






哪句不理解可参考原文再自己翻译或参考该博客
摘要:
人们普遍认为,深度神经网络的成功训练需要成千上万张训练样本。在这篇文章中,我们提出了一种网络和训练策略,这依赖于强烈的使用对于数据增强,以至于更有效的使用可用的训练样本。这个体系结构由一个收缩路径以捕获上下文和一个对称扩展路径实现精确定位组成。我们表明,这样一个网络能够从非常少的图像中训练到end-to-end,并且优于先前最好的方法(这个方法就不翻译了)。使用相同的网络被训练在透射光学显微图像(相位对比和DIC),我们赢得了一个…冠军。此外,网络速度很快。在最近的GPU上分割512x512的图像需要不到一秒钟。完整的信息参考原文或下方博客…
1、介绍
在过去两年中,深度卷积网络在许多视觉识别任务中的表现超出了目前的水平,例如[7,3]。虽然卷积网络已经存在很长时间了,但是由于可用训练集的大小和网络结构的大小,它们的成功受到限制。 Krizhevsky等人创造了很大的突破,他们对具有8层的大型网络和具有100万个训练图像的ImageNet数据集上的数百万个参数进行了监督训练。从那时起,甚至更大更深的网络也得到了训练
卷积网络的典型用途是用于分类任务,其中图像的输出是单个类别。然而,在许多视觉任务中,特别是在生物医学图像处理中,期望的输出应包括位置,所以应该给每个像素都进行标注。然而在生物医学任务中通常无法获得数千个训练图像。因此,Ciresan等人提出用滑动窗口训练网络,通过提供像素周围的局部区域(patch——每个patch包含很多pixel)作为输入,预测每个像素的类标签。首先,这个网络可以完成定位工作。第二,patch的训练数据远大于训练图像的数量。最终网络赢得了ISBI 2012的胜利。
显然,Ciresan等人的策略有两个缺点。首先要分别预测每一个patch的类别,patch之间的重叠会导致大量的冗余。其次这个网络需要在局部准确性和获取整体上下文信息之间平衡,更大的patches需多的最大池化层,但是会降低准确率,小的patches仅允许网络查看很少的上下文信息。最近有方法提出了一种分类器输出,该输出考虑了来自多层的特征,既有准确地定位,又包含了上下文信息。
在这篇文章中,我们建造了一个更加优雅的结构,所谓的全卷积网络[9],我们修改和扩展了这个结构,使其能够在很少的训练图像中工作并且产生更精确的分割,看图一。[9]中主要的idea是通过连续的层去补充通常的收缩网络。其中pooling操作被upsampling操作代替。因此,这些层增加了输出的分辨率。为了localize(定位),来自contracting path(压缩路径)的high resolution features(高分辨率特征)与upsampled输出相结合。一个连续的卷积层然后能学习到一个更精准的输出根据这些信息。

在我们的架构中一个重要的修改是,在upsampling部分我们也有大量的特征通道,这允许网络去传送上下文信息到更高的结果层。因此,the expansive path(扩展路径)或多或少是对称的与contracting path(收缩路径),并产生u型结构。这个网络没有任何完全连通的层并且只使用每个convolution(卷积)的有效部分,即分割图只包含像素,完整的上下文可利用在输入图像中。这个策略允许通过(overlap-tile strategy)重叠的策略无缝分割任意大的图像(见图2)。为了预测图像边缘区域的像素,通过镜像输入图像来推断缺失的上下文。这个 tiling strategy是重要的对于应用这个网络到更大的图像中,否则这个resolution将受到GPU内存的限制。

对于我们的任务,可用的训练数据非常少,we use excessive data augmentation by applying elastic deformations to the available training images.(我们通过对可用的训练图像施加弹性变形来使用过度的数据增强。)。这使得网络去学习这些变形的不变性(invariance to such deformations),而不需要在带注释的图像语料库中查看这些转换。这是非常重要的在生物医学分割中,因为形变曾经是组织中最常见的变异,可以有效地模拟真实的变形。Dosovitskiy et al. [2] 在无监督特征学习的范围内表明了数据增强对学习不变性的价值。
另一个挑战在许多细胞分割任务中是分离同一类的touching objects 看图3。为此,我们建议使用 weighted loss,(加权损耗)。这种情况下,分离背景标签在touching cells之间包含一个很大的权重在损失函数中。
所得结果网络适用于各种生物医学分割问题。在这篇论文中,我们展示了在EM stacks(EM堆栈)(ISBI 2012开始了一项正在进行的比赛)中神经元结构的分割结果。所得结果超过了Ciresan et al. [1].该文的网络。此外,我们还展示了来自ISBI细胞跟踪挑战赛2015的光镜图像中的细胞分割结果。在这两个最具挑战性的2D透射光数据集上,我们以很大的优势获胜。
2、网络结构
网络体系结构如图1所示。它由contracting path (left side) and an expansive path(收缩路径(左侧)和扩展路径(右侧)组成)。收缩路径遵循卷积网络的典型结构。它包括重复应用两个3x3的卷积(无填充卷积),每个卷积后面有一个整流线性单元(ReLU)和一个2x2的最大池操作(步幅为2),用于downsampling(下行采样)。在每个下采样步骤中,我们将特征通道的数量增加一倍。expansive path的每一步都包括特征图的上采样,然后是将特征通道数量减半的2x2卷积(“上卷积”),与来自收缩路径的相应裁剪特征图的连接,以及两个3x3卷积,每个卷积后面跟着一个relu。在最后一层使用1x1卷积来映射每个64组件特征向量到所需的类数。该网络总共23个卷积层。
为了允许输出分割图的无缝平铺(见图2)。选择输入平铺大小是很重要的,这样所有2x2max-pooling操作都应用到具有偶数x和y大小的层上。
3、训练
使用caffe【6】的随机梯度下降算法对输入图像和他们相应的分割图进行训练。由于未填充卷积,输出图像比输入图像小一个恒定的边框宽度。为了最小化开销并最大限度的利用GPU内存,我们赞成大的输入贴图而不是大的批处理大小,从而将批处理减少到单个图像。因此,我们使用一个高动量(0.99),这样大量之前看到的训练样本决定了当前优化步骤中的更新。
energy函数被计算是通过最终特征图上的逐像素 soft-max结合交叉熵损失函数。soft-max被定义为pk(x),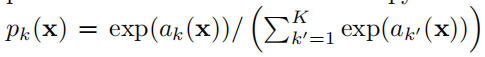 ak(x)表示在像素位置x∈Ω的特征通道k中激活。Ω⊂Z2。k为类别的数量,pk(x)是近似的最大值函数。对于具有最大激活 ak(x) 的 k,pk(x) ≈ 1,对于所有其他 k,pk(x) ≈ 0。
ak(x)表示在像素位置x∈Ω的特征通道k中激活。Ω⊂Z2。k为类别的数量,pk(x)是近似的最大值函数。对于具有最大激活 ak(x) 的 k,pk(x) ≈ 1,对于所有其他 k,pk(x) ≈ 0。
The cross entropy then penalizes at each position the deviation of pl(x)(x) from 1 using 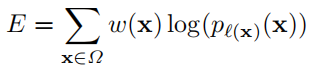
公式这部分实在不想翻译,参考博客或看原文吧。
3.1、数据扩充
当只有很少的训练样本可用时,要想尽可能的让网络获得不变性和鲁棒性,数据增加是很重要的。在显微图像的情况下,我们主要需要平移和旋转不变性以及对变形和灰度值变化的鲁棒性。将训练样本进行随机弹性变形似乎是训练具有很少注释图像的分割网络的关键概念。我们使用随机位移矢量在粗糙的3x3的网格上产生平滑的形变。位移是从具有 10 个像素标准偏差的高斯分布中采样的。然后使用双三次插值计算每个像素位移。 收缩路径末端使用 Drop-out 层执行进一步的隐式数据增强。(implicit data augmentation).

后面可参考
或者其他地方也可参考该博客。
本文介绍部分的翻译也参考该博客,且该博客内容较完整,有兴趣的同学可参考。















 2561
2561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









