







上一篇:06 卷积神经网络CNN-学习笔记-李宏毅深度学习2021年度
本文内容
Self-Attention及Multi-head Attention的相关概念
课堂笔记
序列模型的种类:
1. 输入是一个Vector,输出是Scalar或Class
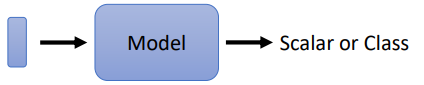
2. 输入是一组Vector (数量不一定固定) ,输出是Scalar 或 Class

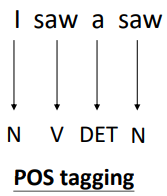
3. 输入一组Vector,输出一组Vector,输入Vector的个数与输出Vector的个数一致。例如词性标注(POS Tagging)

4. 输入是一组Vector,输出是一个Label。例如情感分析(Sentiment Analysis)


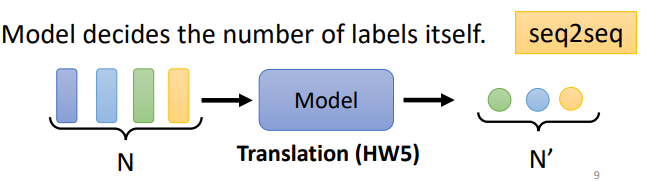
5. 输入是一组Vector,输出是一组Vector,但输出的Vector的长度由机器自己决定。例如:翻译(Translation)
普通神经网络的弊端:对于输入向量,无法考虑其上下文。例如,对于I saw a saw(我看到了一把斧子)这个句子直接输入神经网络,它很难识别出第一个saw和第二个saw意思是不一样的。
Self-Attention的作用:将输入向量重新编码,生成一个考虑了上下文的新向量

Self-Attention可以叠加多层

Self-Attention核心设计思路:每个输入都会和其他输入计算一个相关性分数,然后基于该分数,加权平均得出包含上下文信息的新向量
公式为: b i = ∑ j α i , j ⋅ v i b_i = \sum_j \alpha_{i,j} \cdot v^i bi=j∑αi,j⋅vi
- b i b_i bi 为第 i i i 个包含上下文的输出向量
- α i , j \alpha_{i,j} αi,j 为第 i i i 输入向量和第 j j j 个输入向量的相关性分数,分数越大,相关性越高
- v i v^i vi 为经过处理的第 i i i 个输入向量

α i , j \alpha_{i,j} αi,j 的计算公式为: α i , j = q i ⋅ k j \alpha_{i,j} = q^i\cdot k^j αi,j=qi⋅kj
其中, q i = W q ⋅ a i k j = W k ⋅ a j q^i = W^q \cdot a^i \\\\ k^j=W^k \cdot a^j qi=Wq⋅aikj=Wk⋅aj
- W q W^q Wq 和 W k W^k Wk 为要训练的矩阵
- a i a^i ai 为输入向量
所有的 α \alpha α 计算完毕后,通常还要经过softmax进行归一化,也可以采用其他方式

v i v^i vi 的公式为: v i = W v ⋅ a i v^i= W^v \cdot a^i vi=Wv⋅ai
- W v W^v Wv 是要训练的矩阵

将 ( q 1 , . . . , q i , . . . ) (q^1, ..., q^i, ...) (q1,...,qi,...) 合成矩阵 Q Q Q
将 ( k 1 , . . . , k i , . . . ) (k^1, ..., k^i, ...) (k1,...,ki,...) 合成矩阵 K K K
将 ( a 1 , . . . , a i , . . . ) (a^1, ..., a^i, ...) (a1,...,ai,...) 合成矩阵 I I I
则 Q Q Q 的公式为: Q = W q ⋅ I Q=W^q \cdot I Q=Wq⋅I
K K K 的公式为: K = W k ⋅ I K=W^k \cdot I K=Wk⋅I
V V V 的公式为: V = V k ⋅ I V=V^k \cdot I V=Vk⋅I
Attention公式为: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention (Q,K,V)=softmax(dkQKT)V
d k d_{k} dk 为输入向量的个数, d k \sqrt{d_{k}} dk 的目的是将对标准差进行归一化
Self-Attention 使用总结:
1. 定义矩阵 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv
2. 计算出 Q , K , V Q,K,V Q,K,V
3. 带入 Attention ( Q , K , V ) \operatorname{Attention}(Q,K,V) Attention(Q,K,V) 得到输出向量即可
Multi-head Self-Attention: 只用一套 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv 泛化能力较差,所以采用多套 W q , i , W k , i , W v , i W^{q,i}, W^{k,i}, W^{v,i} Wq,i,Wk,i,Wv,i, i i i 表示第 i i i 套 W W W,换句话说,一个 a i a^i ai 计算出多个 q i , ⋅ , k i , ⋅ , v i , ⋅ q^{i, \cdot}, k^{i, \cdot}, v^{i, \cdot} qi,⋅,ki,⋅,vi,⋅,然后计算出多个 b i , ⋅ b^{i, \cdot} bi,⋅

最后再通过 W O W^O WO 将 b i , ⋅ b^{i,\cdot} bi,⋅ 合并

Self-Attention的弊端:没有考虑输入向量的位置信息。 即只考虑了输入向量上下文都有哪些向量,但没有考虑当前向量所处的位置。例如,I saw a saw 对 I 进行编码时,只知道要把saw a saw 考虑进来,但并没有考虑 I 是处在句子的第一个位置
解决方案:为输入向量加上一个向量 e i e^i ei,即 a i = e i + a i a^{i} = e^i+a^i ai=ei+ai
e i e^i ei 的指定策略:1. 手工指定 2. 通过数据学习出来
Self-Attention的应用:最常用于 NLP 任务中,例如 Transformer 和 BERT。 也可以用于图像领域和语音识别领域。
















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











