







 本文描述了一次利用Python爬取火车票价的过程,从12306的接口难题转向使用智行网站API,通过分析数据筛选出不同城市的直达票价,包括硬座、软卧和高铁等,最终将结果存储在Excel中。
本文描述了一次利用Python爬取火车票价的过程,从12306的接口难题转向使用智行网站API,通过分析数据筛选出不同城市的直达票价,包括硬座、软卧和高铁等,最终将结果存储在Excel中。
概要
记一次协助人资省会直辖市火车票价(硬卧、软卧、二等座、一等座)的爬取。
整体思路
让冲宇准备省会城市+深圳的数据(我们差点还自信的认为吉林省的省会是吉林市,后来由他统一查百度来确认),用python爬取直达火车票价,原则就是如果能用接口就坚决不解析dom。
技术细节
打开12306官网,分析了一下接口,发现接口数据都被混淆了,需要采用selenium来获取dom。这样太麻烦了,换一个网站试一下,就选智行这个网站了
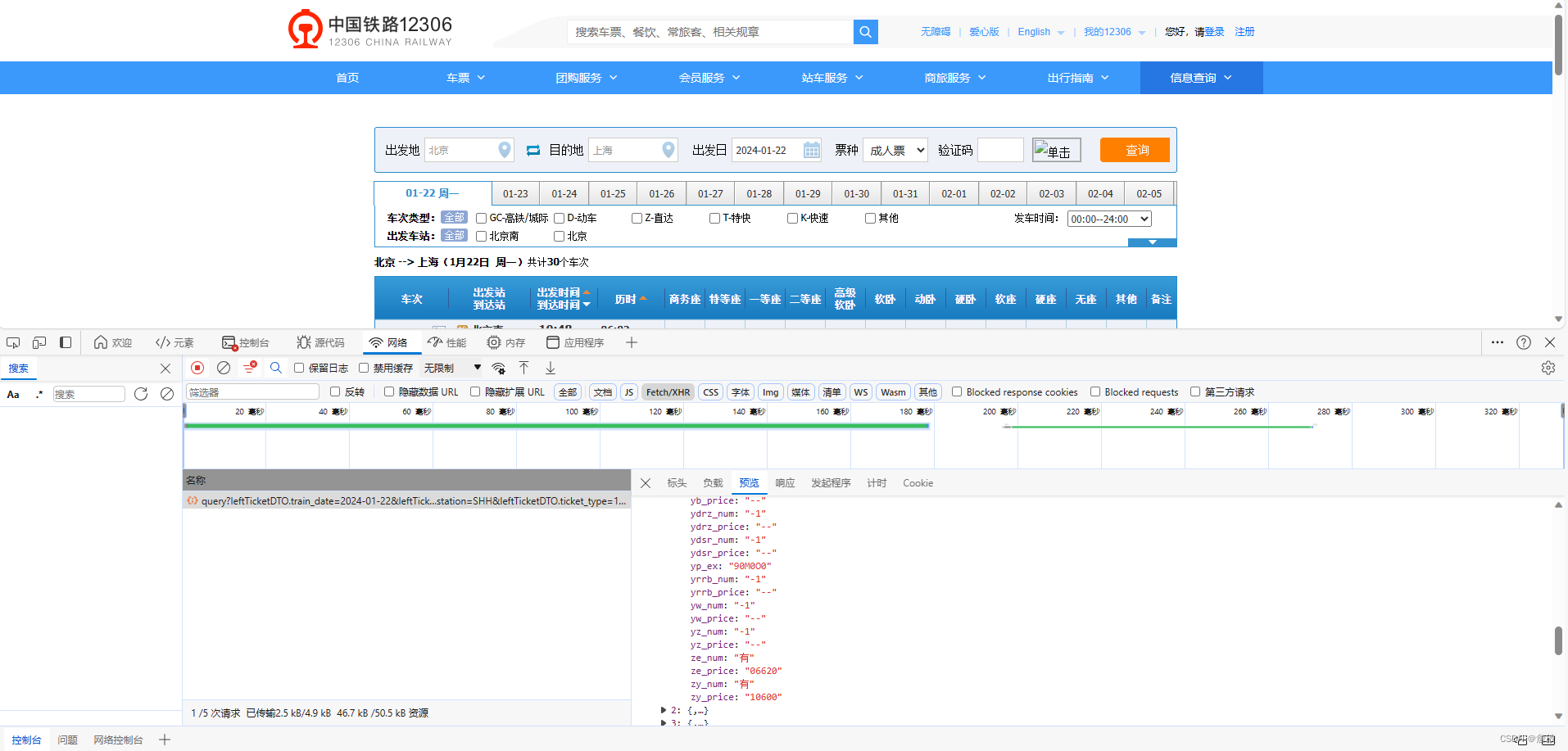
分析了一下接口数据,觉得可以使用
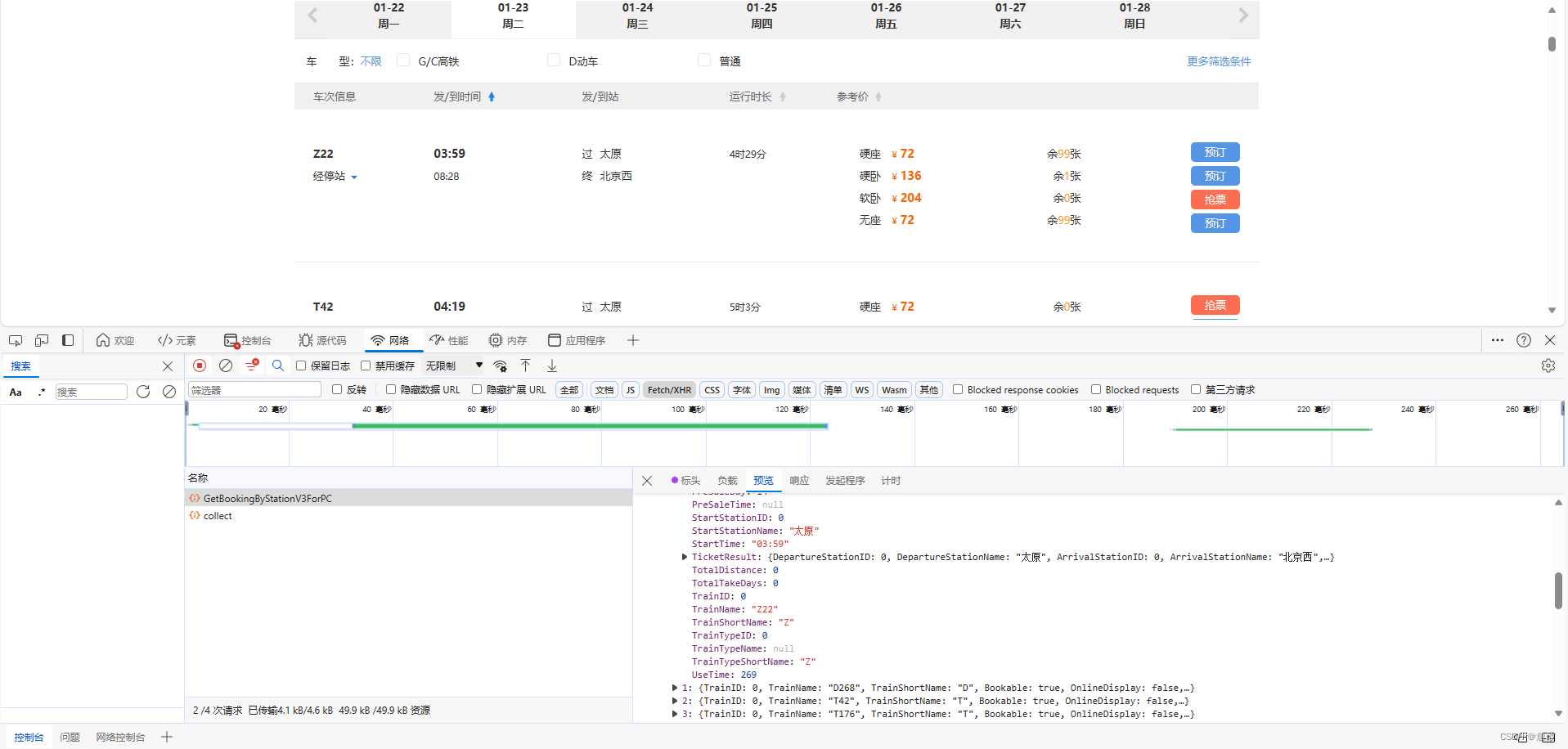
- 实现城市数据双双匹配,去除相同的
cities = ["深圳", "上海", "昆明", "呼和浩特", "北京", "长春", "成都", "天津", "银川", "合肥", "济南", "太原",
"广州",
"南宁", "乌鲁木齐", "南京", "南昌", "石家庄", "郑州", "杭州", "海口", "武汉", "长沙", "兰州", "福州",
"贵阳",
"沈阳", "重庆", "西安", "西宁", "哈尔滨"]
date = "2024-01-23"
result_data = []
for city1 in cities:
for city2 in cities:
if city1 == city2:
continue
print(f"{city1} - {city2}")
- 封装接口请求
def get_train_data(city1, city2, date):
data = {
"DepartStation": city1,
"ArriveStation": city2,
"DepartDate": date,
"ChannelName": "ctrip.pc"
}
url = "https://m.ctrip.com/restapi/soa2/14666/json/GetBookingByStationV3ForPC"
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/json;charset=UTF-8",
"sec-ch-ua": "\"Not_A Brand\";v=\"8\", \"Chromium\";v=\"120\", \"Microsoft Edge\";v=\"120\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"Referer": "https://suanya.ctrip.com/",
"Referrer-Policy": "strict-origin-when-cross-origin"
}
response = requests.post(url, headers=headers, data=json.dumps(data))
json_data = json.loads(response.text)
train_items = json_data.get('ResponseBody', {}).get('TrainItems', [])
return train_items
- 分析接口数据,发现普通绿皮车和高铁的区别以TrainShortName来区分
list_t = [item for item in train_items if item["TrainShortName"] not in ('D', 'G')]
- 删选最便宜的票价,以硬座价格||2等座为参考
min_price_data_g = min(new_data_g, key=lambda x: x["Price2"])
- 小插曲,程序运行报错,数组越界,后来发现部分车次只有软卧,就直接过滤掉
new_data_g = [extract_min_price_by_g_data(i) for i in list_g if
len(i["TicketResult"]["TicketItems"]) >= 3]
- 最后整体代码
import json
import time
import pandas as pd
import requests
def get_train_data(city1, city2, date):
data = {
"DepartStation": city1,
"ArriveStation": city2,
"DepartDate": date,
"ChannelName": "ctrip.pc"
}
url = "https://m.ctrip.com/restapi/soa2/14666/json/GetBookingByStationV3ForPC"
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/json;charset=UTF-8",
"sec-ch-ua": "\"Not_A Brand\";v=\"8\", \"Chromium\";v=\"120\", \"Microsoft Edge\";v=\"120\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"Referer": "https://suanya.ctrip.com/",
"Referrer-Policy": "strict-origin-when-cross-origin"
}
response = requests.post(url, headers=headers, data=json.dumps(data))
json_data = json.loads(response.text)
train_items = json_data.get('ResponseBody', {}).get('TrainItems', [])
return train_items
def extract_min_price_by_t_data(d):
item = d['TicketResult']
return {
"TrainName": d["TrainName"],
"StartStationName": item["DepartureStationName"],
"EndStationName": item["ArrivalStationName"],
"SeatTypeNameYw": item["TicketItems"][1]['SeatTypeName'],
"PriceYw": item["TicketItems"][1]['Price'],
"SeatTypeNameRw": item["TicketItems"][2]['SeatTypeName'],
"PriceRw": item["TicketItems"][2]['Price'],
}
def extract_min_price_by_g_data(d):
item = d['TicketResult']
return {
"TrainName": d["TrainName"],
"StartStationName": item["DepartureStationName"],
"EndStationName": item["ArrivalStationName"],
"SeatTypeName2": item["TicketItems"][0]['SeatTypeName'],
"Price2": item["TicketItems"][0]['Price'],
"SeatTypeName1": item["TicketItems"][1]['SeatTypeName'],
"Price1": item["TicketItems"][1]['Price'],
}
def main():
cities = ["深圳", "上海", "昆明", "呼和浩特", "北京", "长春", "成都", "天津", "银川", "合肥", "济南", "太原",
"广州",
"南宁", "乌鲁木齐", "南京", "南昌", "石家庄", "郑州", "杭州", "海口", "武汉", "长沙", "兰州", "福州",
"贵阳",
"沈阳", "重庆", "西安", "西宁", "哈尔滨"]
date = "2024-01-23"
result_data = []
for city1 in cities:
for city2 in cities:
if city1 == city2:
continue
print(f"{city1} - {city2}")
train_items = get_train_data(city1, city2, date)
if not train_items:
continue
list_t = [item for item in train_items if item["TrainShortName"] not in ('D', 'G')]
new_data = [extract_min_price_by_t_data(i) for i in list_t if len(i["TicketResult"]["TicketItems"]) >= 3]
min_price_data_t = None
if new_data:
min_price_data_t = min(new_data, key=lambda x: x["PriceYw"])
print(f"{city1} - {city2}", min_price_data_t)
list_g = [item for item in train_items if item["TrainShortName"] == 'G']
if list_g:
new_data_g = [extract_min_price_by_g_data(i) for i in list_g if
len(i["TicketResult"]["TicketItems"]) >= 3]
if new_data_g:
min_price_data_g = min(new_data_g, key=lambda x: x["Price2"])
if new_data:
min_price_data_g.update({
"TrainNameT": min_price_data_t['TrainName'],
"SeatTypeNameYw": min_price_data_t['SeatTypeNameYw'],
"PriceYw": min_price_data_t['PriceYw'],
"SeatTypeNameRw": min_price_data_t['SeatTypeNameRw'],
"PriceRw": min_price_data_t['PriceRw']
})
print(f"{city1} - {city2}", min_price_data_g)
result_data.append({"City1": city1, "City2": city2, **min_price_data_g})
elif min_price_data_t:
result_data.append({"City1": city1, "City2": city2, **min_price_data_t})
print("防封ip,系统休眠一会儿......")
time.sleep(1)
df = pd.DataFrame(result_data)
excel_filename = "min_price_data_results.xlsx"
df.to_excel(excel_filename, index=False)
print(f"Results written to {excel_filename}")
if __name__ == "__main__":
main()
- 运行效果
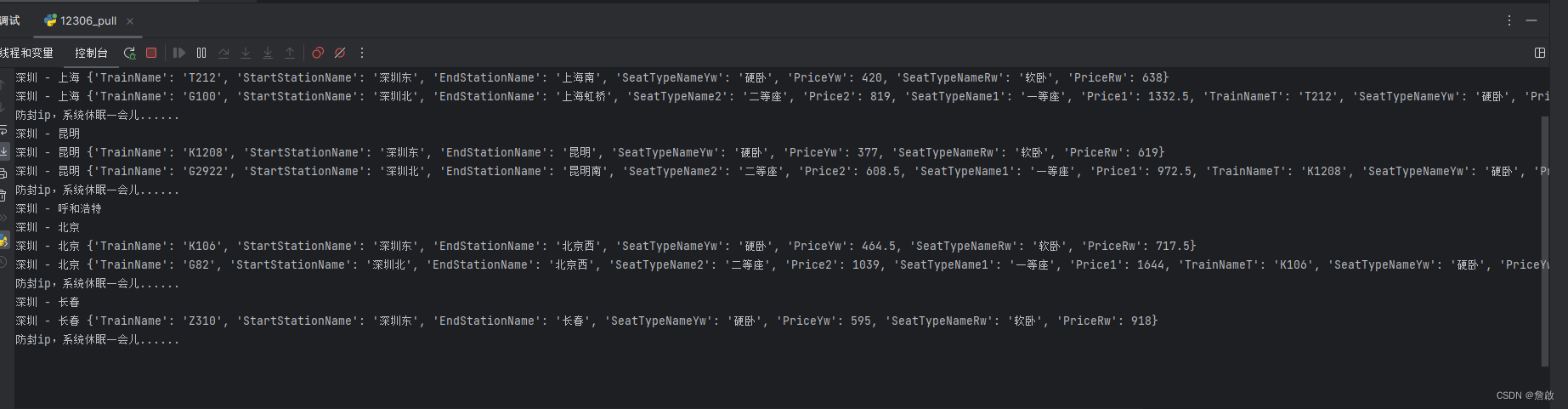
- 第一次生成的excel存在重复数据,因为每次运行时间比较久,解决完bug后就没有再次运行了,十分感谢张念帮忙处理了一下excel,最后整理成如下:
小结
方便他人就是方便自己

















 3319
3319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









