







学习笔记(八)使用stacking模型融合
数据是金融数据,我们要做的是预测贷款用户是否会逾期,表格中,status是标签:0表示未逾期,1表示逾期。
Misson1 - 构建逻辑回归模型进行预测
Misson2 - 构建SVM和决策树模型进行预测
Misson3 - 构建xgboost和lightgbm模型进行预测
Mission4 - 记录五个模型关于precision,rescore,f1,auc,roc的评分表格,画出auc和roc曲线图
Mission5 - 关于数据类型转换以及缺失值处理(尝试不同的填充看效果)以及你能借鉴的数据探索
Mission6 - 交叉验证和网格搜索调参
Mission7 - stacking 融合模型。
数据准备
数据的预处理见前面:https://blog.csdn.net/zhangyunpeng0922/article/details/84346663
但此处将前面处理好的数据转换成数组形式,并用自己写的split来切分数据集。(因为不知道什么原因调用scikit里面的train_test_split的函数切分后会出现空值????)
切分函数
def split(x,y,test_ratic=0.2,seed=None):
assert x.shape[0]==y.shape[0]
assert 0.0<=test_ratic <=1.0
if seed:
np.random.seed(seed)
shuffle_index = np.random.permutation(len(x)) ##乱序排列
test_size = int(len(x) * test_ratic)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
x_train = x[train_index]
y_train = y[train_index]
x_test = x[test_index]
y_test = y[test_index]
return x_train,y_train,x_test,y_test
数据切分和数据的归一化
x_temp = np.array(datafinal)
y_temp = np.array(data_train)
"""
1.3 数据集的切分
"""
import sys
sys.path.append("F:PYCharm\PYcode")
from machine_learning.model_selection import split
x_train,y_train,x_test,y_test = split(x_temp, y_temp,test_ratic=0.3)
"""
1.4标准化数据,方差为1,均值为零
"""
standardScaler = StandardScaler()
X_train_fit = standardScaler.fit_transform(x_train)
X_test_fit = standardScaler.transform(x_test)
模型的初始化
根据前一个任务的调参所得的相对来说较好的参数来初始化模型。
log_reg = LogisticRegression(C=0.1, penalty='l1')
lsvc = SVC(C=5, gamma=0.001)
dtc = DecisionTreeClassifier(max_depth=3)
xgbc_model = XGBClassifier(learning_rate=0.05, max_depth=3)
lgbm_model = LGBMClassifier(learning_rate=0.1, max_depth=3)
使用stacking进行模型融合
1. 使用 mlxtend.classifier中的StackingClassifier
安装;打开,命令提示符。pip install mlxtend;
clfs = {
'log_reg': LogisticRegression(C=0.1, penalty='l1'),
'lsvc': SVC(C=5, gamma=0.001),
'dtc': DecisionTreeClassifier(max_depth=3),
'xgbc_model':XGBClassifier(learning_rate=0.05, max_depth=3),
'lgbm_model':LGBMClassifier(learning_rate=0.1, max_depth=3)
}
log_reg_clf = clfs["log_reg"]
lsvc_clf = clfs["lsvc"]
dtc_clf = clfs["dtc"]
xgbc_model_clf = clfs["xgbc_model"]
lgbm_model_clf = clfs["lgbm_model"]
sclf = StackingClassifier(classifiers=[log_reg_clf, lsvc_clf, dtc_clf,xgbc_model_clf, lgbm_model_clf],
meta_classifier=log_reg_clf)
sclf.fit(X_train_fit, y_train)
pre_train = sclf.predict(X_test_fit)
结果如下:

结果与前面相比有一些提升:之前的结果
2. 参考网络上的stacking代码
stack_model = [log_reg,lsvc,dtc,xgbc_model,lgbm_model] ## 这个地方我是简写,实际这样训练会报错,需要自己导库,定义分类器
## train_data 表示训练集,train_label 表示训练集的标签,test_data表示训练集
ntrain = X_train_fit.shape[0] ## 训练集样本数量
ntest = X_test_fit.shape[0] ## 测试集样本数量
train_stack = np.zeros((ntrain,5)) ## n表示n个模型
test_stack = np.zeros((ntest,5)) ##
kf = KFold(n_splits=5)
#kf = KFold.split(X_train_fit, y_train)
kf2 = kf.split(X_train_fit, y_train)
for i,model in enumerate(stack_model):
for j,(train_fold, validate) in enumerate(kf2):
X_train_kf, X_validate, label_train, label_validate = X_train_fit[train_fold, :], X_train_fit[validate, :], y_train[train_fold], y_train[validate]
print(label_train)
model.fit(X_train_kf,label_train)
train_stack[validate,i] = model.predict(X_validate)
test_stack[:,i] = model.predict(X_test_fit)
final_model = XGBClassifier(learning_rate=0.05, max_depth=3)
final_model.fit(train_stack,y_train)
pre = final_model.predict(test_stack)
score = final_model.score(test_stack, y_test)
结果:
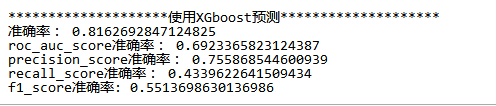
结果与前面相比有一些提升:之前的结果
总结
- 调用scikit里面的train_test_split的函数切分后会出现空值,导致模型无法继续运行。
- 对stacking的原理与运用了解的不深。
- 感觉前面的调参和数据处理并没有做的很好,导致后面的融合之类地感觉没有太大的提升。
参考文章:














 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









