







一、前言
1、摘要
现有的对比学习方法大多采用预先定义的视图生成方法,如节点下降或边缘扰动等,通常不能很好地适应输入数据或保持原始语义结构。
为了解决这个问题,本文中提出了一个新的框架,称为自动图形对比学习(AutoGCL)。
具体来说,AutoGCL采用了一组由自动增强策略编排的可学习图视图生成器,其中每个图视图生成器学习受输入条件制约的图的概率分布。
AutoGCL中的图视图生成器在生成每个对比样本时保留了原始图中最具代表性的结构,而自动增强在整个对比学习过程中学习策略以引入足够的增强方差。此外,AutoGCL采用联合训练策略,对可学习视图生成器、图编码器和分类器进行端到端的训练,导致对比样本的生成具有拓扑异质性,但语义相似。
2、介绍
在这项工作中,提出了一种可学习的图视图生成方法,即AutoGCL,通过学习节点级增强的概率分布来解决上述问题。
传统的预定义视图生成方法,如随机dropout或图节点掩蔽等,不可避免地会改变图的语义标签,最终损害对比学习。
而AutoGCL适应于输入图,可以很好地保留图的语义标签。
(1)由于gumbel-softmax技巧, AutoGCL是端到端可微的,同时为对比样本生成提供了足够的方差。
(2)提出了一种联合训练策略,以端到端的方式训练可学习视图生成器、图形编码器和分类器。该策略包括视图相似度损失、对比损失和分类损失。它使所提出的视图生成器生成具有相似语义信息但具有不同拓扑属性的增强图。
在表1中,总结了现有图增强方法的性质,其中AutoGCL在比较中占主导地位。

贡献可以总结如下。
•提出了一个图形对比学习框架,将可学习的图形视图生成器嵌入到自动增强策略中。据我们所知,这是第一个为图对比学习构建可学习的生成式节点增强策略的工作。
•提出了一种联合训练策略,用于在图对比学习的背景下以端到端方式训练图视图生成器、图编码器和图分类器。
•在各种具有半监督、无监督和迁移学习设置的图分类数据集上广泛评估所提出的方法。t-SNE和视图可视化结果也证明了该方法的有效性
3、相关工作
(1)图神经网络
将一个图表示为g = (V, E),其中对于V∈V,节点特征为xv。在本文中,我们重点研究了使用图神经网络(GNNs)的图分类任务。
gnn通过聚合邻居节点特征xv,生成节点级嵌入hv。gnn的每一层都作为聚合的迭代,这样第k层之后的节点嵌入将其k跳邻域内的信息聚合。gnn的第k层可以表示为

这个就是GNN网络的消息传递的过程,没啥说的
图分类等下游任务,通过READOUT函数和MLP层获得图级表示

使用两个最先进的gnn,即GIN (Xu et al 2018)和ResGCN (Chen, Bian, and Sun 2019)作为骨干gnn。选择合适的编码器
(2)对比学习
近年来,对比学习(CL)在自监督学习方法中备受关注,包括SimCLR (Chen et al 2020a)和MoCo-v2 (Chen et al 2020b)在内的一系列对比学习方法甚至优于监督基线。通过最小化对比损失(Hadsell, Chopra, and LeCun 2006),从相同输入生成的视图(即正面视图)对)在表示空间中被拉近,而不同输入的视图(即负视图对)则被推远。
DGI (V eliˇckovi´c et al 2018)将同一图的图级和节点级表示视为正视图对,而不是数据增强。CMRLG (Hassani and Khasahmadi 2020)通过将邻接矩阵和扩散矩阵视为正对来实现类比目标。最近,GraphCL框架(You et al2020a)采用了四种类型的图增强,
包括
1、节点下降、边缘扰动
2、子图采样
3、节点属性掩码
随机屏蔽一定比例的节点属性。
将一定比例的边随机替换为随机边。
随机选择一个一定大小的连通子图
实现了迄今为止最多样化的图视图生成增强。GCA (Zhu et al 2020b)使用子图采样和节点属性掩蔽作为增强,并引入了基于节点中心性度量的先验增强概率,使其比GraphCL (Y ou et al . 2020b)更具适应性2020a),但先验是不可学的。
二、AutGCL模型
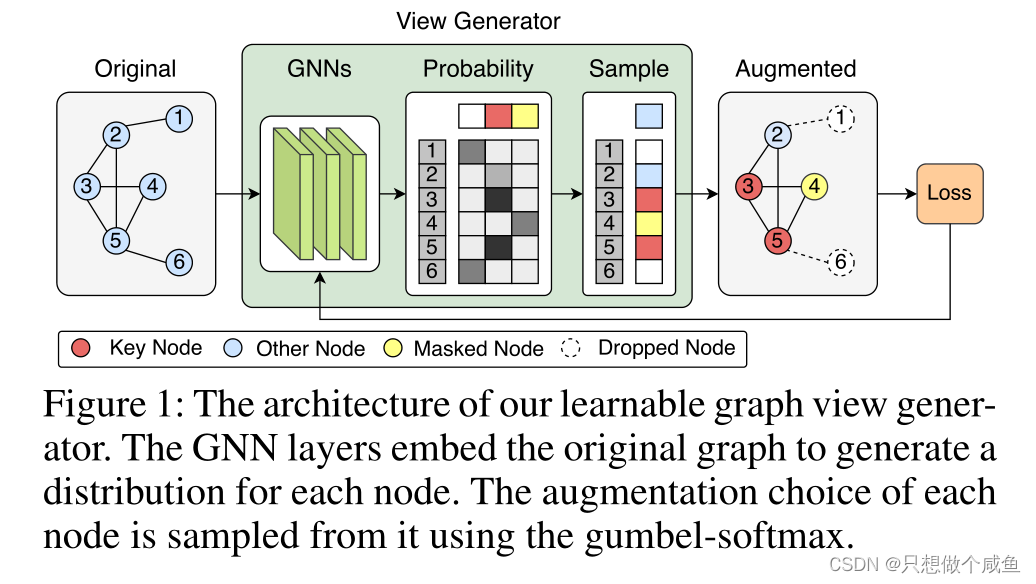
1、什么是一个好的图视图生成器
一个理想的用于数据增强和对比学习的图视图生成器应该满足以下特性:
(1)它既支持图拓扑的增强,也支持节点特征的增强。
(2)它是标签保留的,即增广图要保持原图中的语义信息。
(3)对不同的数据分布具有自适应能力,可扩展到大图。
(4)为对比多视角预训练提供了足够的方差。
(5)它是端到端可微的,对于通过反向传播(BP)进行快速梯度计算足够有效。
在这项工作中,提出了一个可学习的视图生成器来解决上述所有问题。我们的视图生成器包括节点删除和属性屏蔽的增强,但它更灵活,因为这两种增强可以以节点方式同时使用,而不需要调优“aug ratio”。
2、可学习的图形视图生成器
使用GIN层从节点属性中获得节点嵌入。为每一个节点,使用嵌入节点特征来预测选择某个增强操作的概率。每个节点的增强池分别为drop、keep和mask。使用gumbel-softamx从这些概率中采样,然后为每个节点分配一个增强操作。
用h(k)v表示节点v在第k层的隐藏状态,用a(k)v表示节点v在第k层之后的嵌入。对于节点v,我们有节点特征xv,增强选择fv,以及用于应用增强的函数Aug(x, f)。得到节点v的增广特征x0v

最后一层k的维数设置为每个节点可能的增强策略个数相同。表示选择每种增强的概率分布。
是通过gumbel-softmax从这个分布中采样的一个热向量,增强应用函数Aug(xv, fv)使用可微操作(例如乘法)组合节点属性xv和fv
3、对比学习模块
定义了三个损失函数,对比损失Lcl,相似损失Lsim和分类损失Lcls。
(1)定义相似度函数sim(z1, z2)为

在视图生成过程中,我们有一个抽样状态矩阵S,表示每个节点对应的增强操作,将每个视图生成器的抽样增强选择矩阵表示为A1, A2,然后我们将相似损失Lsim表示为

(2)定义对比学习损失

相似损失用于最小化两个视图生成器生成的视图之间的相互信息。在视图生成过程中,我们有一个抽样状态矩阵S,表示每个节点对应的增强操作。对于图G,我们将每个视图生成器的抽样增强选择矩阵表示为A1, A2,然后我们将相似损失Lsim表示为
![]()
后将分类损失Lcls表示为
![]()

4、额外的实验
(1)GraphCL增强的一个洞察
在之前的所有工作中,GraphCL (Y ou et al 2020a)实现了迄今为止最灵活的一组图数据增强,因为它包括节点删除、边缘扰动、子图和属性屏蔽。
•节点随机删除一定比例的节点。
•边缘扰动首先随机移除一定比例的边,然后随机添加相同数量的边。
•子图随机选择一个连通的子图,首先随机选择一个中心节点,然后逐渐添加它的邻居节点,直到达到总节点的一定比例。
•节点属性屏蔽随机屏蔽一定比例的节点属性。
注意到,所有现有作品中唯一的增强选择策略是统一采样,所有的增强方法都需要一个超参数“aug比率”,以控制选择用于增强的节点/边的部分。“aug比率”在每个实验中都被设置为常数
•边缘扰动和子图增强对图对比学习的积极贡献非常有限(甚至是消极的)。
•子图的增强实际上包含在节点下降的增强空间中。例如,删除80%节点的潜在视图空间包含选择包含20%节点的连通子图的潜在视图空间。
•“aug比率”的选择对最终性能有相当大的影响。将相同的“aug比率”应用于不同的增强、数据集和任务是不合适的。
(2)有效性
证明了可学习图增强策略比固定图增强策略的优越性
因为我们唯一的拓扑增强是节点下降。因此,比较了Graphic的节点下降增强视图,并使用默认设置aug ratio = 2。视图生成器更有可能保留原始图中的关键节点,保留其语义特征,同时为对比学习提供足够的方差。
三、总结
在本文中,提出了一种用于图对比学习的可学习数据增强方法,其中我们使用GIN生成原始图的不同视图。为了保留输入图的语义标签,我们开发了一种联合学习策略,交替优化视图生成器、图编码器和分类器。还在许多数据集和任务上进行了广泛的实验,如半监督学习、无监督学习和迁移学习,结果证明了提出的方法在大多数数据集和任务上优于同行。此外,将生成的图视图可视化,可以保留输入图的判别结构,有利于分类。
最后,t-SNE可视化结果表明,所提出的联合训练策略可能是半监督图表示学习的更好选择。














 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









