







上一篇:05 Classification-学习笔记-李宏毅深度学习2021年度
下一篇:07 Self Attention-学习笔记-李宏毅深度学习2021年度
本节内容及相关链接
CNN的相关概念
课程笔记
卷积神经网络(Convolutional Neural Network,CNN)是专门为图片识别设计的,当然也可以用在其他的任务上
卷积层:将图片各区域依次与多个Filter进行内积(inner product)操作,最终获取一个新的图片
Filter: 一个( h × w × channels h\times w \times \text{channels} h×w×channels )的Tensor,通常宽高一致,且不宜过大,取 3 × 3 × channels 3\times 3 \times \text{channels} 3×3×channels 即可,其中channel要和图片的channel保持一致
Filter是用来提取图片的特征的
例如,对一张彩色图片做卷积,则Filter的维度可以设置为:
3
×
3
×
3
3\times 3 \times 3
3×3×3
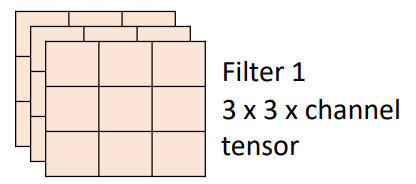
Filter也是有bias的,一个Filter有一个Bias,只不过通常不
stride:步长,只卷积过程中,Filter每次往后移动多少步;stride通常不会太大,1或2即可
卷积后生成的图片矩阵称为Feature Map
卷积的过程,可以使用神经网络完成

- Filter中的数对应神经网络的权重
- 图片中的数对应神经网络的输入
- 多个Filter相当于有多个神经元
Subsample(下采样): 将图片缩小,减小参数个数。在CNN中,称为Pooling
最常见的Pooling策略:
- Max-Pooling:在某区域的像素中,采取像素值最大,其他的都丢弃
整个CNN过程如下:
- 将图片转为Tensor
- 使用多个Filter对图片Tensor进行卷积
- 对卷积后的Feature Map进行Pooling,也可以不进行Pooling,视情况而定
- 可以对(2),(3)步进行多次
- 将Tensor转为Vector,即将图片拉平,该动作称为Flatten
- 将第5步生成的Vector输入到Fully Connected Neural Network,进行接下来的事情

CNN的局限:泛化能力差,例如对图片进行放大后,可能就识别不出来了

假设都是使用第一种类型的图片进行训练,那么CNN对第二种就无法识别
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











