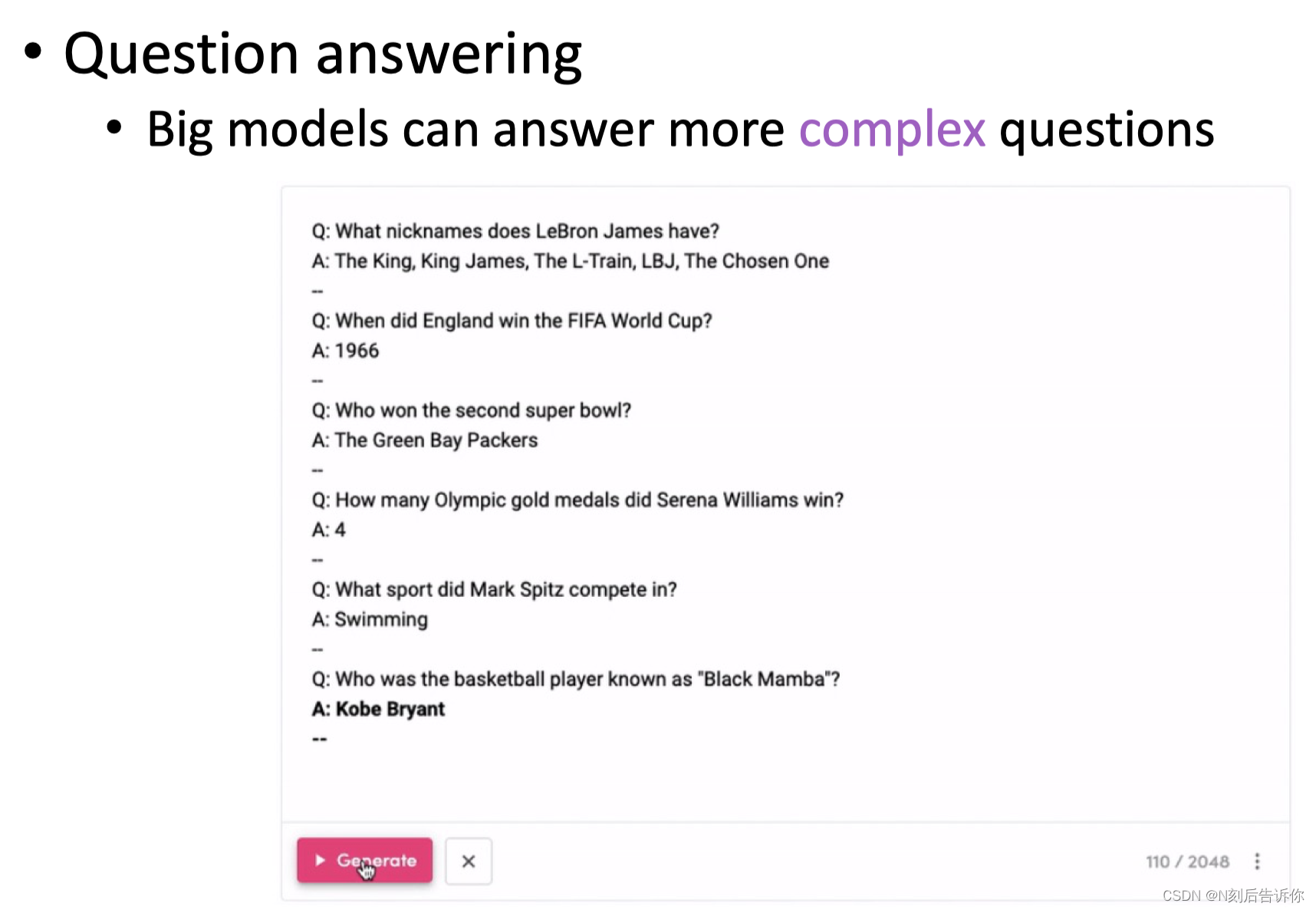
大模型在机器问答
大模型在文本生成
信息检索-Information Retrieval (IR)
背景
谷歌搜索引擎目前同时集成了文档排序和问答系统。

定义和评测
如何定义IR任务
IR系统分为两个阶段:
Retrieval阶段:对整个文档库排序后,抽回一部分相关文档的子集。主要考虑召回率。
Re-Rankink阶段:精排序

如何评测
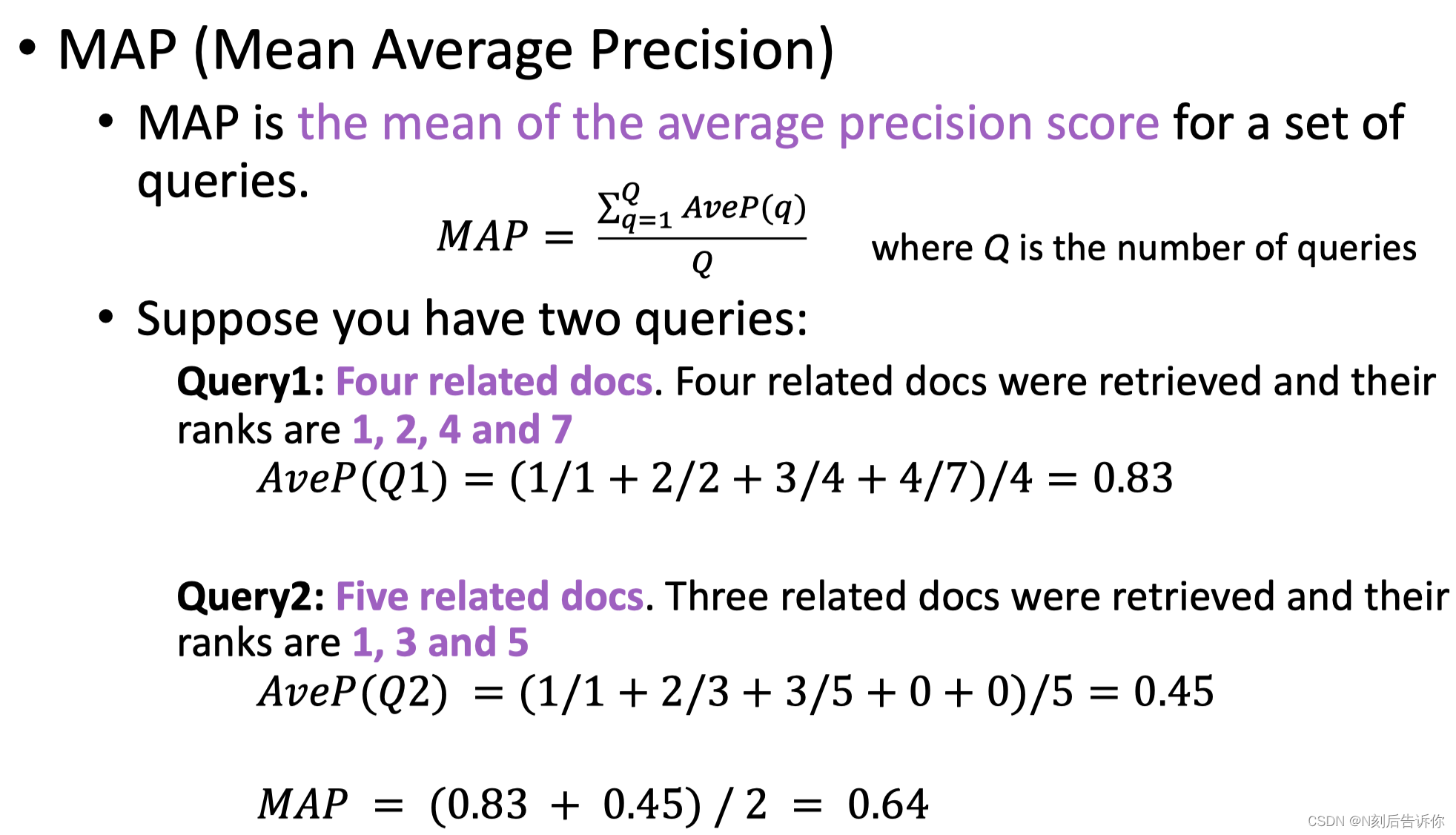
IR中常用的评价指标为MRR、MAP、NDCG
平均倒数排名-MRR
只会考虑排名最靠前的相关文档的排名

平均准确率-MAP
会考虑所有相关文档。
归一化的折损累计增益-NDCG
这个指标是商业的搜索引擎或是推荐系统中最常用的评价指标。
前两个指标抽回的文档只有相关和不相关两个等级。NDCG有更细粒度的相关等级划分。

传统方法
BM25
BM25是一种典型的基于词汇匹配的IR方法。
其中k和b是可调节的超参数。
tf是词频:query中的每个词在文档中出现的频率。
idf是逆文档的频率:评估查询中的一个词汇在所有文档中常见或稀缺的程度。例如一个查询词在所有文档中都常见,则idf分数会很低。



存在的问题-词汇失配
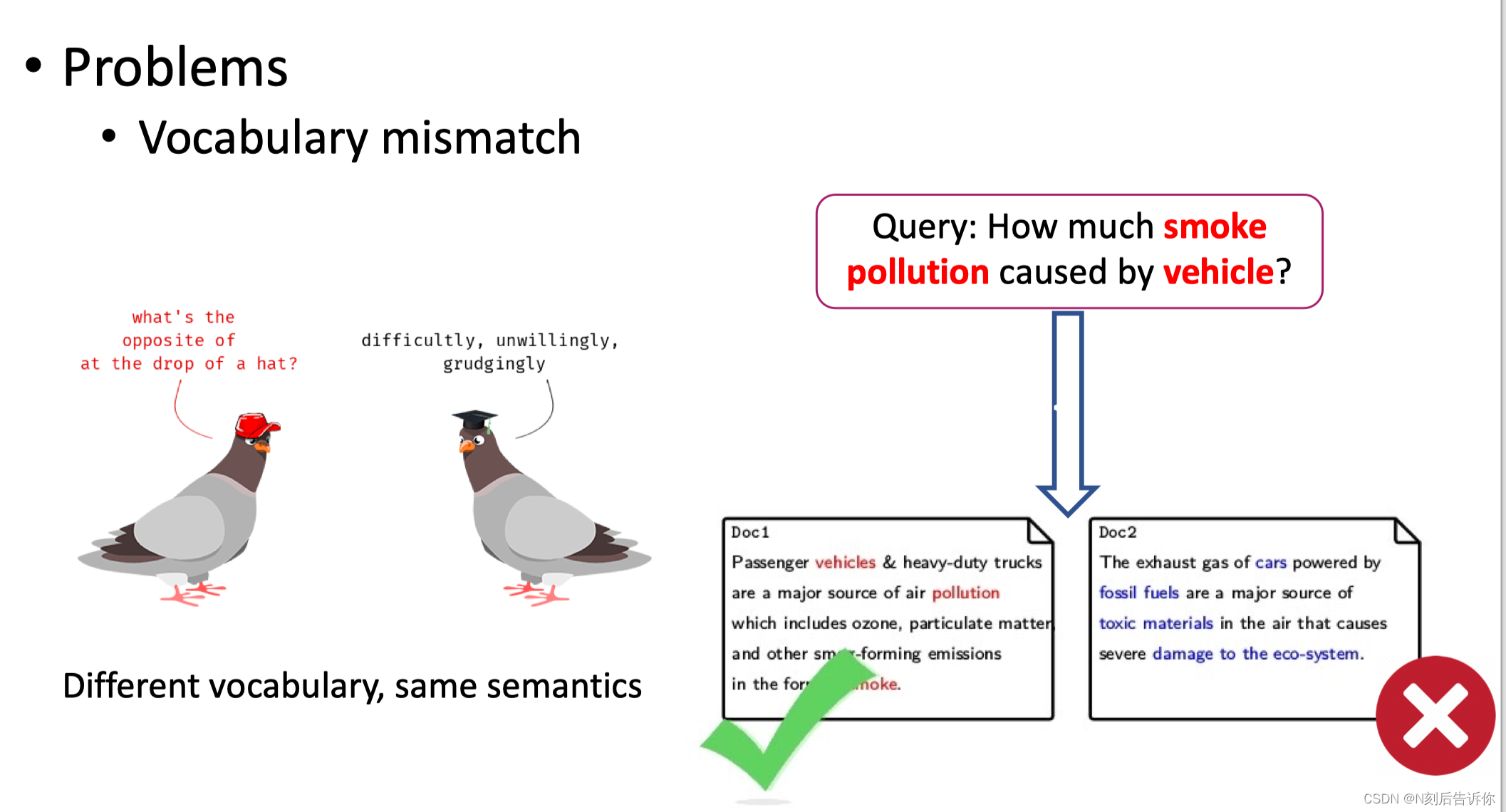
存在的问题-语义失配

神经网络方法-大模型
下面介绍两种架构:Cross-Encoder,Dual-Encoder
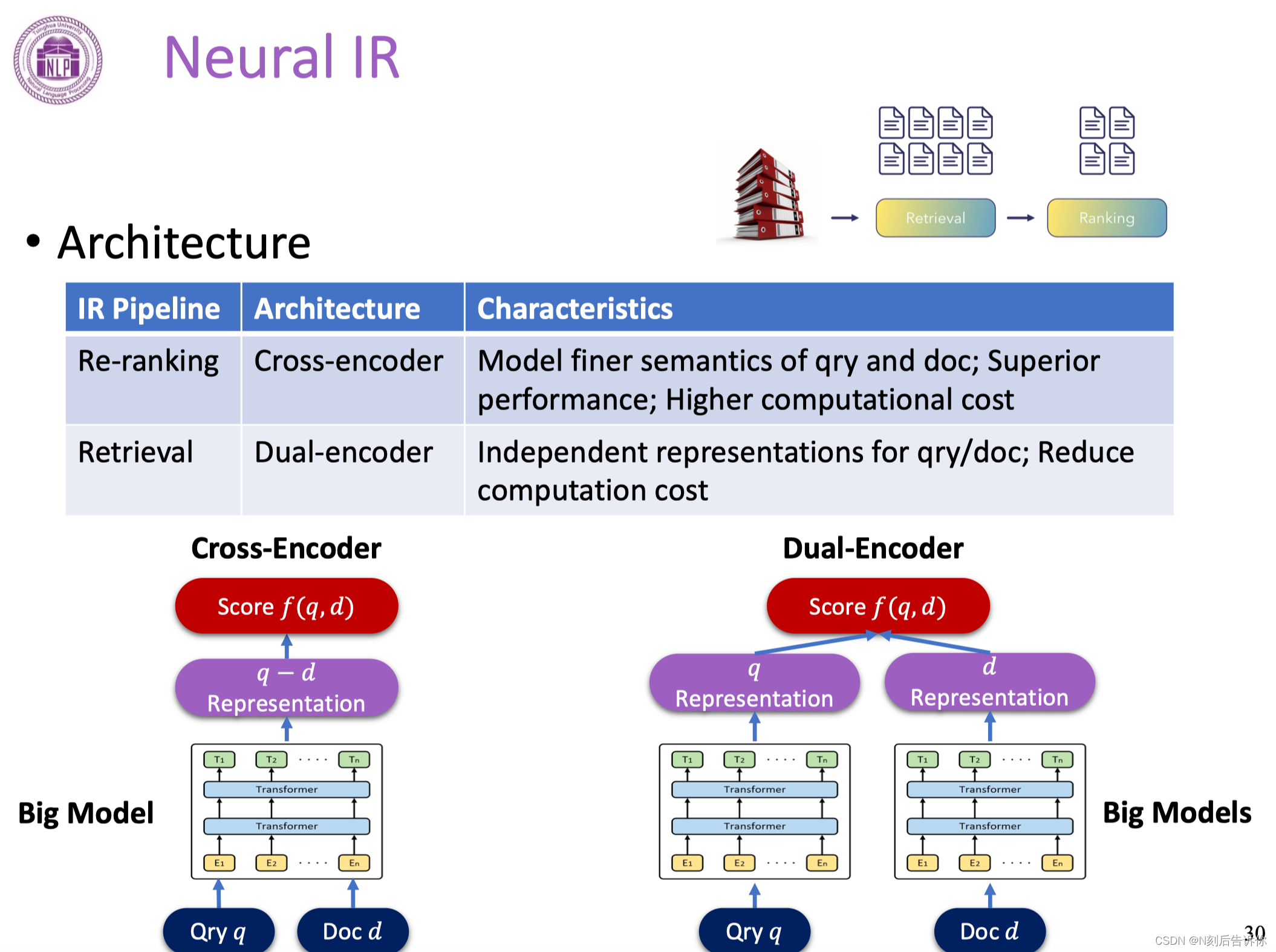
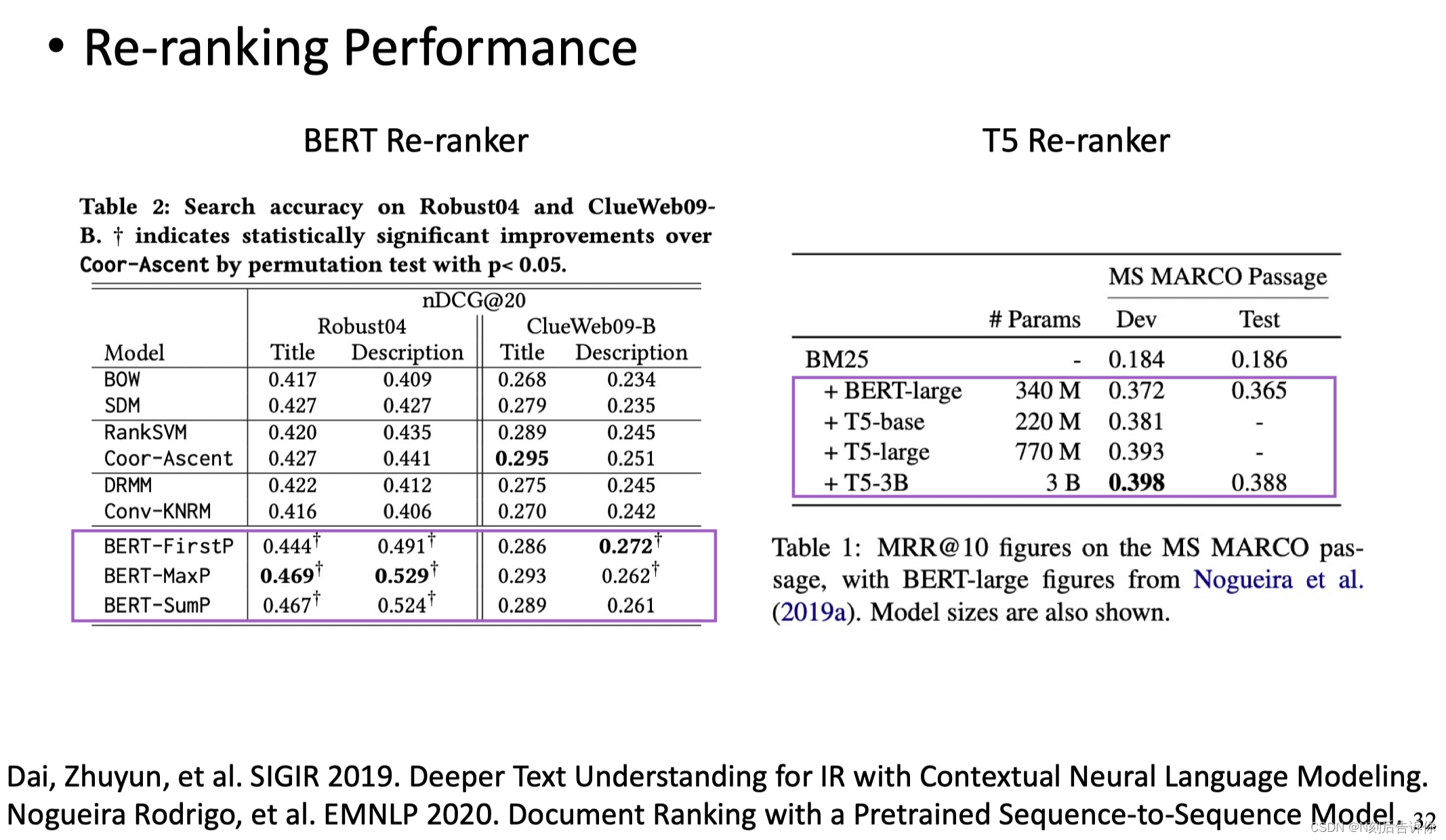
Neural IR
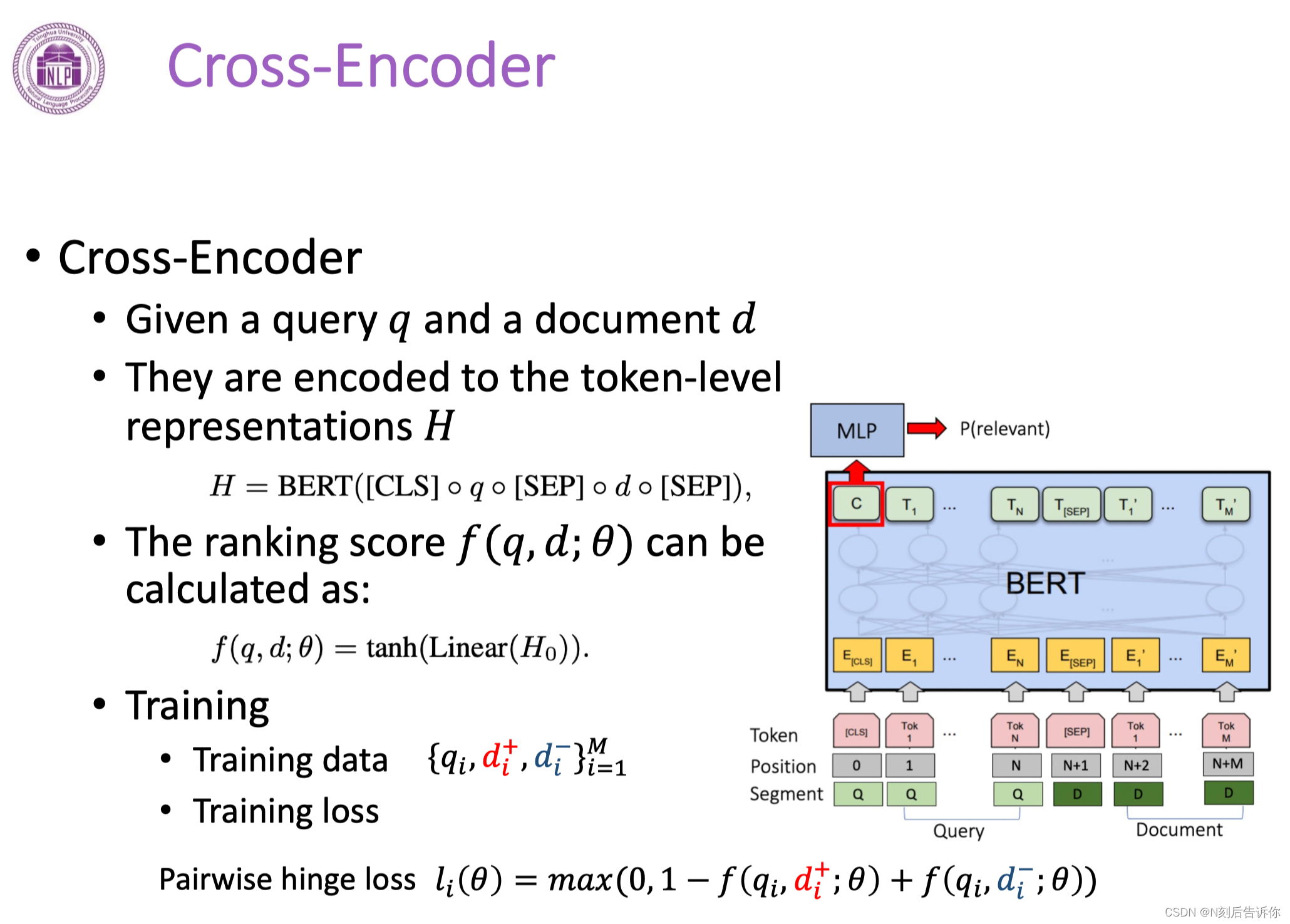
在Re-ranking阶段主要使用cross-encoder架构:query和doc进行词汇级别的拼接,然后喂给大模型。经过大模型之后生成q-d的表示,最后得到相关性分数。
好处是:精细,效果好。
缺点是:计算代价高。
在Retrieval阶段主要使用Dual-encoder架构:使用双塔架构,对query和doc分别进行编码,经过大模型,形成两个独立向量,再去计算向量的相似性。
好处是:计算开销较小。
Cross-Encoder
Dual-Encoder
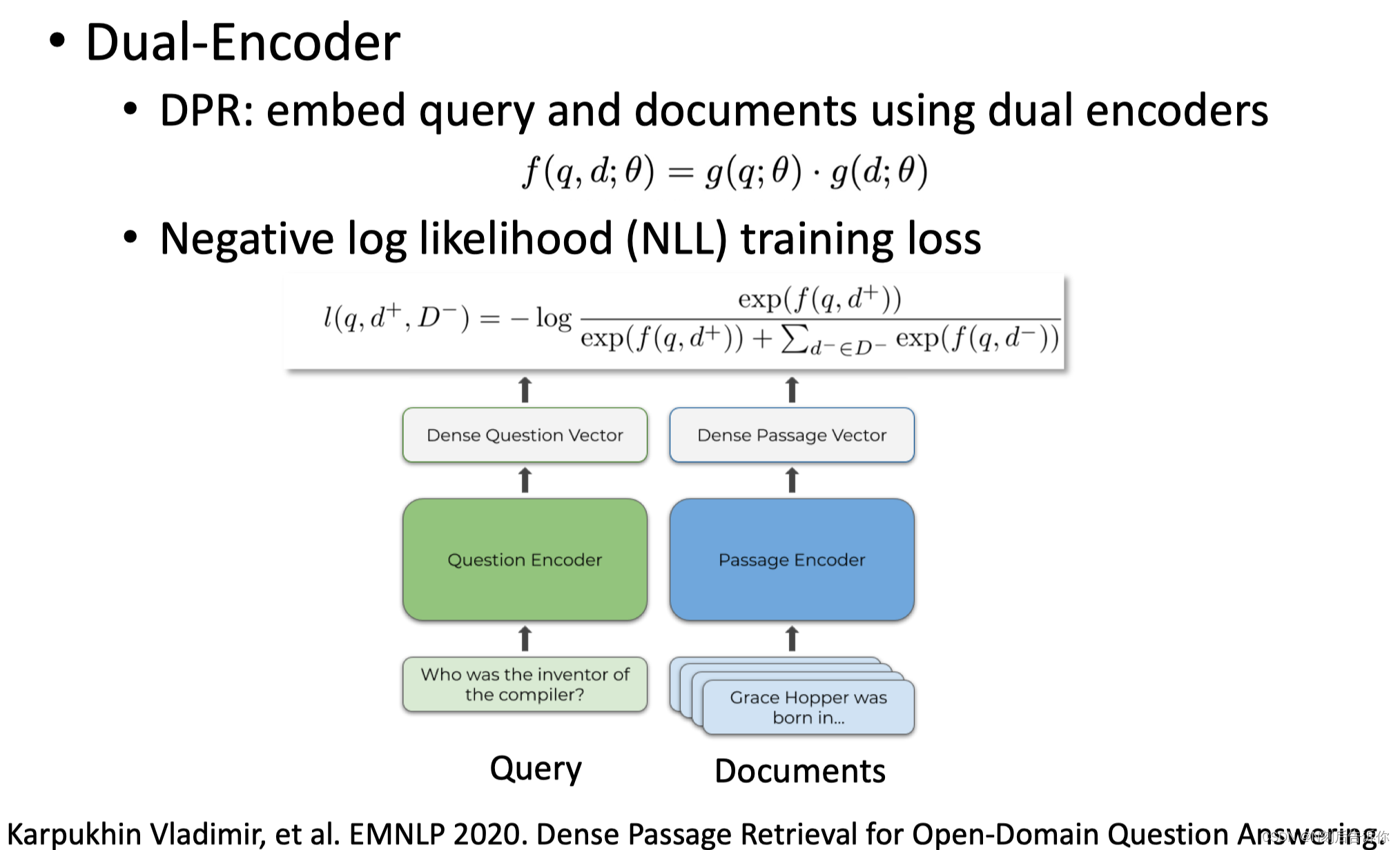
Dual-Encoder的好处是,因为是分开编码的。所以可以对整个文档库提前编码好,将其向量存起来。有新的query进来,只需要编码query,然后用最近邻找到相关的文档。
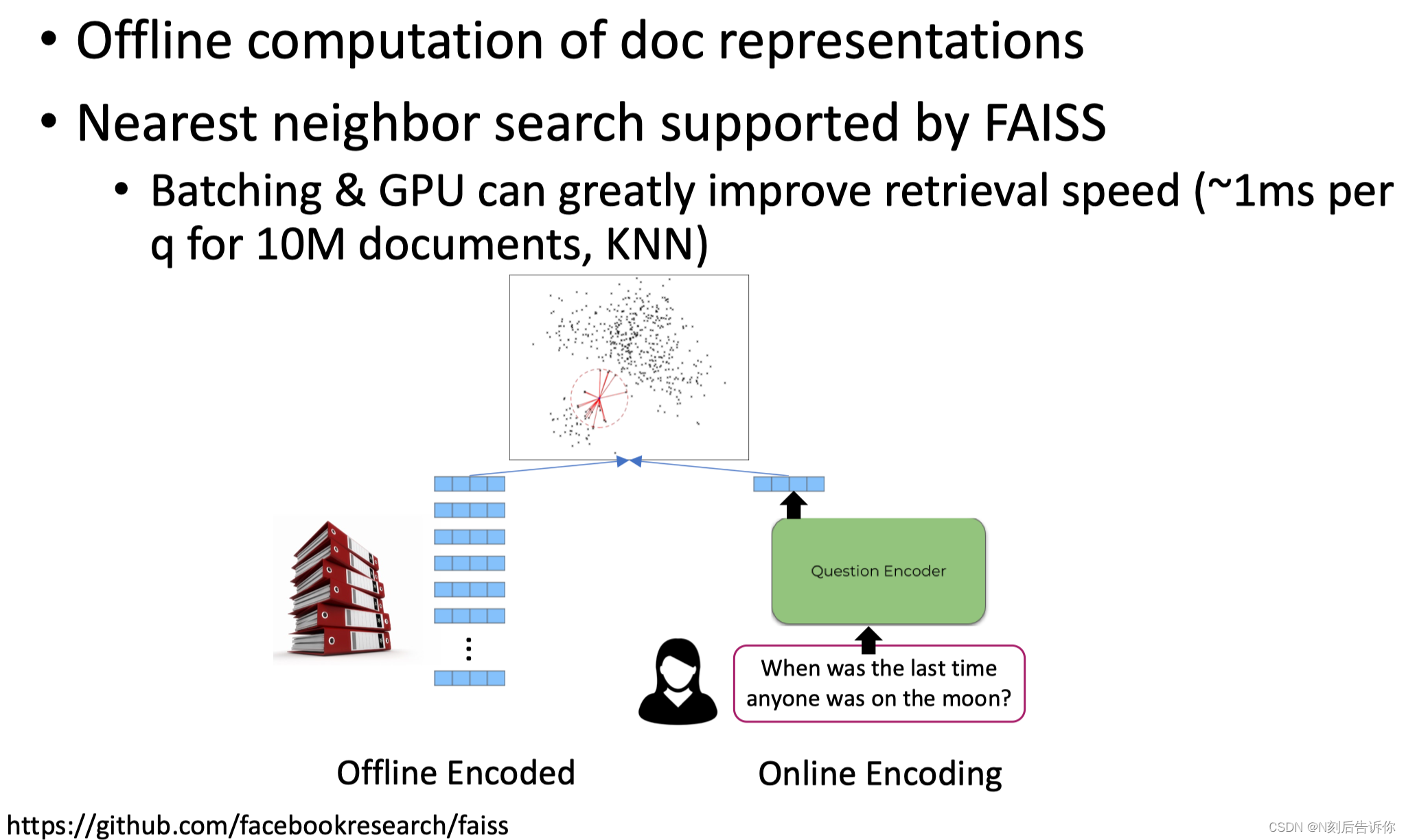
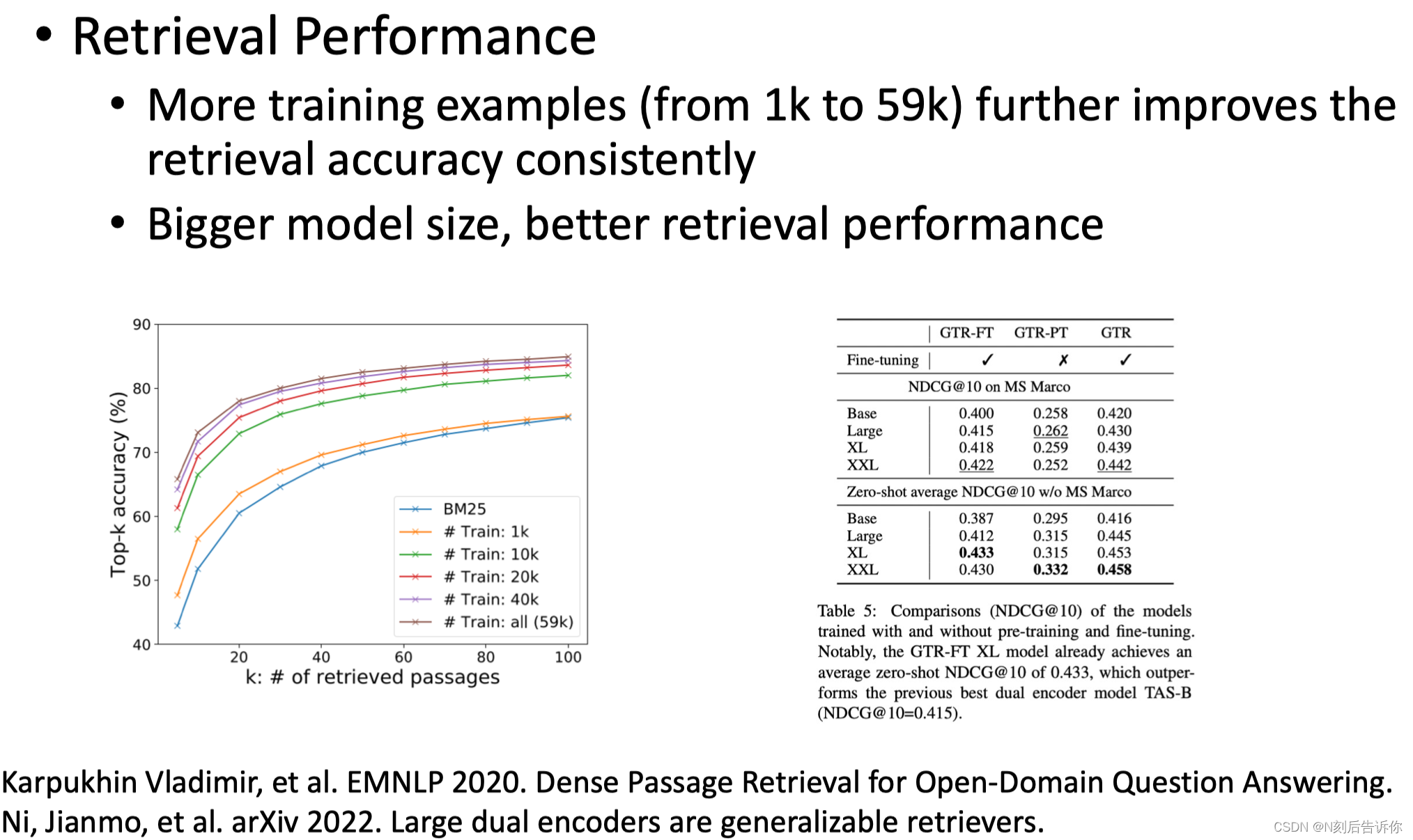
前沿热点
Fine-tuning中的负例增强
in-batch negative:同一batch的正例可以作为其他query的负例
random negative:随机从文档库中采样,作为负例
BM25 negative:先用BM25针对每个query抽回一些top k文档,再把相关的删除,剩余就是不相关的。
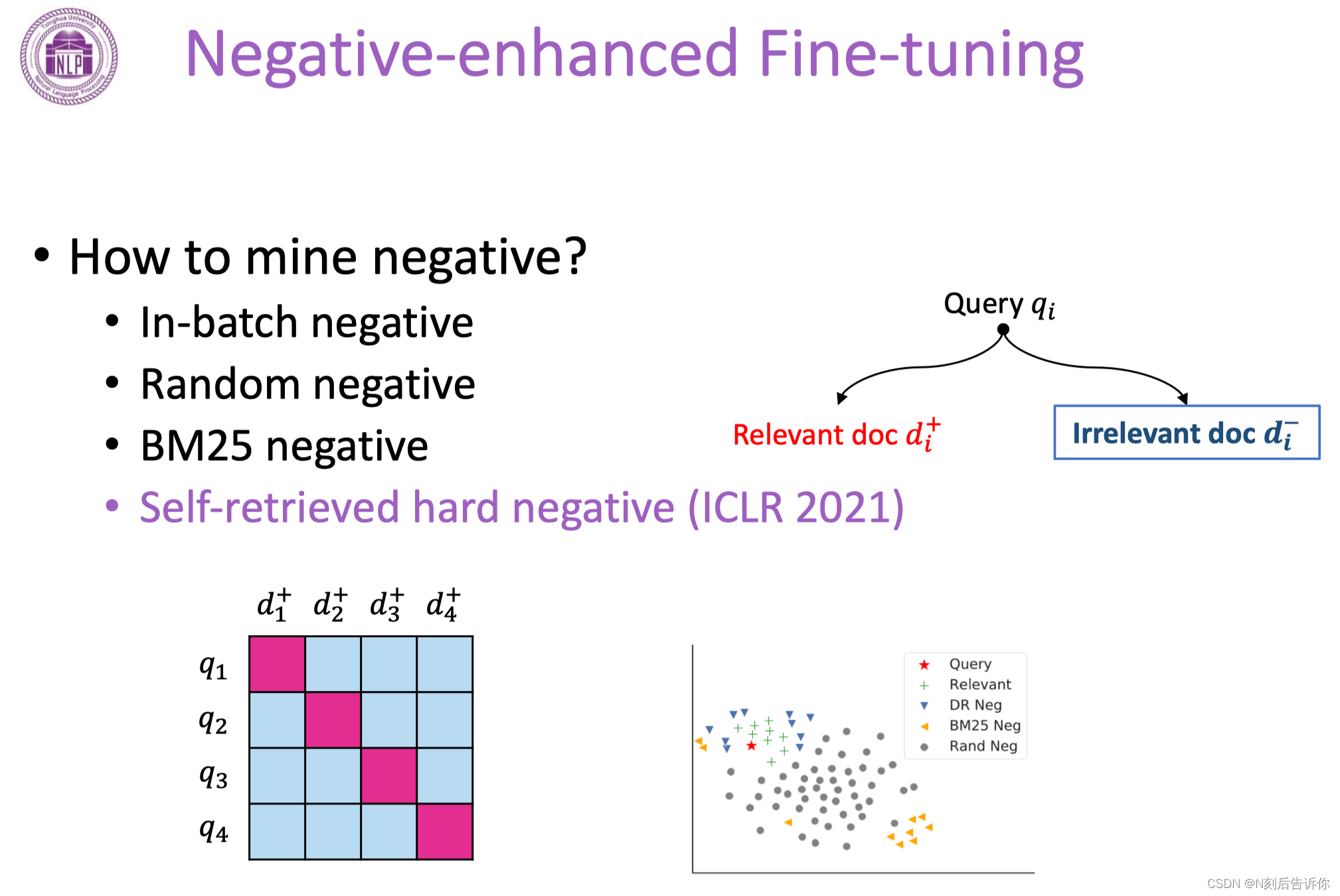
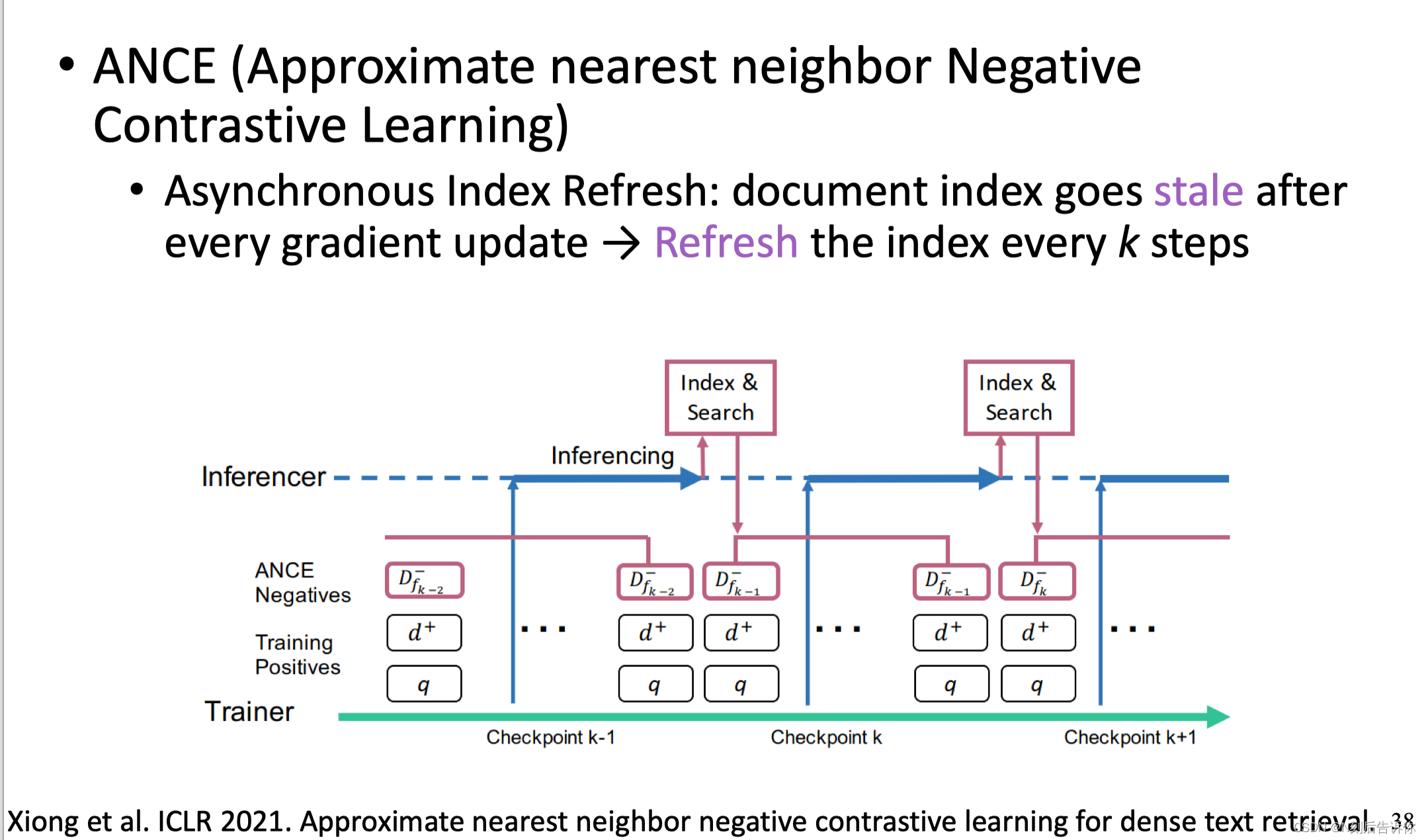
下面介绍一篇ICLR2021的工作:训练过程中,使用模型本身去挖掘更难的负样本。
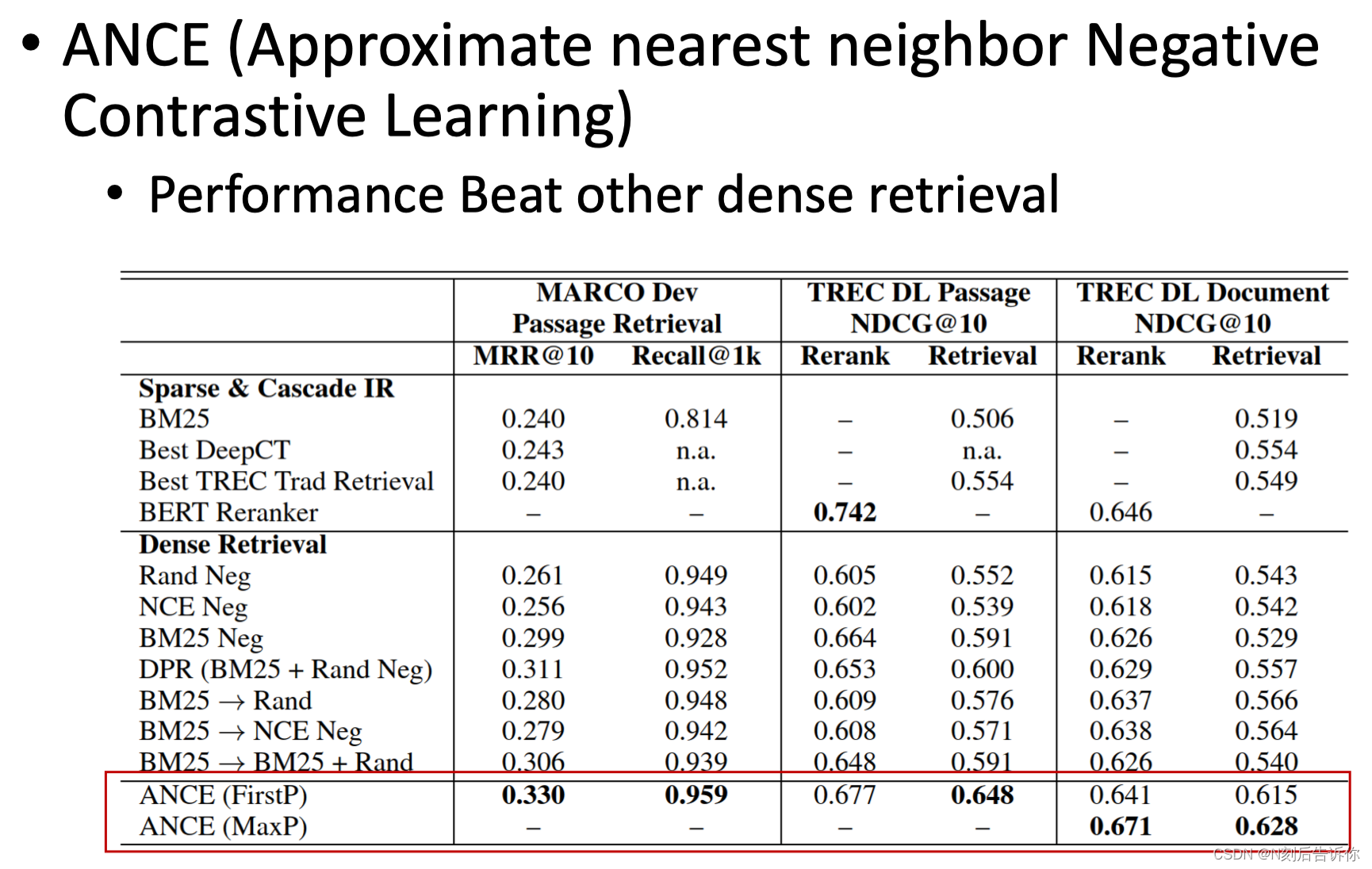
具体地,在模型训练过程中,异步维护一个inferencer的程序。每隔k步将最新的模型拿去做inference,把排名靠前的难负样本抽回来。再加到新的一轮训练中,不断迭代。
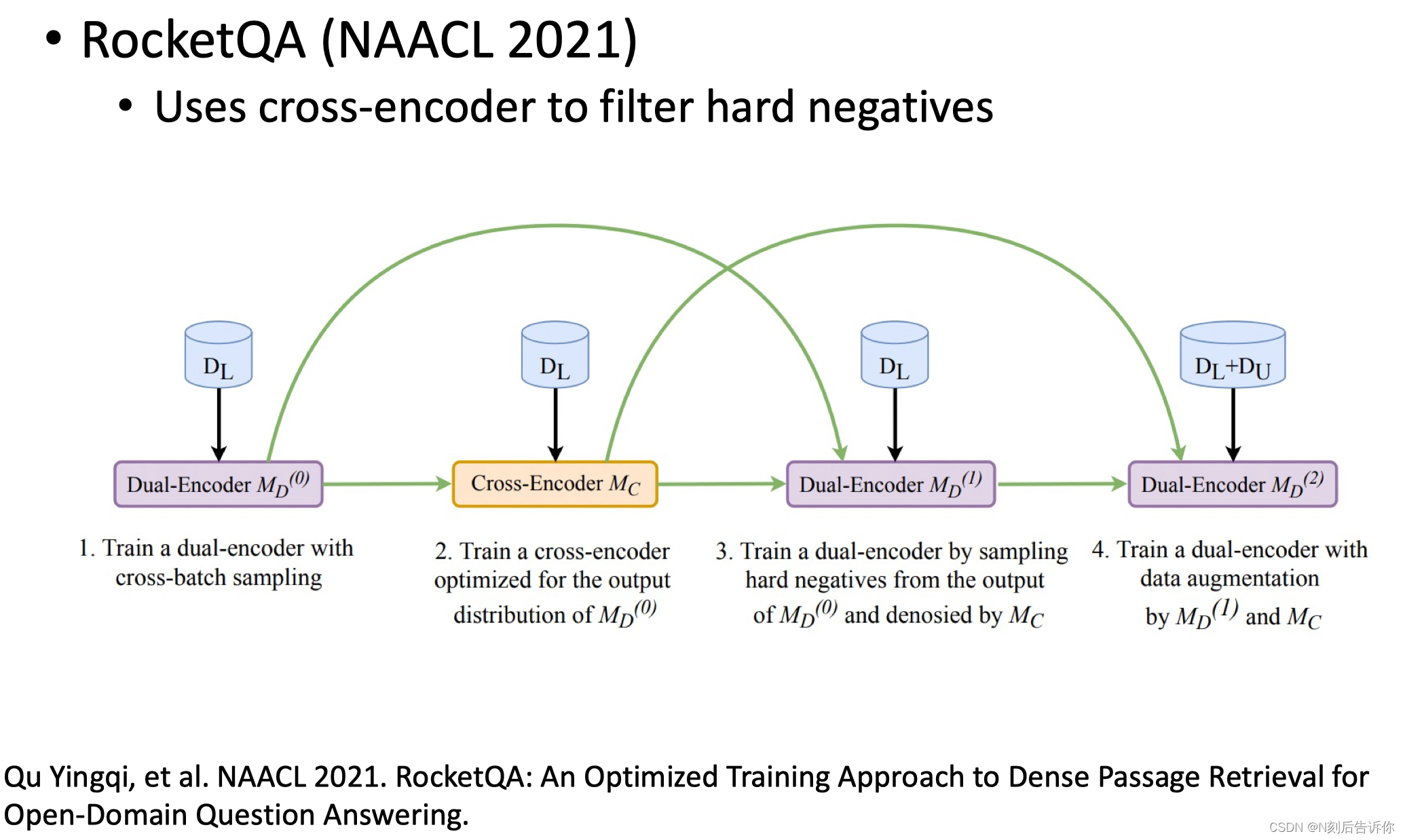
RocketQA引入了建模更精细的Cross-Encoder帮助Dual-Encoder筛选难负例,再加到Dual-encoder的训练中。
预训练阶段
为encoder配置弱的decoder,迫使中间的cls token具有更强的表达能力。
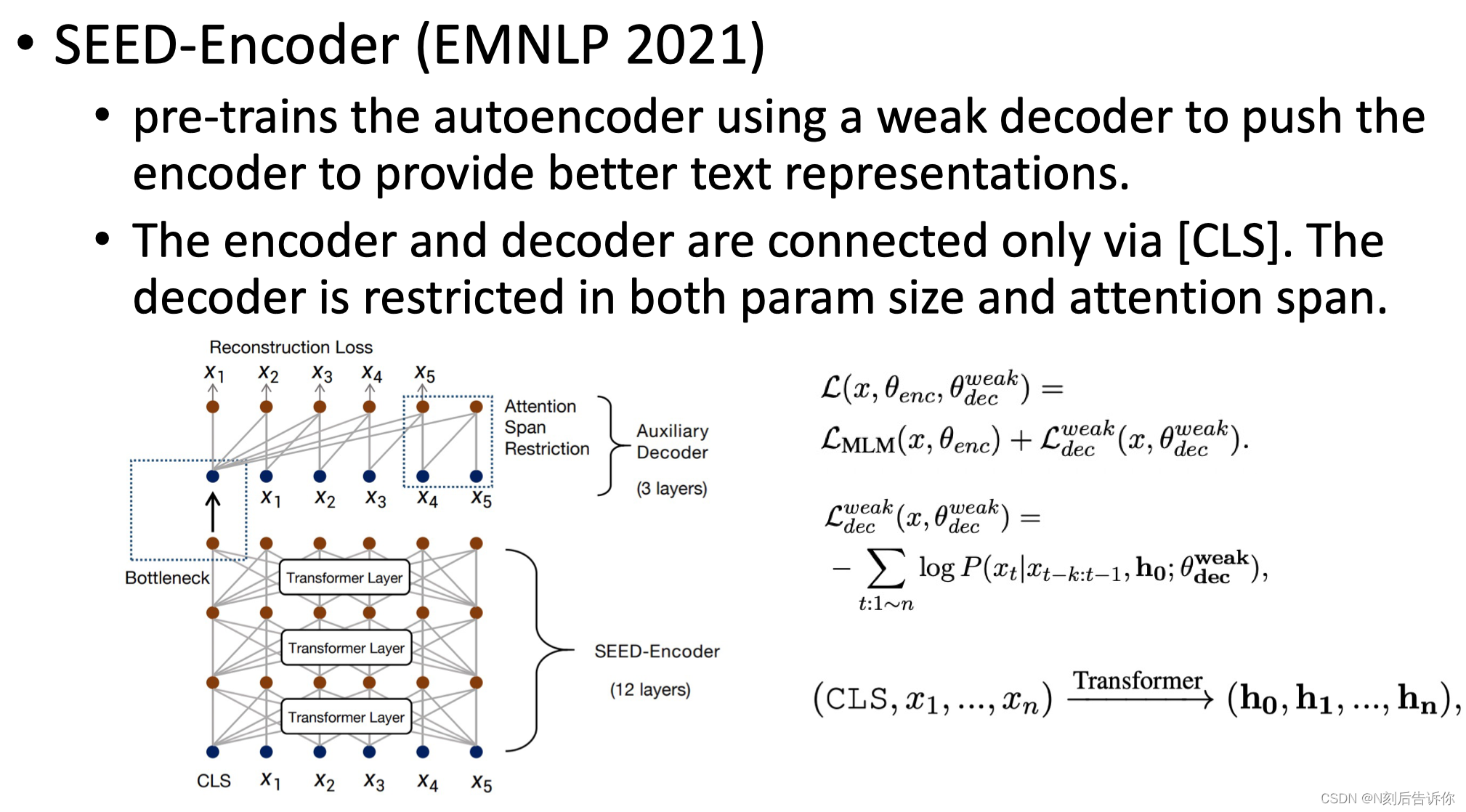
Few-Shot IR
有些网页天然缺乏用户的点击,用户的监督。
有一些涉及到隐私的个人检索,企业检索,他们的数据无法公开获得。
在医学和法律的检索领域,人工标注比较昂贵。

所以一部分研究是考虑如何用弱监督的数据去取代监督数据。生成弱监督数据的方式可以包含,titile和文档组成的q-d对,锚文本和文档组成的q-d对,文档和相应大语言生成q-d对。
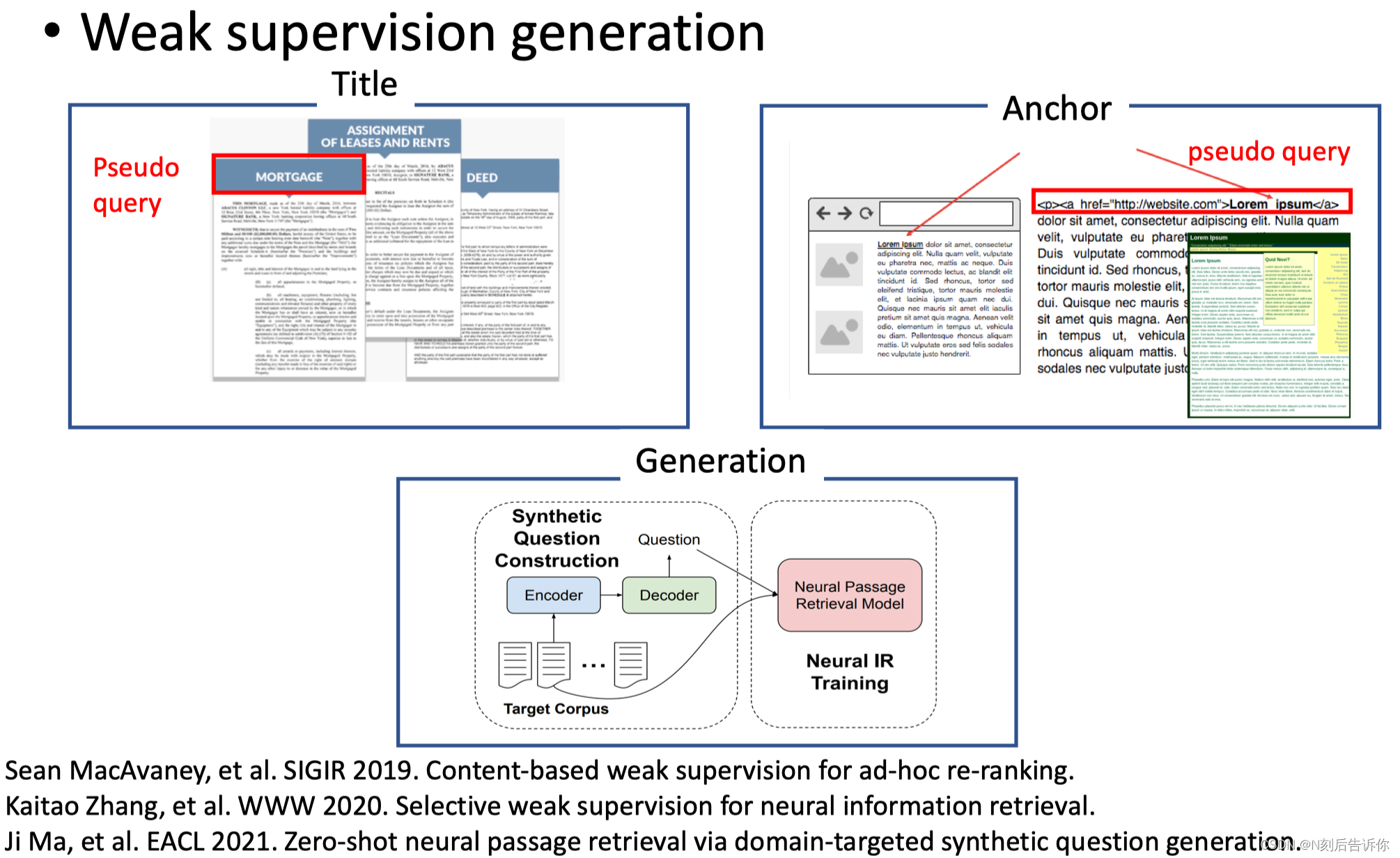
弱监督数据的筛选:
但这些弱监督数据没有经过人工标注,可能存在噪声。于是可以经过筛选,具体的,通过训练和反馈的方式构建强化学习过程。
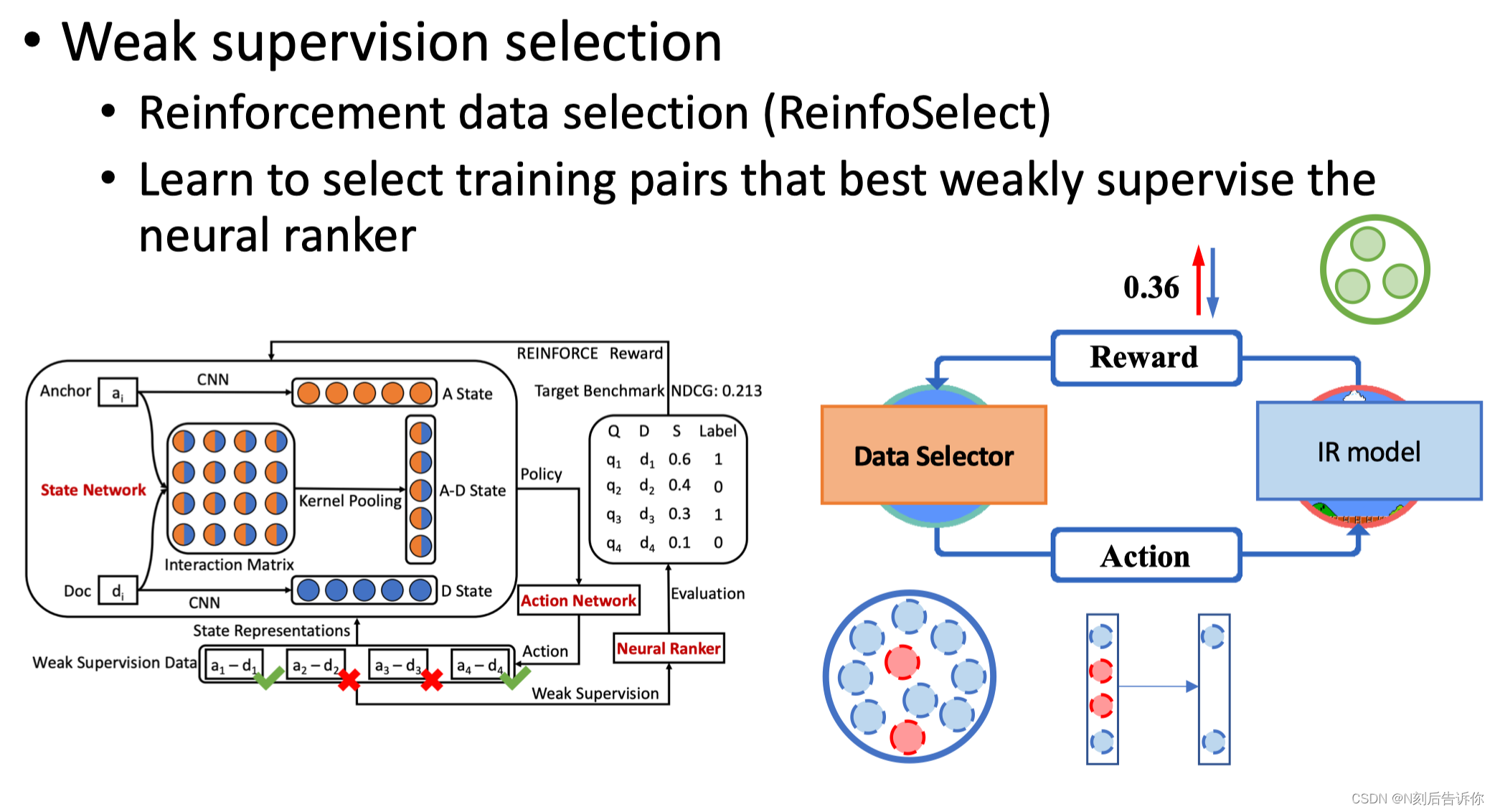
另一种方法是:meta-learning数据筛选
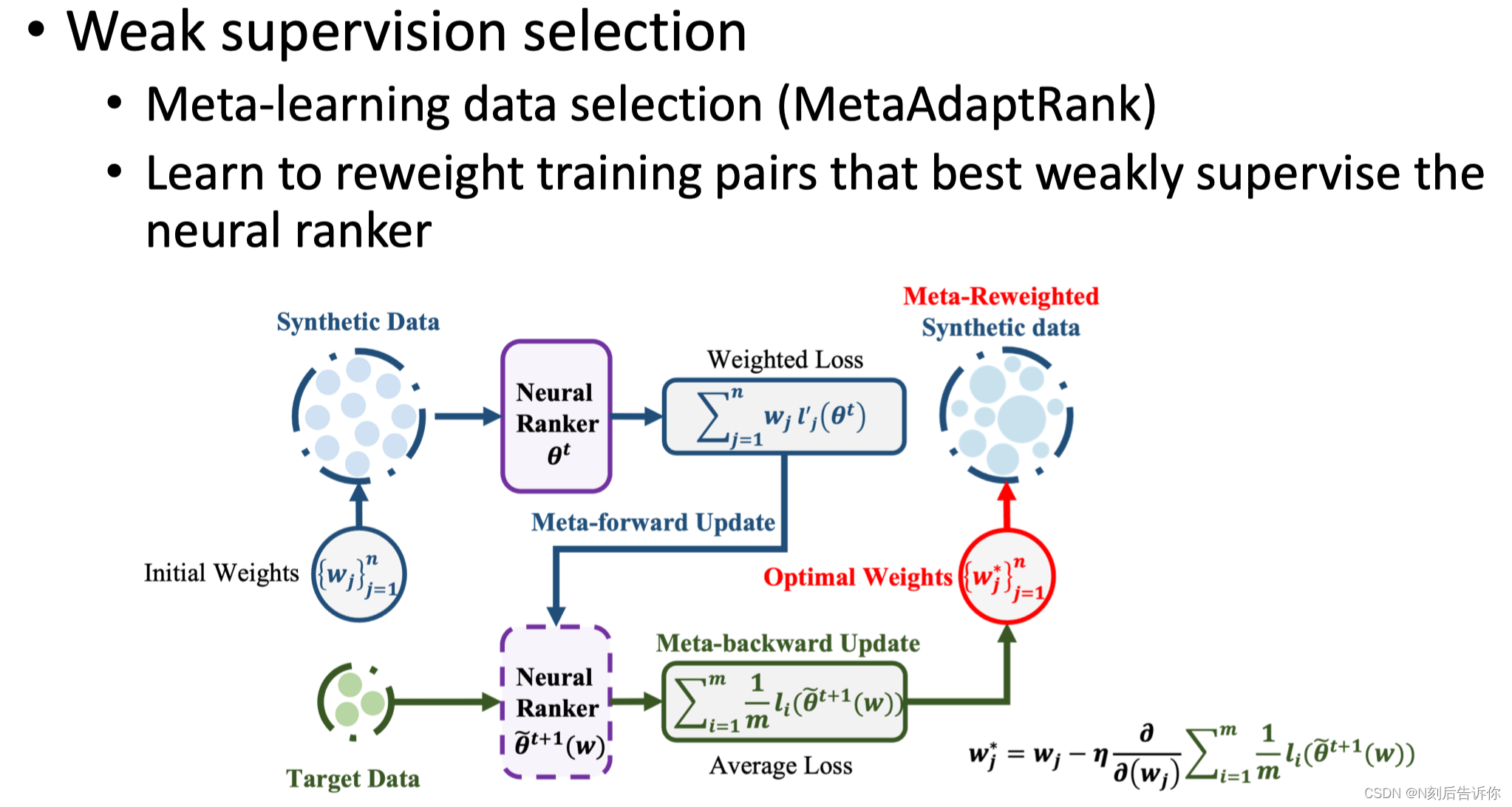
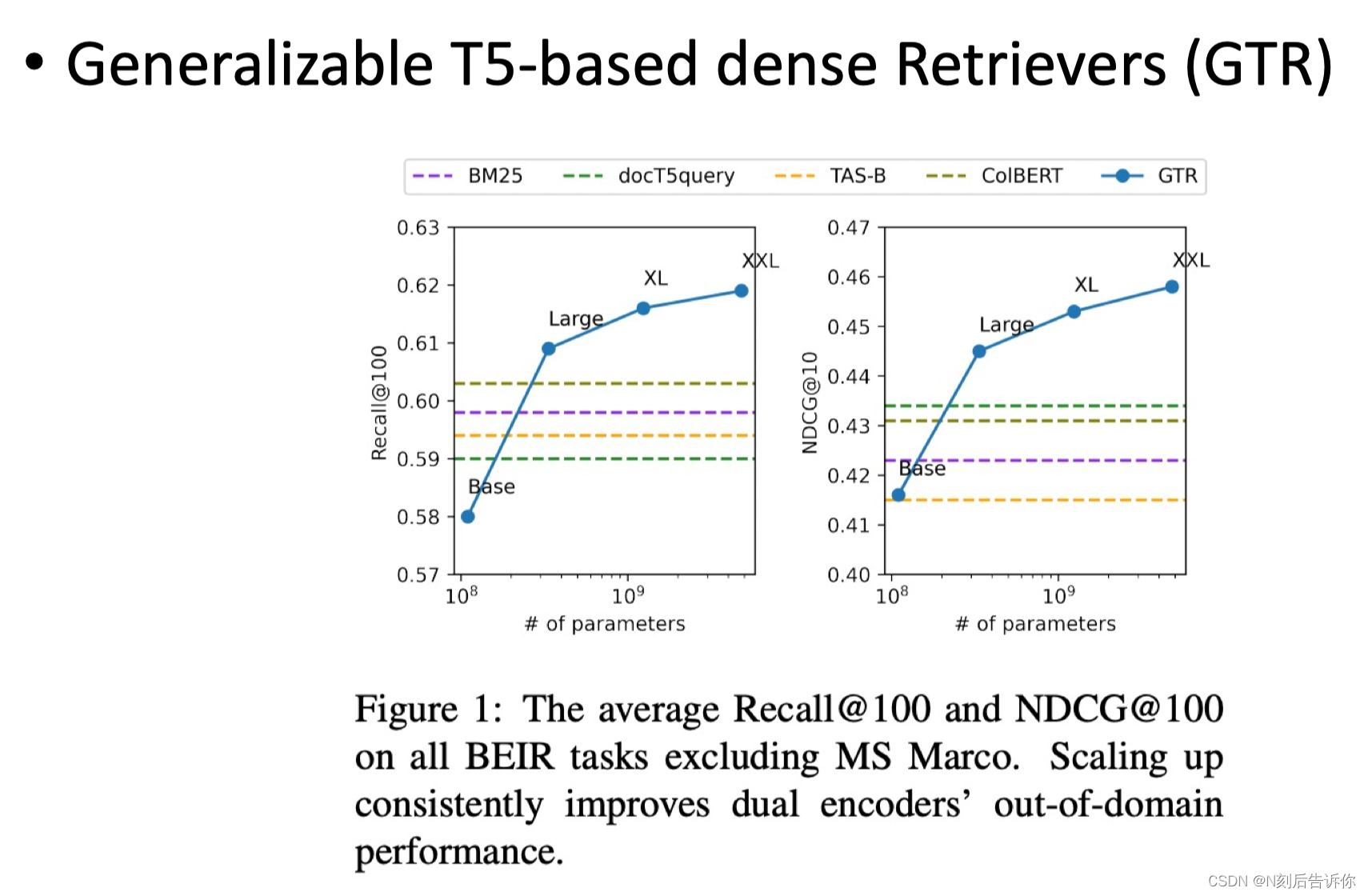
Zero-shot IR
训练好一个大模型之后,直接迁移到其他领域。
其他课题
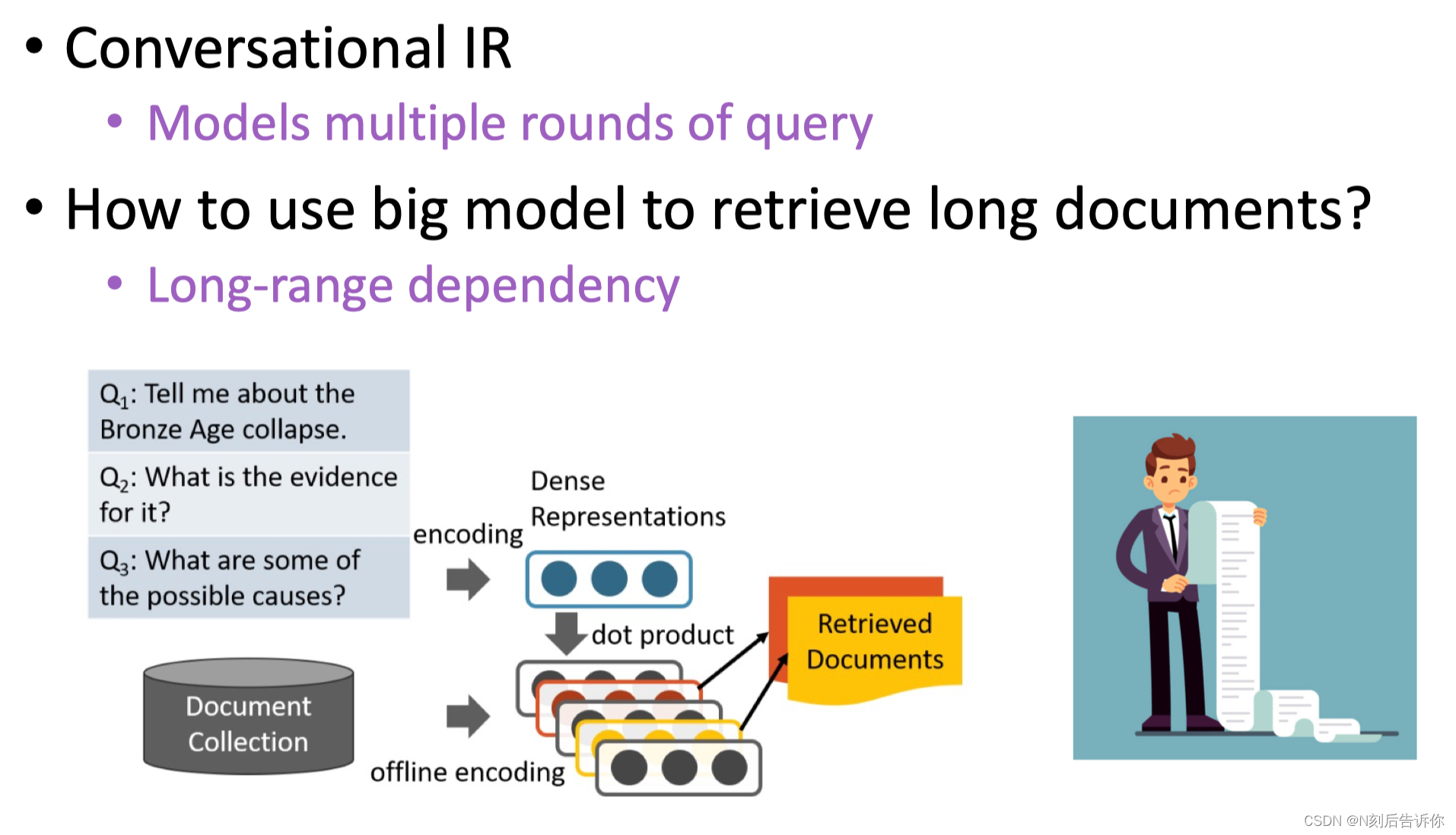
- 对话检索
- 如何检索长文档
机器问答
介绍
主要的机器问答类型:机器阅读理解、开放域问答、基于知识库问答、对话式QA

机器阅读理解
任务定义
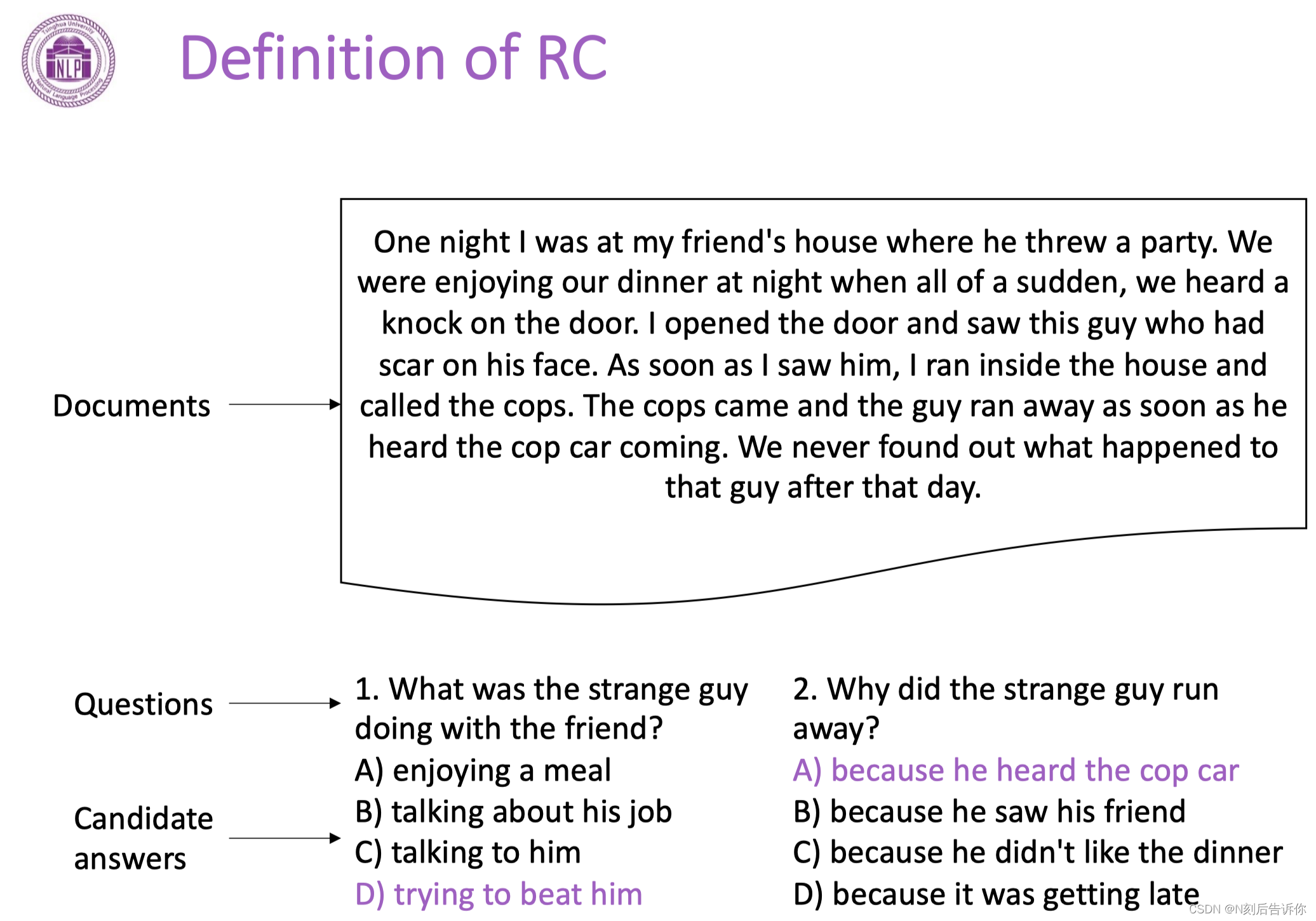
- 完形填空

- 多选

- 抽取式阅读理解(原文找答案)

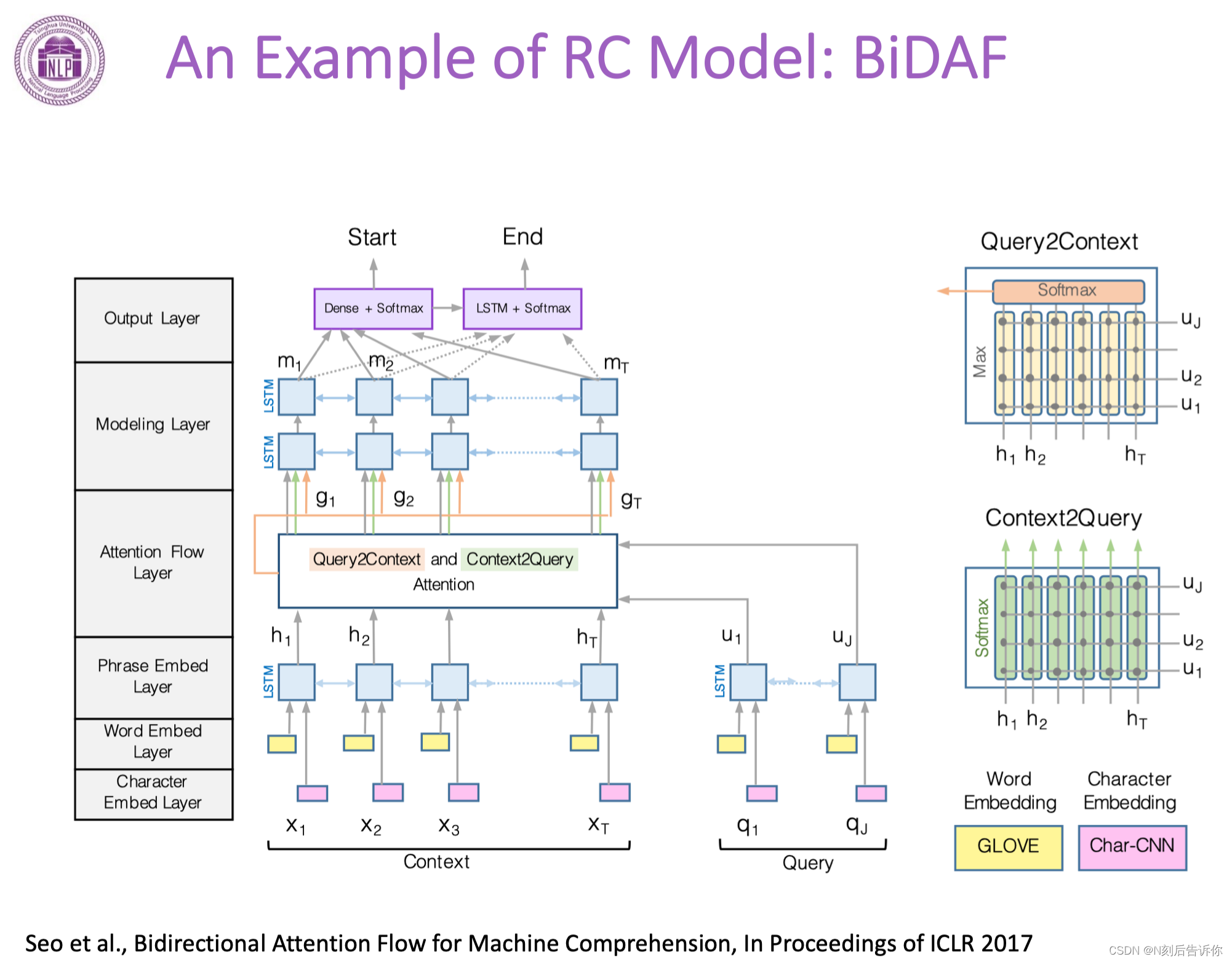
经典方法和pipeline
1.文档和问题分别进行编码
2.汇成一个向量
3.文章和问题进行交互
4.融合后的向量通过MLP来进行预测
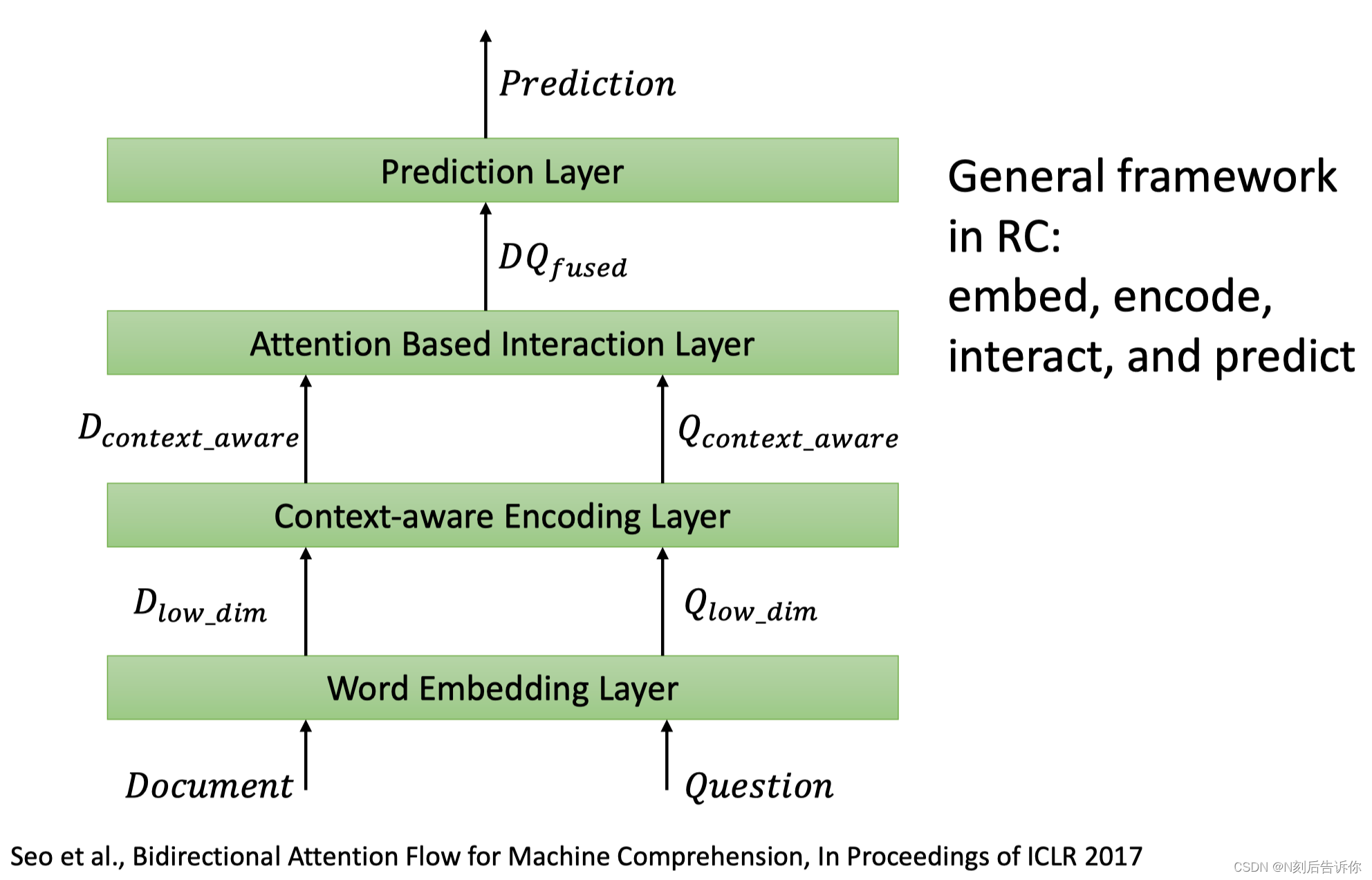
实例:BiDAF
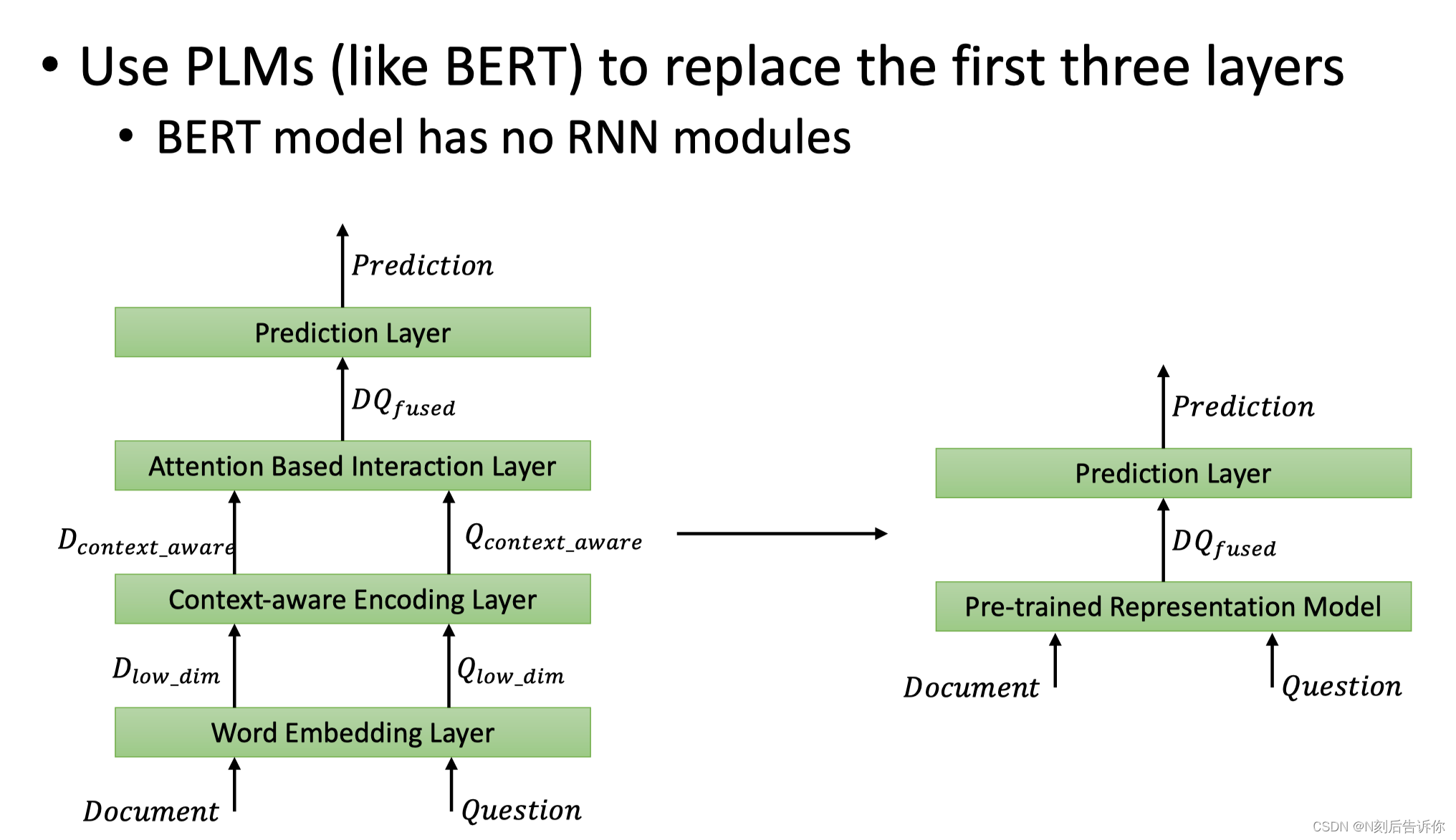
大模型方法
只需要大模型就可以将前三层直接替代
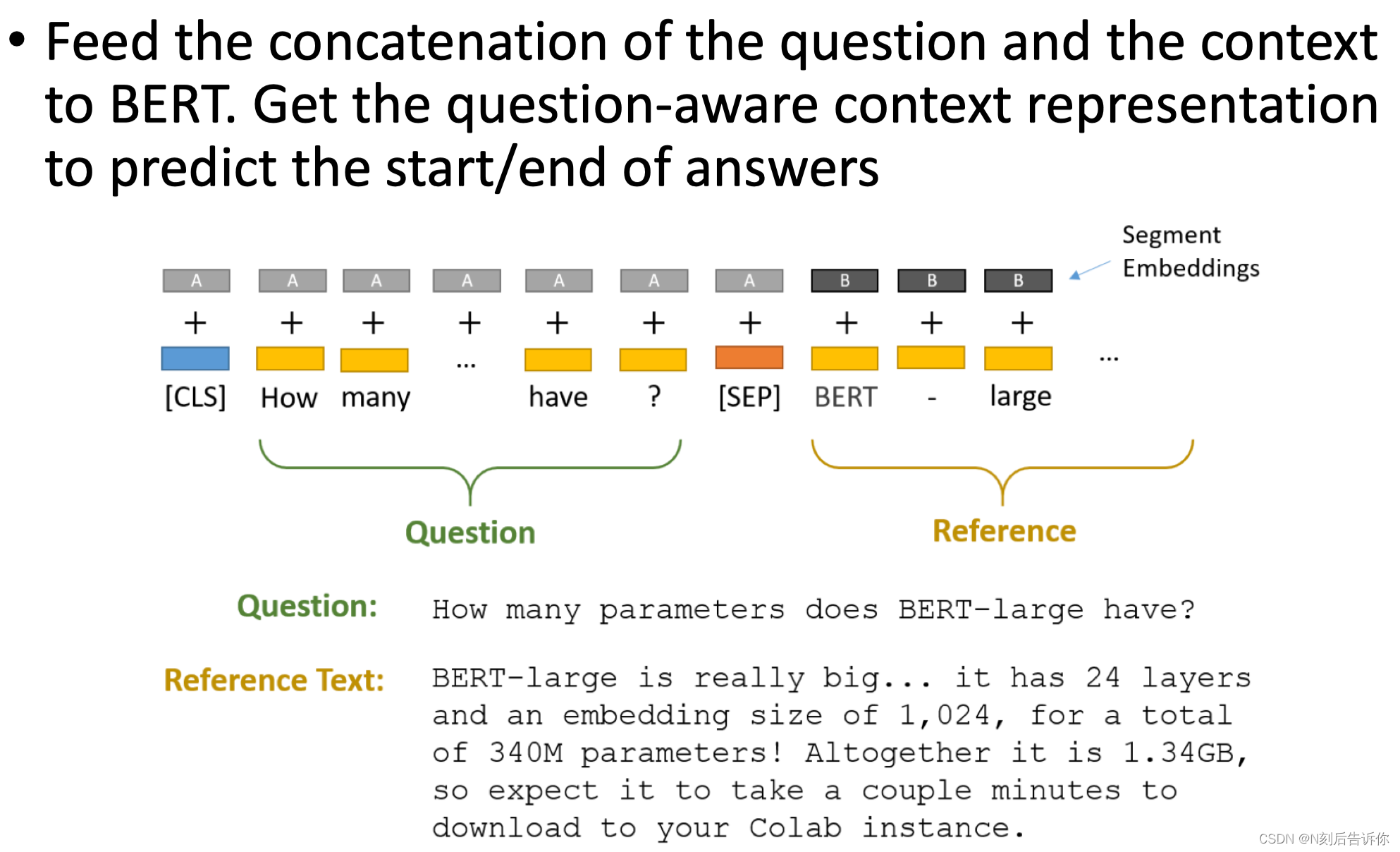
基于bert的问答系统
将问题和doc输入到bert中,再拿cls embedding出来,然后进行分类任务
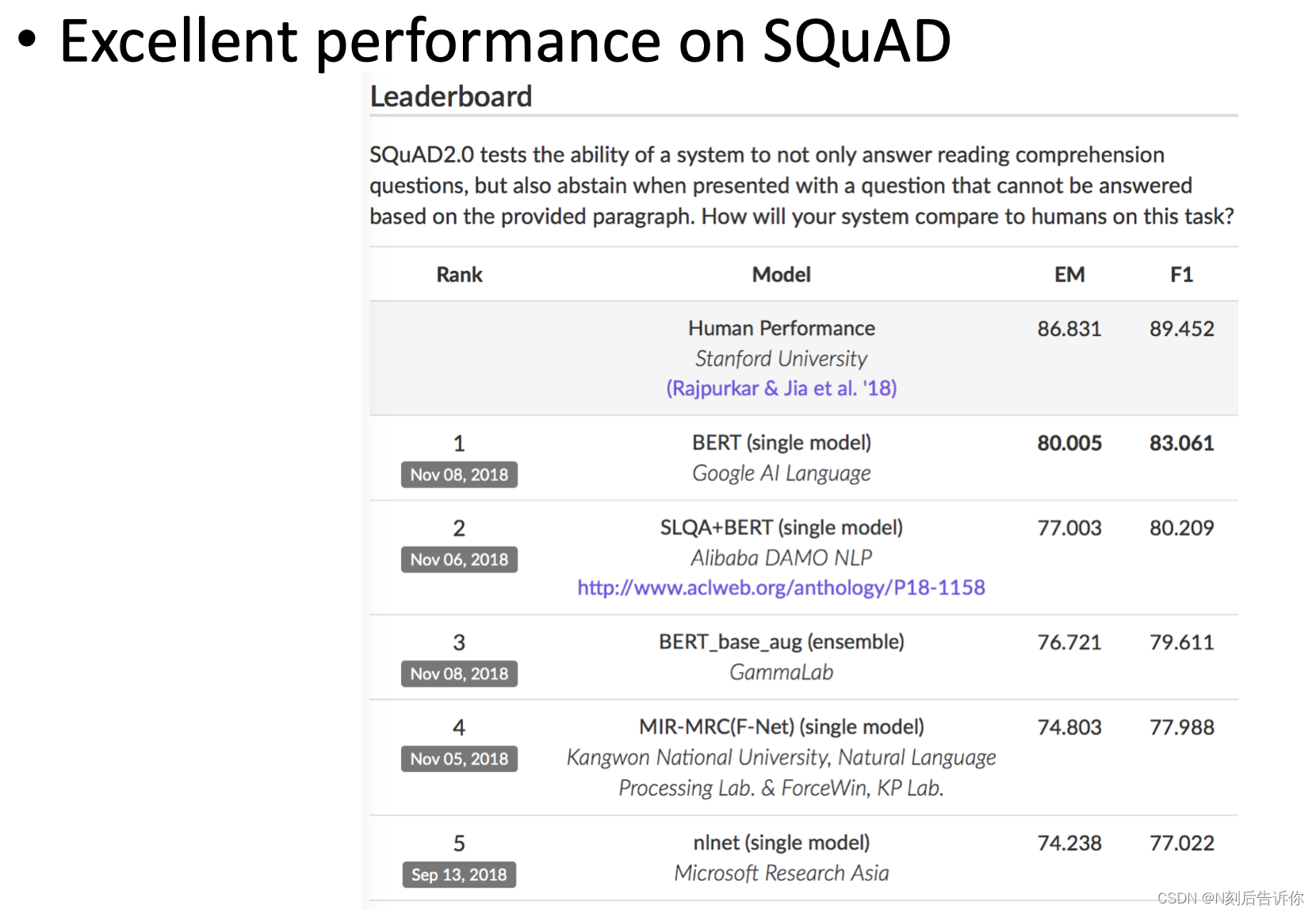
在SQuAD这个非常流行的抽取式QA数据集上,只用bert就取得了很好的成绩。
除了简化了pipeline,大模型用于QA的另一个好处是可以统一不同任务的形式,统一为text to text的形式。这保证了迁移性。
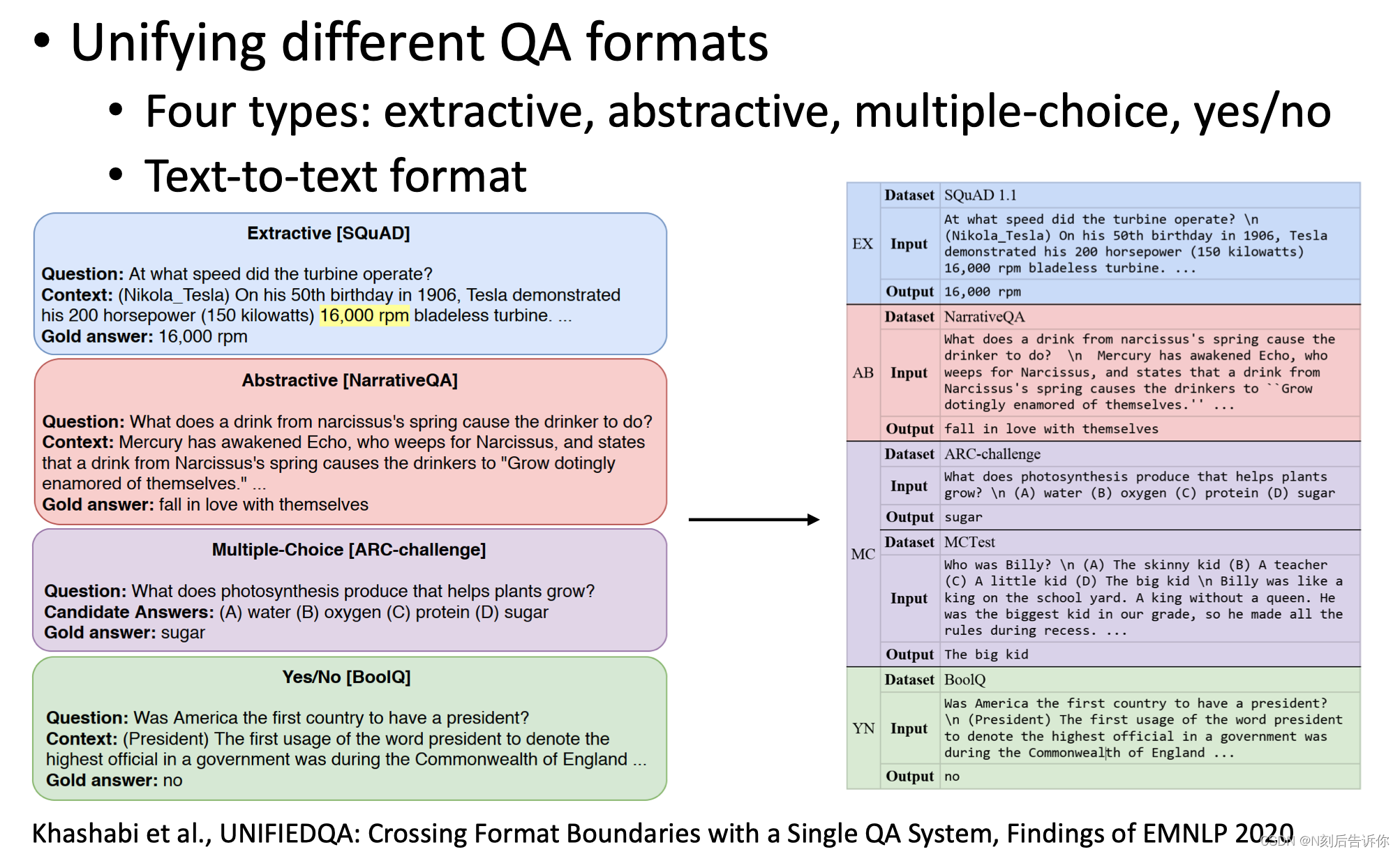
开放式QA
有语料库,但是没有具体的文档。开放式QA有两种类型:生成式方法、检索式的方法
生成式方法

检索式方法

大模型之前
检索
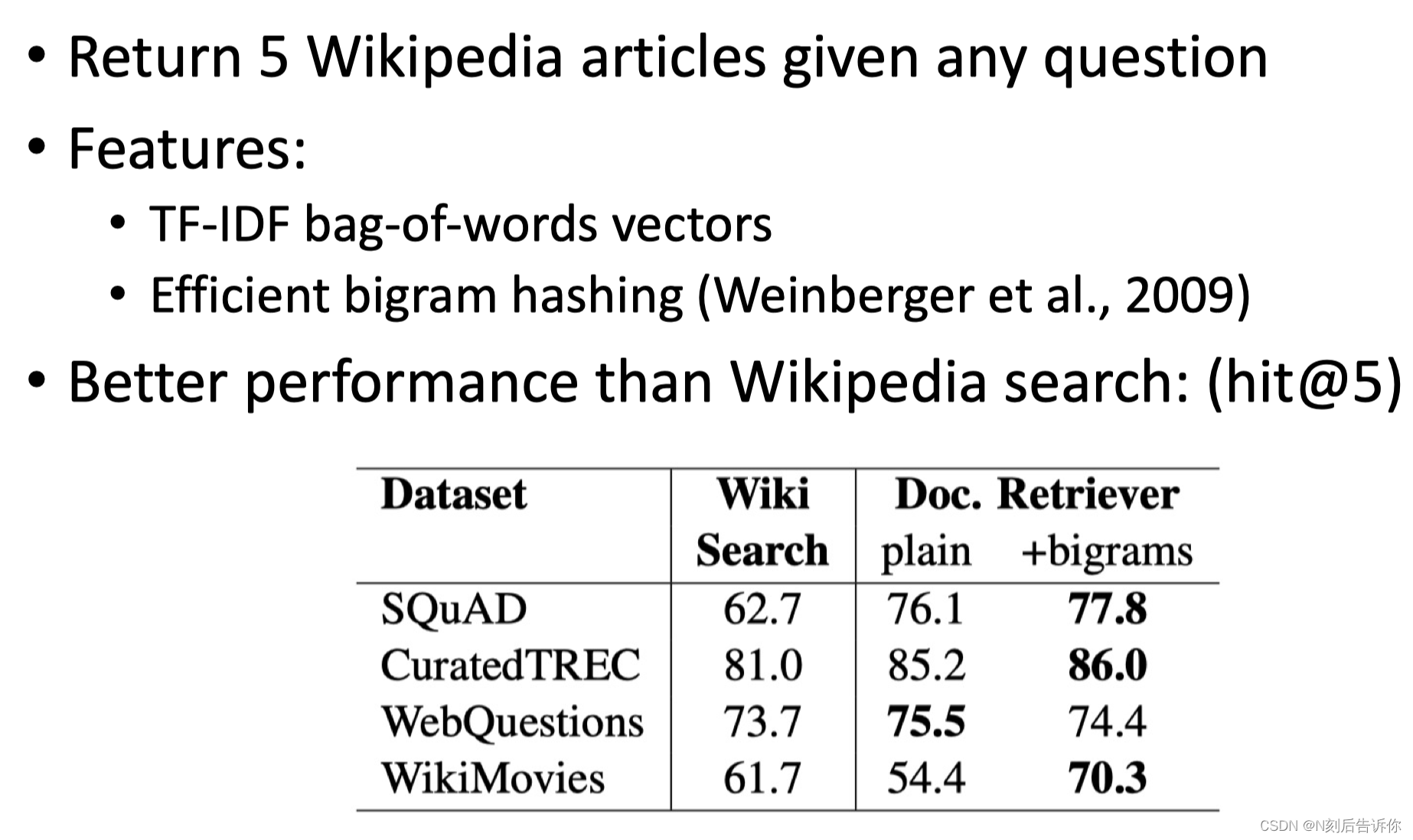
阅读理解

大模型方法
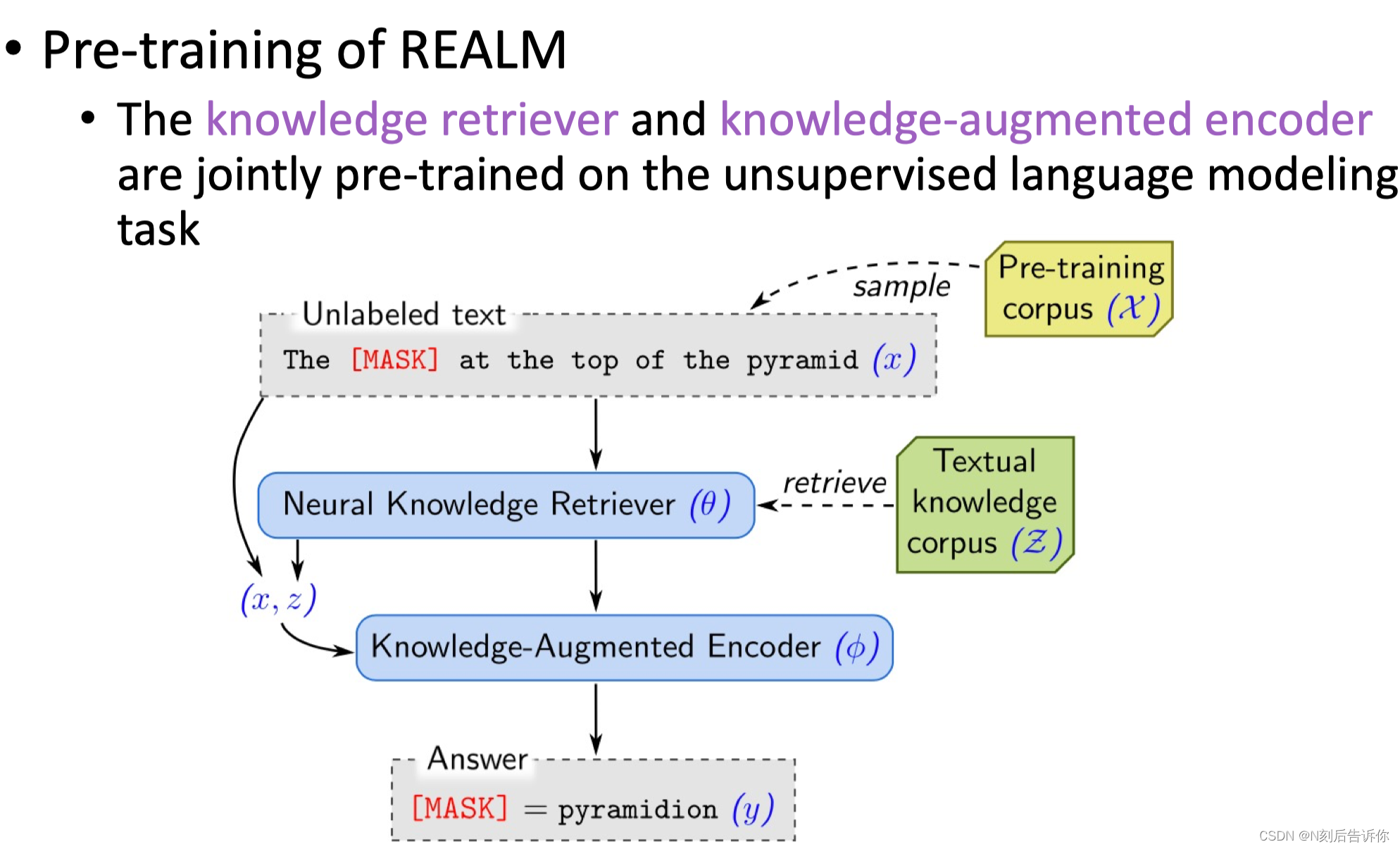
如何用检索来辅助大模型的预训练过程。让大模型在下游的机器问答环节中表现更好。
REALM在预训练过程中也加入检索任务。相当于把预训练也当成开放式QA的任务,在预训练时,同时训练大模型和知识的检索器。

让大模型根据检索到的语料库来回答答案。
WebGPT


文本生成
介绍
data-to-text: 可以把一些非语言性的表示的信息,通过模型,以人类可以理解的语言表示出来。
text-to-text
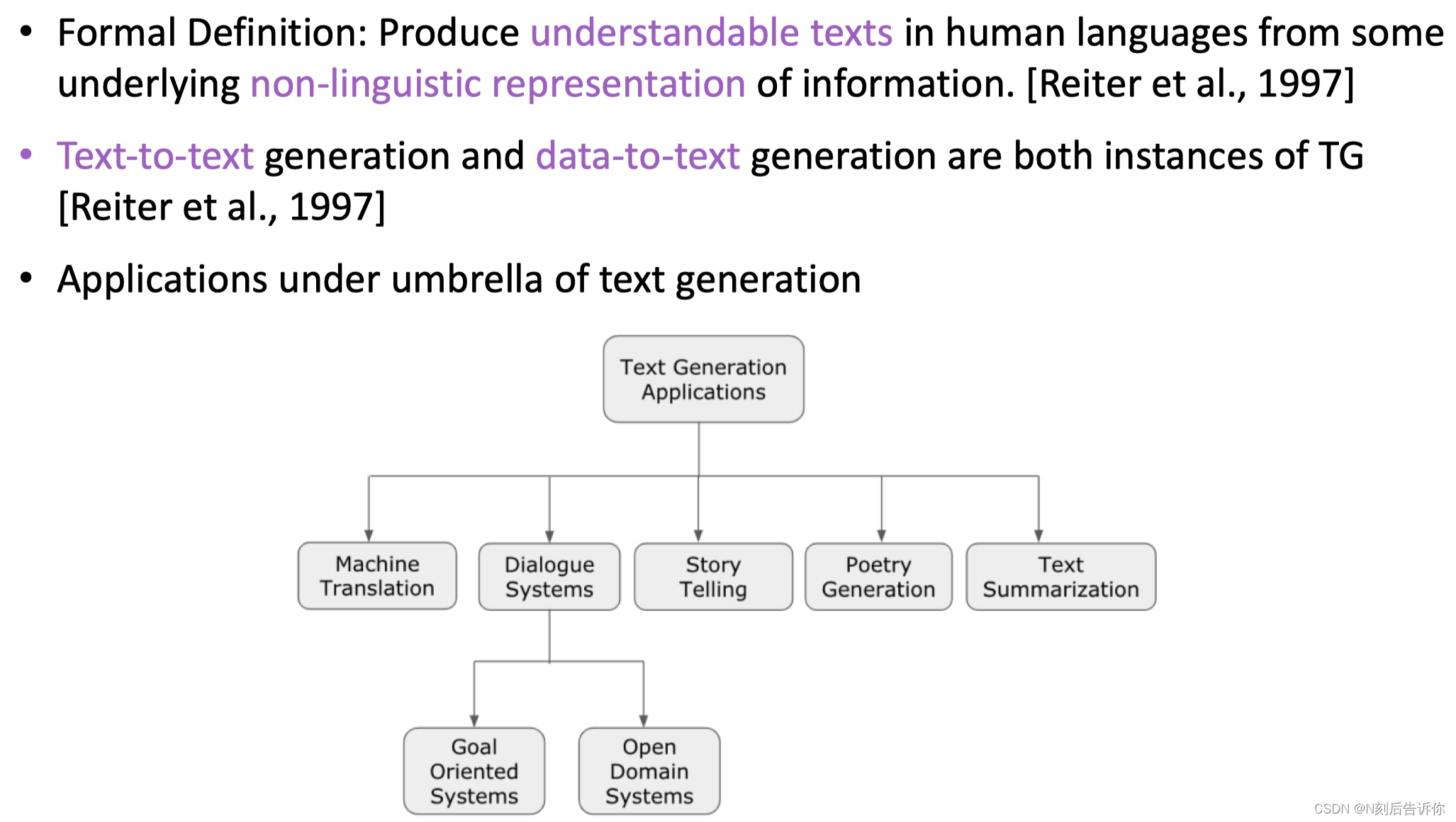
文本生成任务
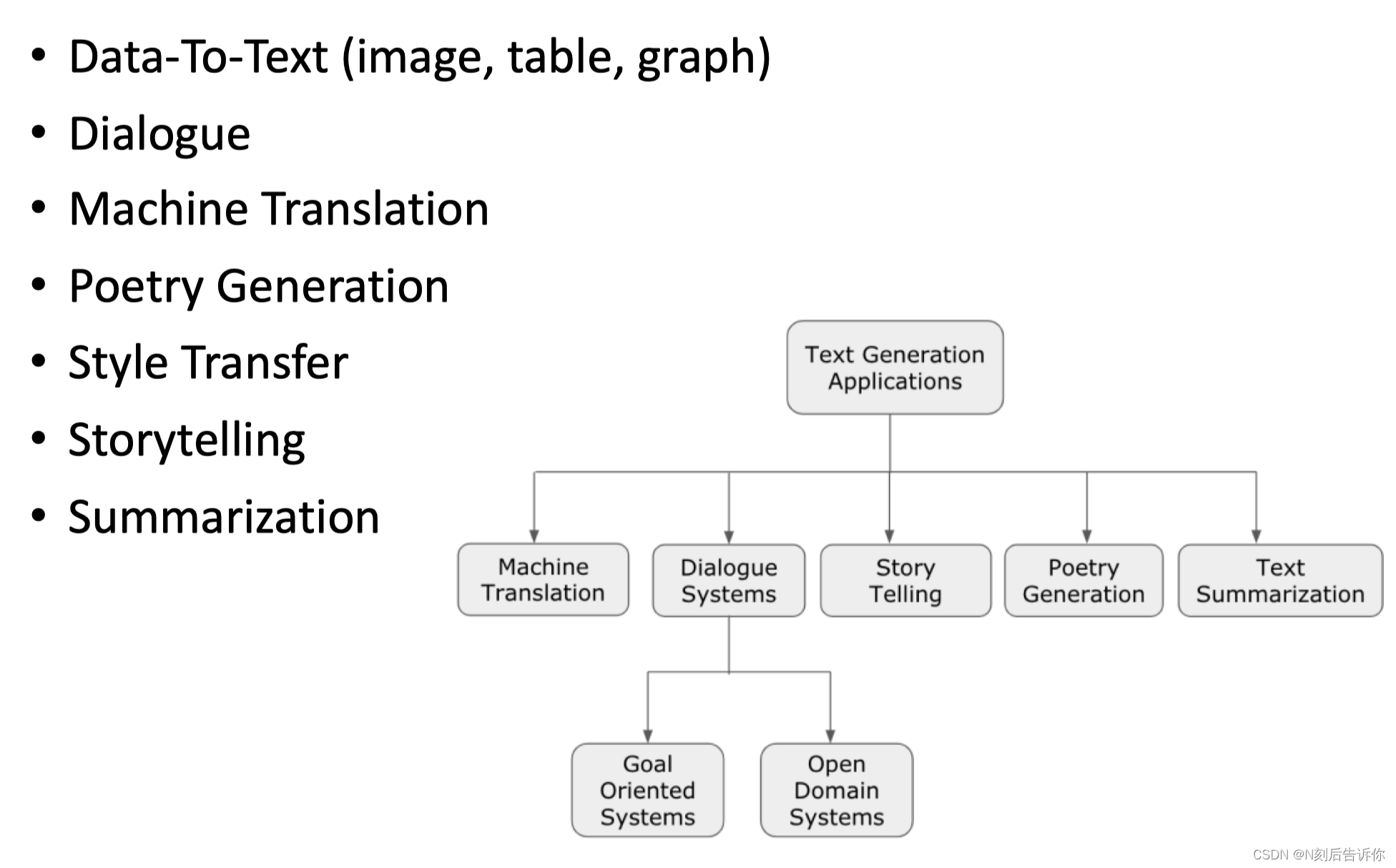
Data-to-Text

对话生成

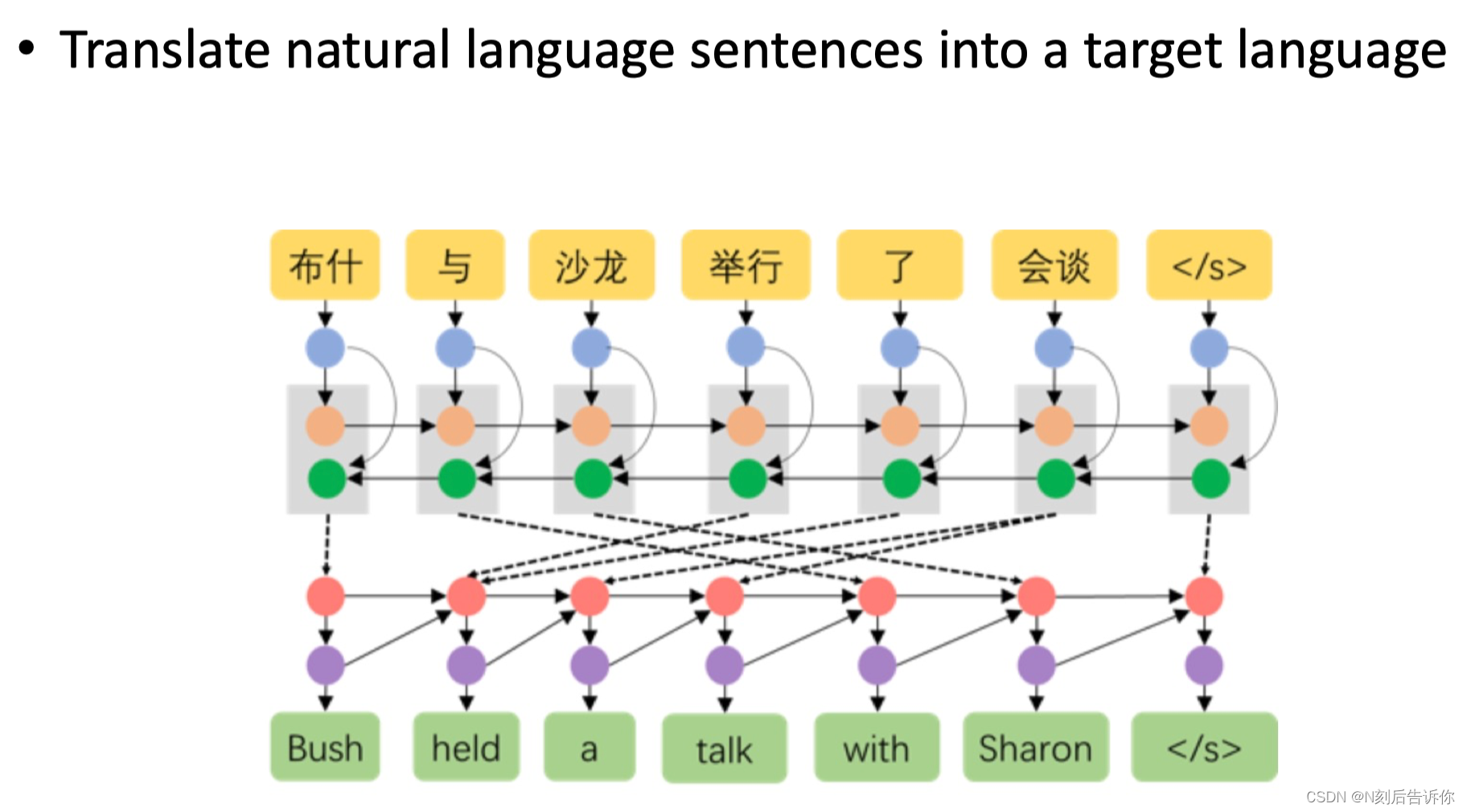
机器翻译
诗歌生成

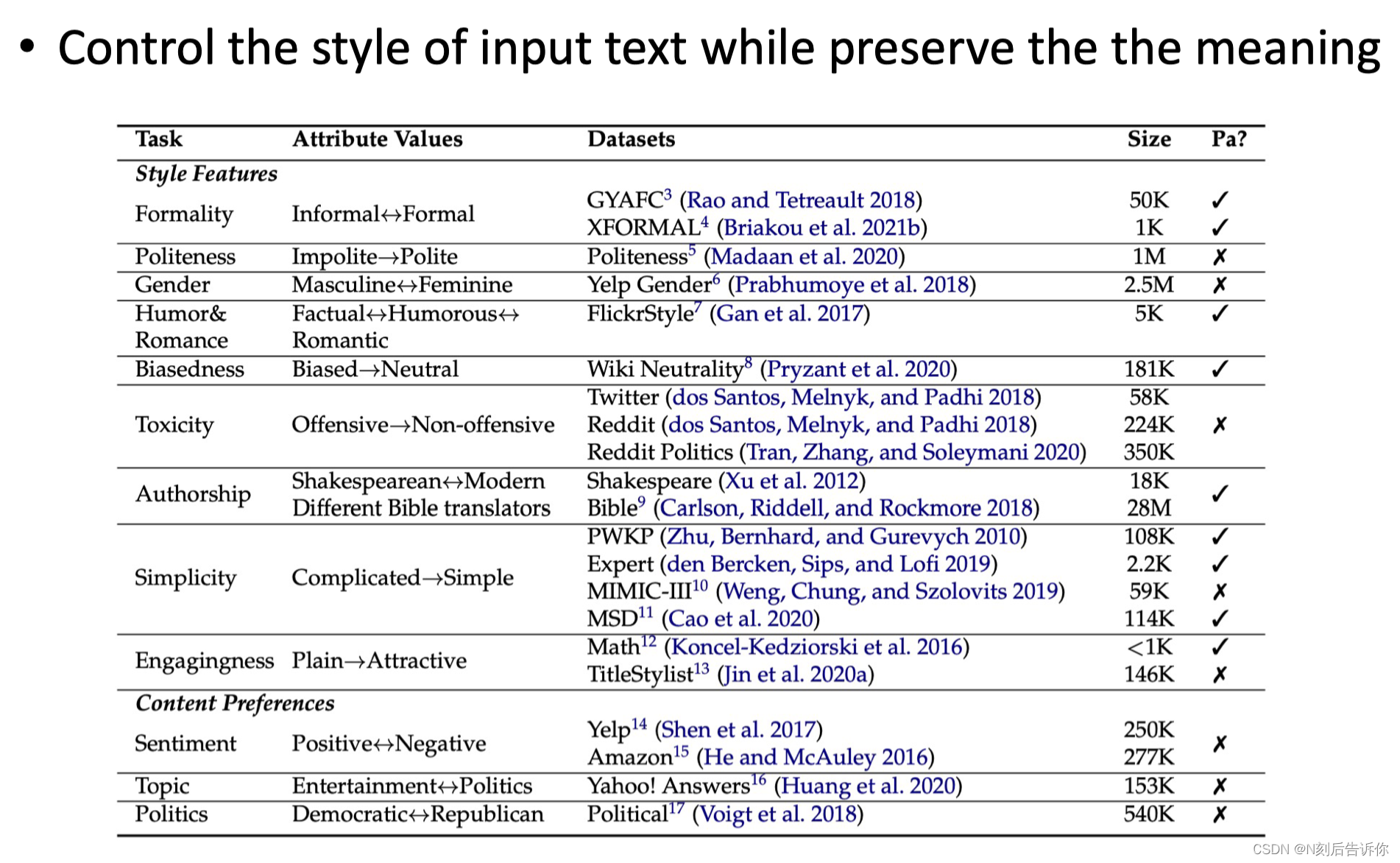
风格转义
故事生成

总结生成
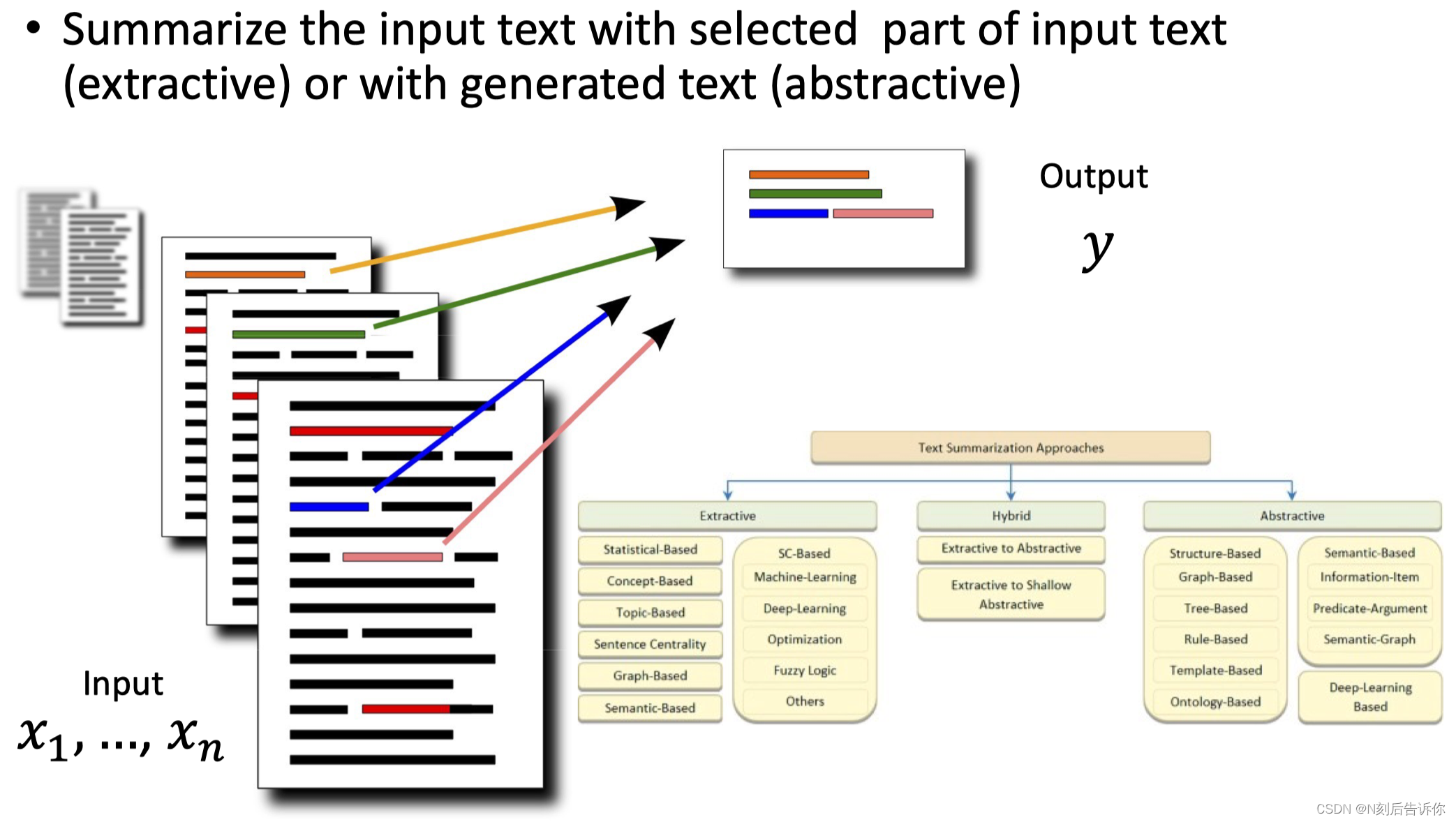
神经网络文本生成
语言建模-Language Modeling

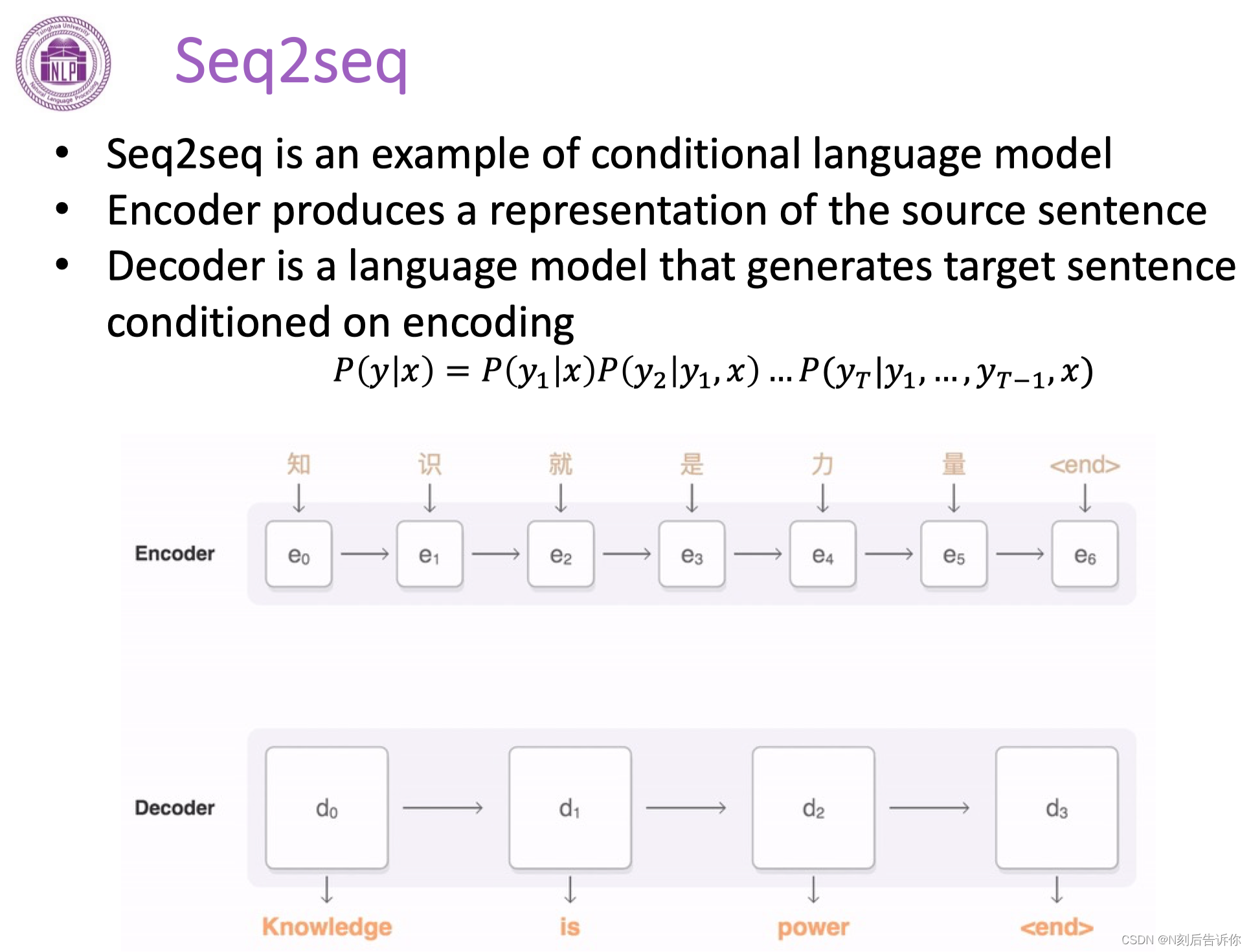
有条件的语言建模

例子:seq2seq

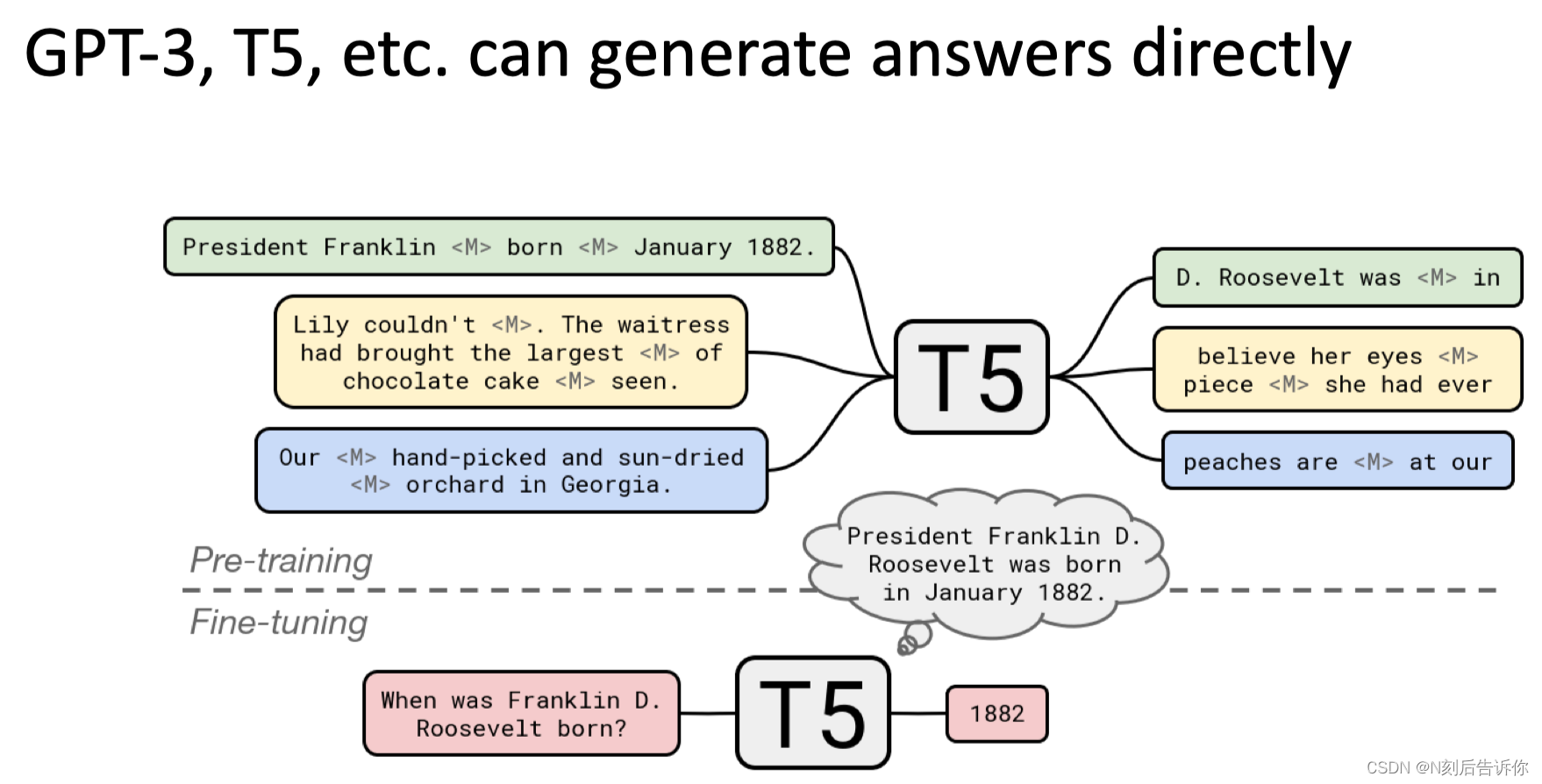
比较知名的模型:T5
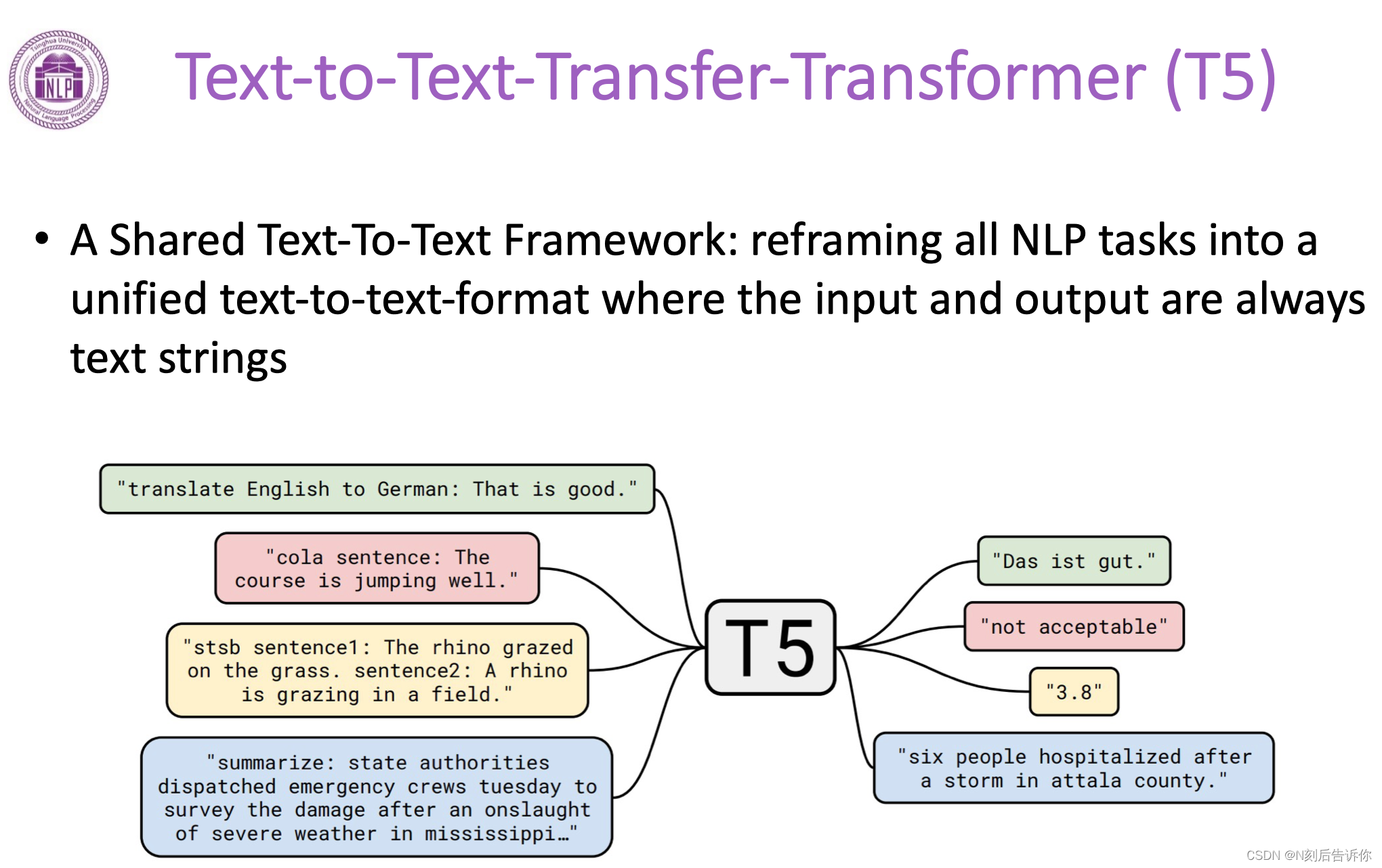
T5是在一个被清洗过的爬取的数据集上训练的。输入时,会将其中一部分mask,

自回归的生成

经典的模型:GPT
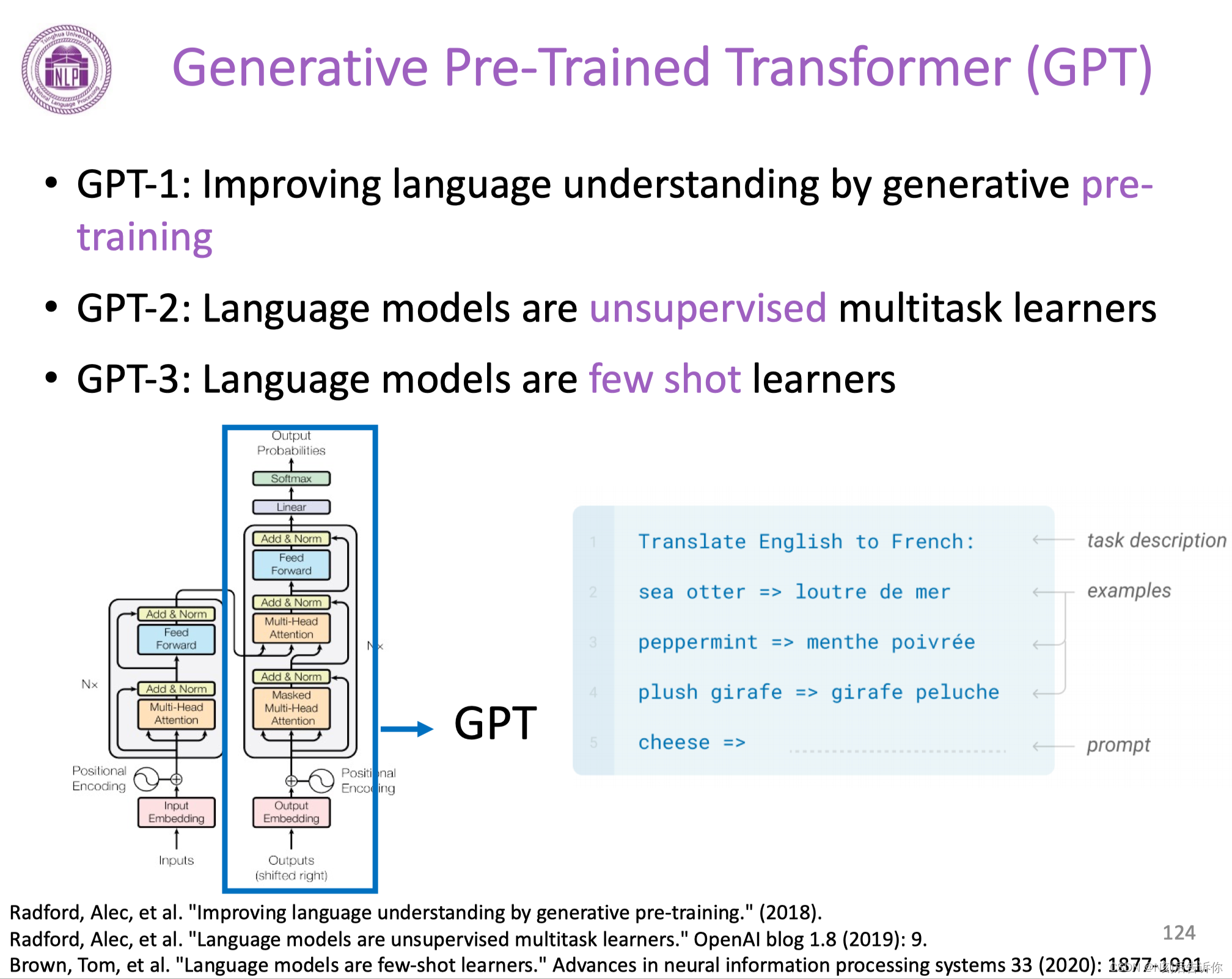
GPT-2

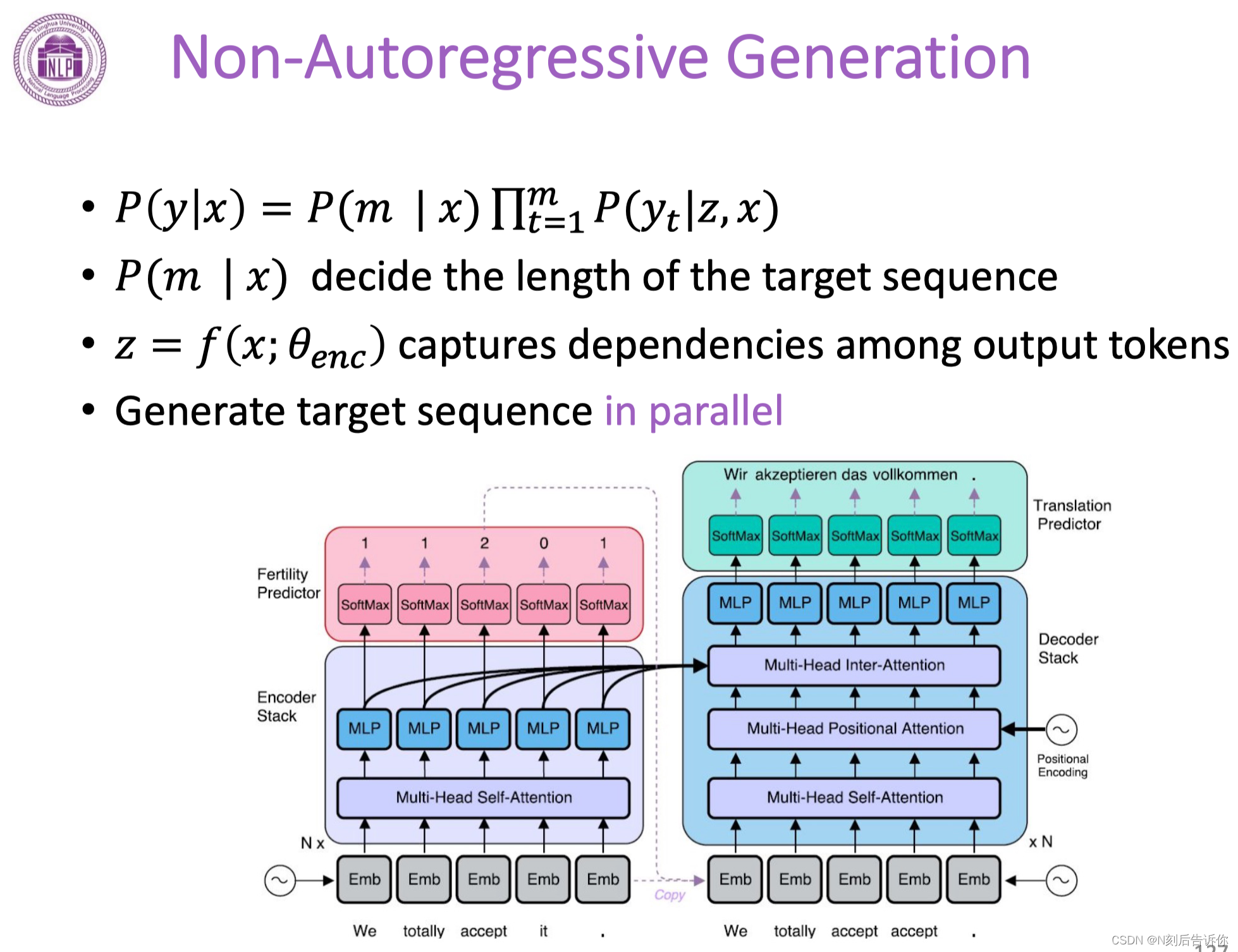
非自回归的生成

非自回归的生成,可以一下子同时生成文本。
解码策略
模型得到的是概率。如何将概率解码得到文本。
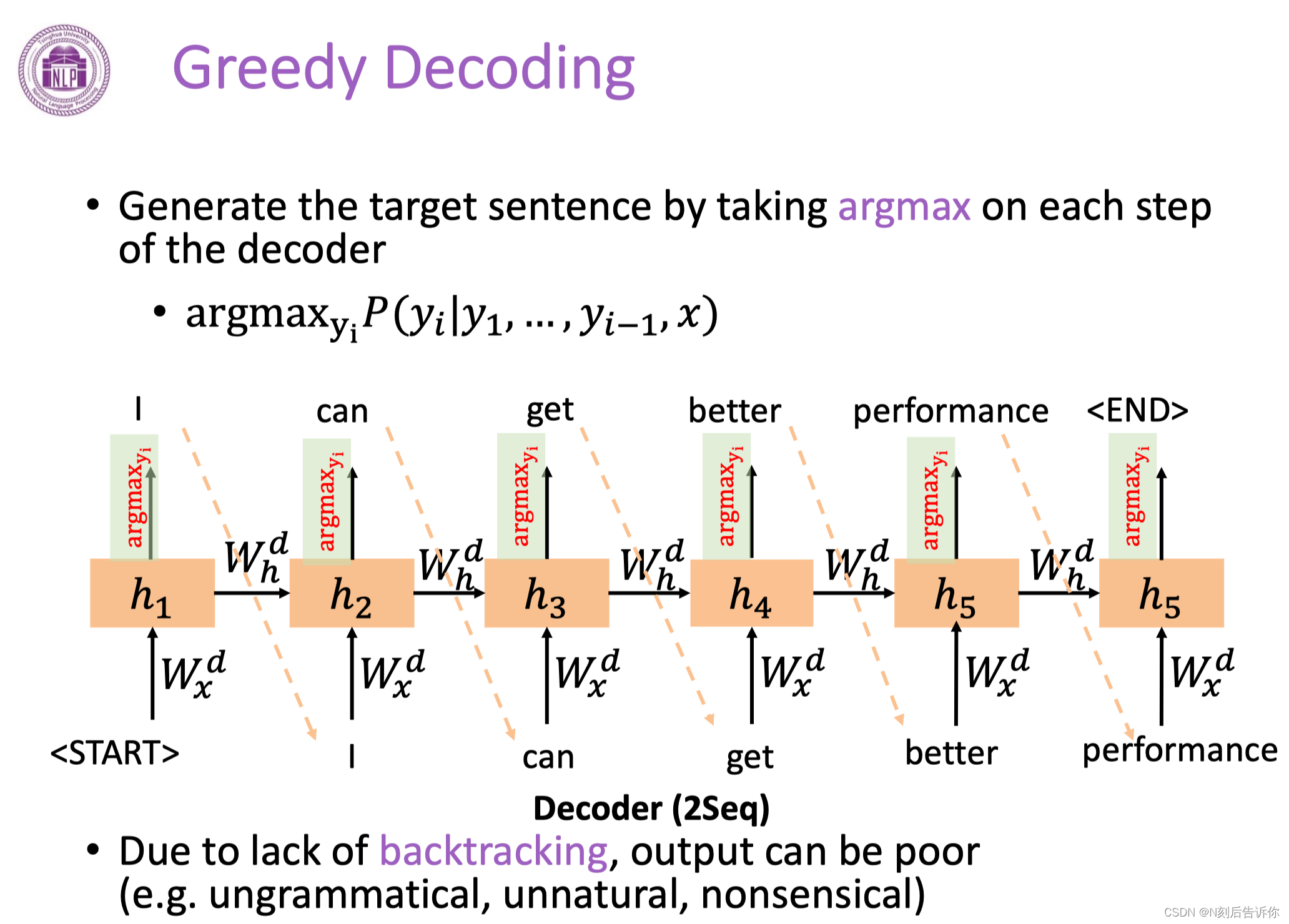
贪心编码-Greedy Decoding
选择概率最大的token。
但是可读性可能比较差。
Beam Search Decoding
寻找一个子序列。但这样只是获得了局部的最优解,并不一定是全局的。

过程演示:
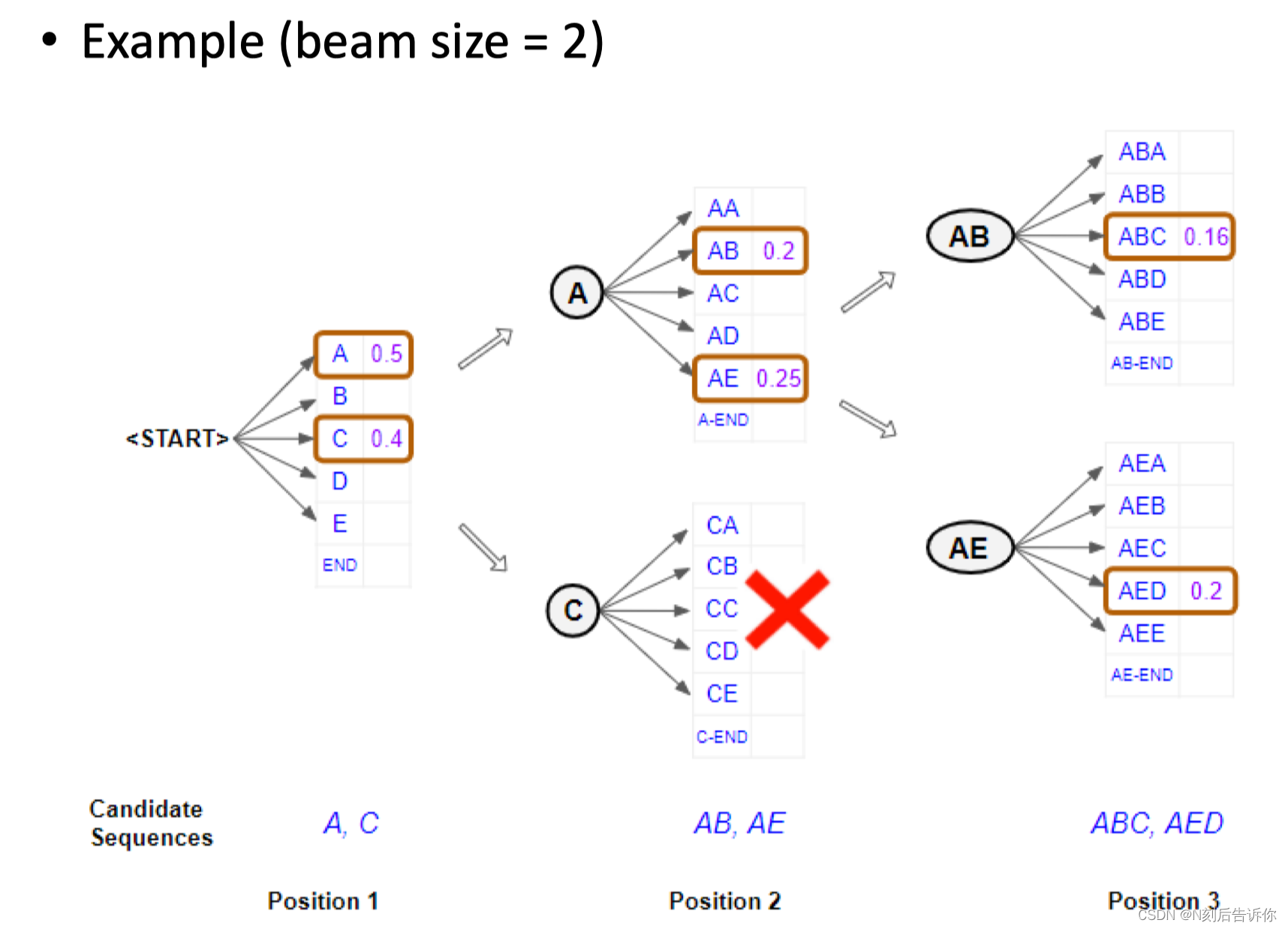
参数k很重要。
增大k的话,会生成更通用,但是和input text更无关的句子。


Sampling-based Decoding
- Pure sampling:随机从词表选token,对于概率大的词以较大概率去选。模型的多样性会大大增加。
为了防止一些概率很小的词出现,又引入top-n和top-p来限制模型生成的范围。
- Top-n sampling:不是在整个词表上采样,而是在n个最有可能概率的词上采样。
- Top-p sampling:首先是概率最大的token,而且这些token的概率加起来大于等于阈值p

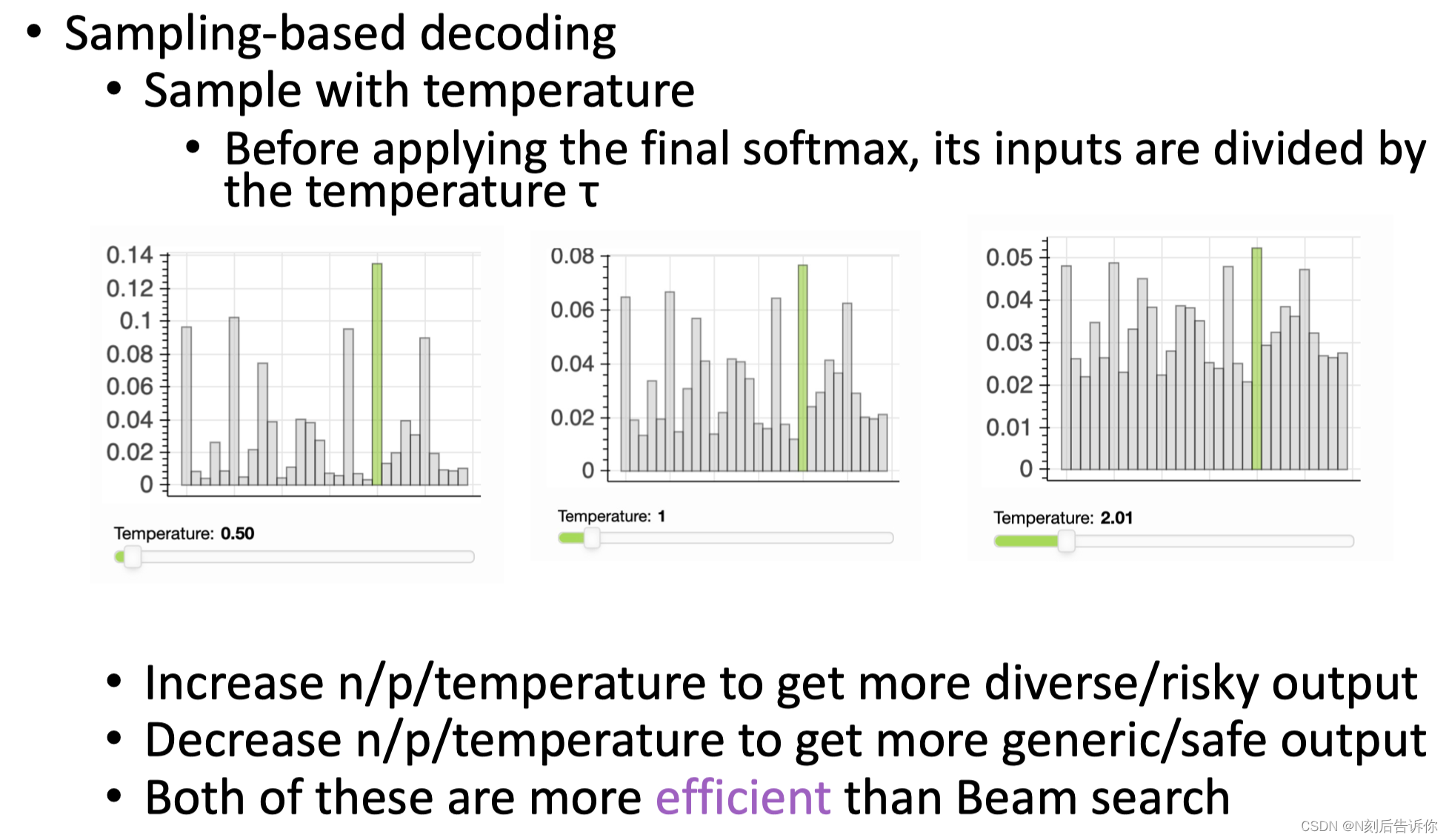
- Sampling with temperature
送入softmax之前会除以一个temperature。不同的temperature对应的是不同的生成策略。
t高,则生成的文本更多样。
t低,则生成的文本更相关。
受控文本生成
如何保持文本控制性和文本质量是一种重要课题。
Prompt methods
- 文本前面加prompt

- 模型前面加prefix
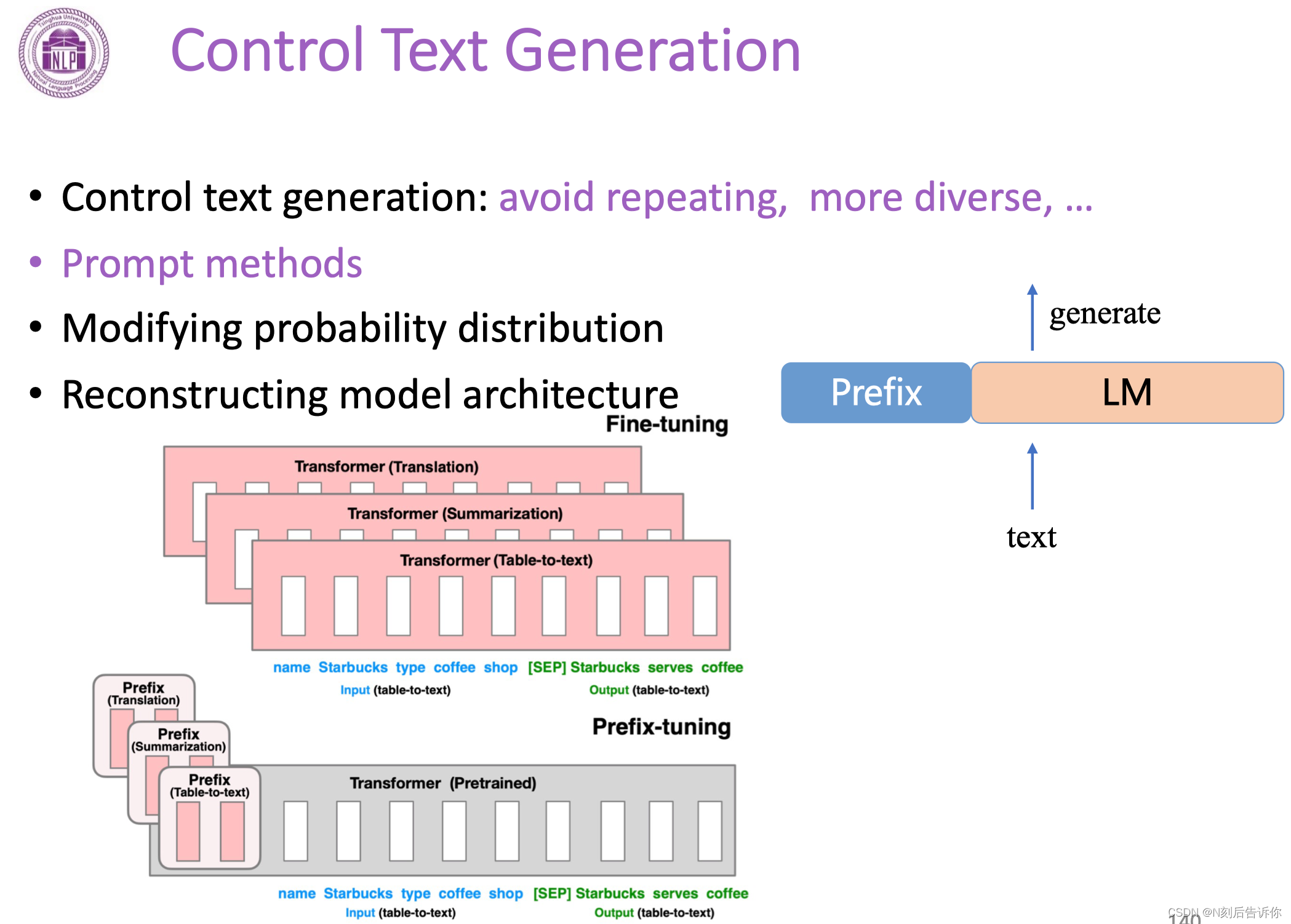
修改概率分布
除了基础模型,还会训练两个模型:生成非歧视文本的天使LM,生成有歧视文本的恶魔LM。
生成的时候希望生成语言的概率贴近天使模型,而去远离恶魔模型。

修改模型结构
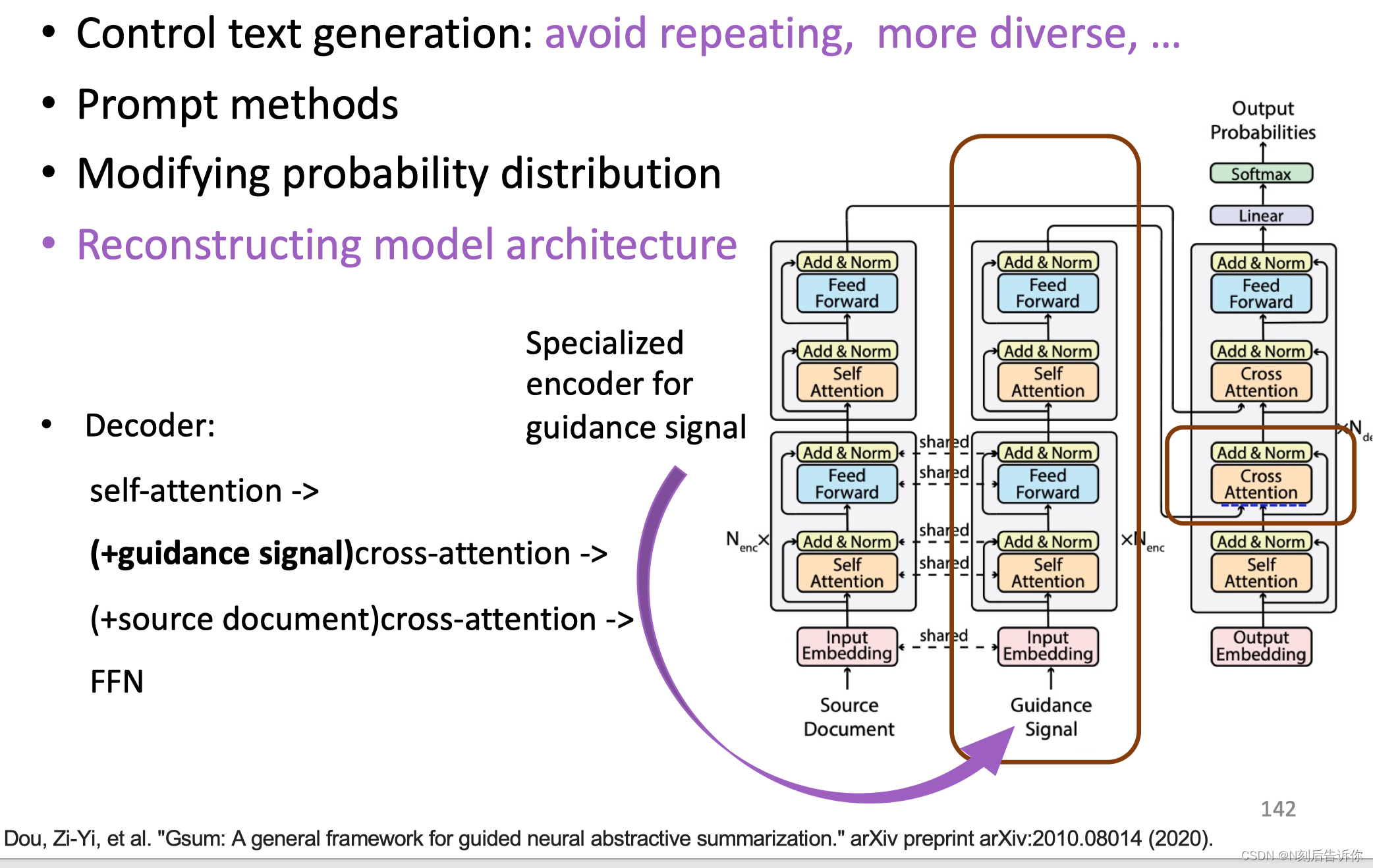
文本生成测评
通用度量
-
BLEU
生成的文本有多少与金标准的文本是类似的。BP是对短句的惩罚。我们希望尽量生成长句。 -
PPL
在测试集上进行计算,会去验证模型有多大概率生成某个sample。PPL越低越好。

翻译和总结的通用度量
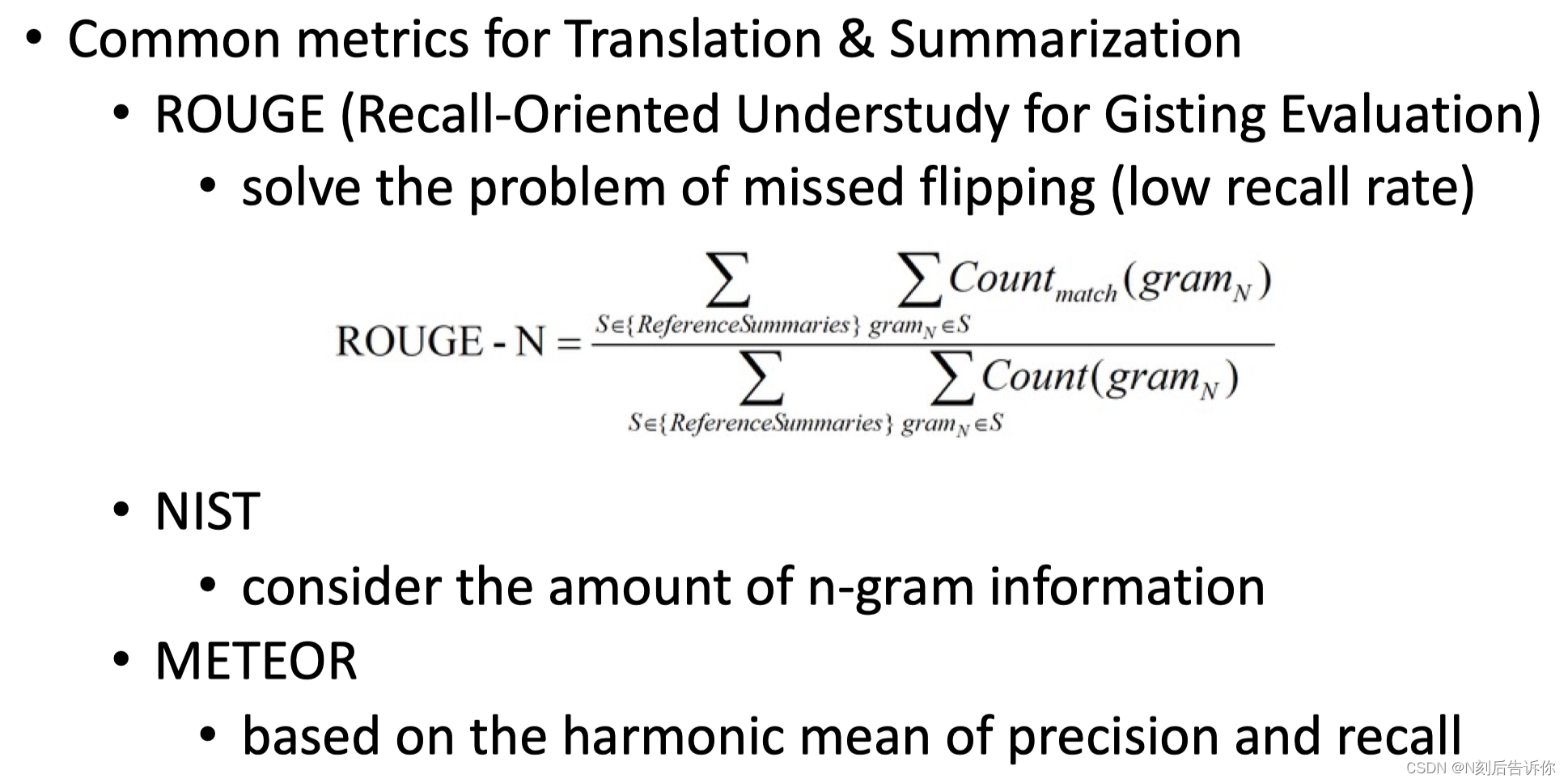
其他度量

文本生成的挑战
-
在训练和模型策略上
总是生成重复的词
在seq2seq中,teacher forcing会引入一些exposure bias。 -
逻辑一致性
缺少逻辑一致性 -
控制性
很难保证有很好的控制性和很好的语言质量 -
评估
合理的度量和数据集
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









