







 OpenAI的ChatGPT新增了记忆存储功能,允许用户控制其记住对话内容,这对于长对话和个性化服务如写作、学习和编程有显著帮助。同时,用户可以自主管理数据安全,选择开启或关闭记忆功能。
OpenAI的ChatGPT新增了记忆存储功能,允许用户控制其记住对话内容,这对于长对话和个性化服务如写作、学习和编程有显著帮助。同时,用户可以自主管理数据安全,选择开启或关闭记忆功能。
2月14日凌晨,OpenAI在官网宣布,正在测试ChatGPT记住用户提问内容的能力,同时可以自由控制其内存。
该功能使用户不必频繁地提问相同的内容,ChatGPT都将记住那些内容并对长对话、个性化聊天等,例如,写长文小说;长期健康追踪;个性化编程习惯等,起到巨大帮助。
自定义GPTs也支持该功能。目前,部分免费和Plus用户可以使用该功能,未来,OpenAI将进行更大的测试范围。
,时长00:19
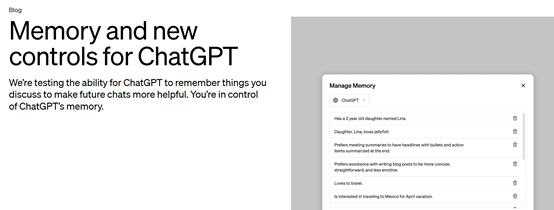
ChatGPT记忆功能介绍
早在2023年4月初,「AIGC开放社区」曾介绍过一篇斯坦福大学写过的《Generative Agents: Interactive Simulacra of Human Behavior》的论文。
当时这篇论文在国内外都非常火,主要通过沙盒开放世界小游戏,为25个由ChatGPT(GPT-3.5-turbo版本)构建的AI代理,添加记忆、规划、沟通和反思的能力,让其像人类一样自然活动、社交、成长。
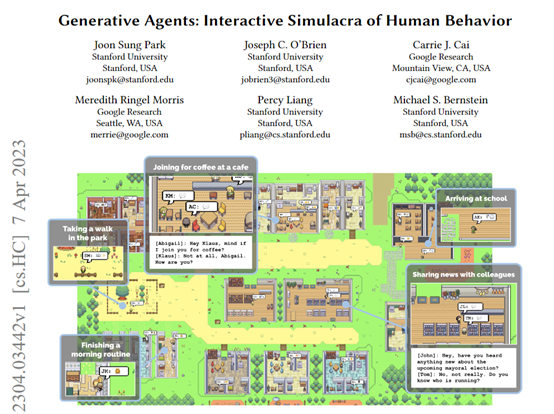
经过2天的模拟游戏测试,研究人员发现了惊人的结果:1)AI自己建立了记忆体系并定期进行深层次反思,从而获得对新鲜事物的见解;
2)AI之间建立了友谊并记住了彼此;3)AI之间学会了相互协调;4)AI之间学会了共享信息;
5)AI具备了定制和修改计划的能力。随后,AI代理功能也火爆出圈,成为一个新的赛道。
今天,ChatGPT新增的功能,就是斯坦福论文中所说的记忆存储。虽然整整晚了将近1年,但该功能对ChatGPT未来的技术迭代至关重要,奠定了更细分的数据基础。
ChatGPT只有先记住数据,才能衍生出更多的功能和玩法,从这一刻开始才是真正有“生命”的AI助手,就像钢铁侠的贾维斯。
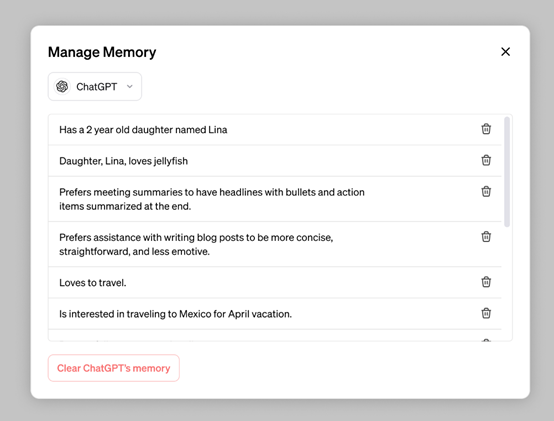
当你启用记忆存储后,与ChatGPT聊天越多记住的就越多,随着时间功能也就越来越强大,以下是典型案例展示。
1)你正在编写一本小说,并且在写作过程中不断向ChatGPT咨询有关书籍结构、角色开发和情节构思的意见。
随着时间的推移,ChatGPT能够记住你的书籍主题、已经创建的角色、甚至是之前讨论过的情节点,可在未来的交流中为你提供更精准、有针对性的建议和反馈。
2)你正在学习一门新语言,ChatGPT可以根据你之前的学习进度、面临的挑战和偏好的学习资源来提供定制化的学习计划。
这意味着ChatGPT能够记住你在语言学习中的强项和弱点,并据此调整提供的练习和材料,帮助你更有效地学习。
3)当你使用ChatGPT编程时,通过分析过往的代码和编程风格,ChatGPT可以提供个性化的编程实践建议。
例如,你倾向于编写冗长的函数,ChatGPT可以根据这个习惯反馈高质量的代码。
如何控制ChatGPT记忆功能
新的记忆功能很强,但带来了更多的数据安全隐患。所以,OpenAI可以让用户自由掌控该功能,开、关完全由你做主。
1)关闭记忆内存:用户可以通过设置>个性化>内存,随时关闭该功能。
2)删除内存记忆:如果你希望ChatGPT删除某些记忆内容,通过设置>个性化>管理内存,来删除特定的内容。
需要注意的是,删除聊天记录没用,需要删除记忆存储才能彻底删除内容。
,时长00:35
3)临时无记忆对话聊天:如果你不想使用记忆存储功能与ChatGPT进行对话,可使用临时聊天功能。
临时聊天不会出现在历史记录中,不会使用内存,也不会用于训练OpenAI的模型。
,时长00:21
OpenAI表示,新推出的自定义GPTs也支持记忆存储功能。但用户不会与开发者共享存储内容,并且想与其他GPT进行交互,需要打开内存才能使用。


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











