







LR与SVM的相同点:
- *LR和SVM都是分类算法
- *如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
- *LR和SVM都是监督学习算法
- *LR和SVM都是判别模型
–判别模型会生成一个表示p(y|x)的判别函数(或预测模型),
–生成模型先计算联合p(y,x)然后通过贝叶斯公式转化为条件概率。
–常见的判别模式:KNN、SVM、LR,常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。
-*LR和SVM在学术界和工业界都是广为人知并且应用广泛。
LR和SVM的不同:
*本质上是其loss function不同
–逻辑回归的损失函数:
–SVM的损失函数:
调整后为:
当C很大时:w为参数的向量表示,b为第0个参数
等价为:
1,问题就变成了一个凸二次规划问题,可以利用任何现成的QP(二次规划)的优化包进行求解。
2,虽然是一个标准的QP问题,但它也有自己的特殊结构,通过拉格朗日对偶变换成对偶变量的优化问题之后,可以更加有效地求解,也比QP优化包更加高效!
*支持向量机只考虑局部的边界线附近的点,而逻辑回归考虑全局(远离的点对边界线的确定也起作用)。
- *线性SVM依赖数据表达的距离测度,所以需要对数据先做normalization,LR不受其影响
- *SVM的损失函数就自带正则!!!(损失函数中的1/2||w||^2项),这就是为什么SVM就是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!!
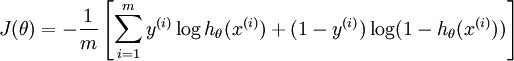
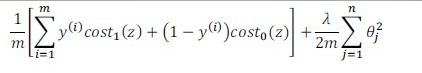
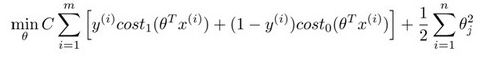
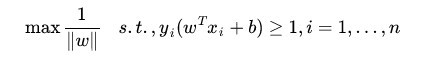
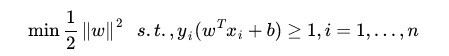
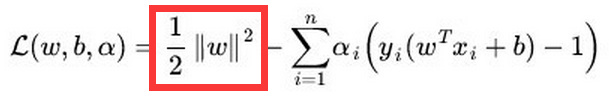















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









