






问题:训练耗时并不大,但数据加载耗时,可进行以下配置
主要是两个参数:pin_memory=True 和 non_blocking=True,原理就是利用 CUDA 多流进行异步传输,也就是在GPU计算的时候进行 CPU=>GPU 间的数据传输。
硕士期间主要做的是高性能计算,所以看了下介绍就理解了,突然发现硕士期间学的 GPU 相关知识还是有点点用的,哈哈哈。

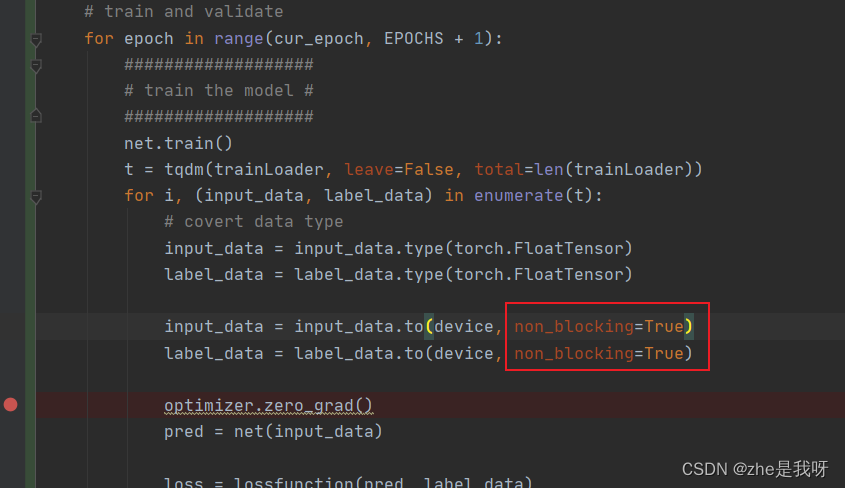
加速效果,还是很明显的。
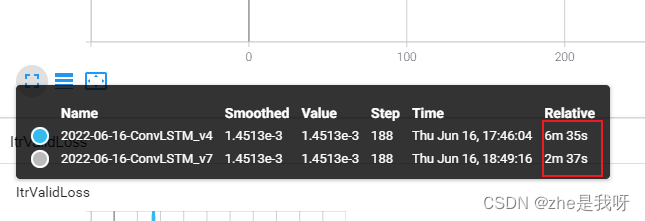
需要注意的是:validate 部分 不需要添加 non_blocking 配置,不然反而会变慢。猜测是因为net.eval() 过程和训练时的区别【瞎猜的,实际上并没发现是为啥】

















 1983
1983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









