







1.前言
关于Re0谁是女主角一直是个争论不休的话题,作为一个坚定的艾米莉亚党,为了支持自己买的股票,我决定交给Re0原著小说(1-19章)来判断。根据原著中谁的出场频率最高,来看看谁才是真正的女主角。
2.最简单的词云
首先让我们有请我们的工具人1号——WordCloud库。它可以统计文本中各个词语的频率,并且将它们通过不同大小的词云来展示。话不多说,上代码。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
txt = open('Re0.txt', encoding='ANSI').read()
#读入Re0小说,注意小说的格式,存储在字符串txt中
wc = WordCloud(font_path='Hiragino.ttf',width=800,
height=600,mode='RGBA',background_color=None).generate(txt)
#WordCloud新建的是一个wordcloud对象,里面的参数可以自行控制,
#width和heigth分别是宽度和高度
#font_path代指字体路径,中文字体不设置路径就会出现乱码
#而mode代表读入的模式,这里采用RBGA格式,表示在RGB的基础上加了一
#个alpha,也就是透明度backgroud_color为背景颜色,默认是黑色,
#这里设置为None和RGBA模式配合可以得到无背景的透明词云
plt.imshow(wc)
plt.axis('off')
#去除坐标轴
plt.show()
wc.to_file('Re0_untokenized.png')
#输出图片,注意在RGBA模式下只能输出为png格式的图片

|
3. 分词后的词云
这里我们看到一堆没有用的词,‘因为’,‘所以’,‘不过’……。使用频率最高的是‘不过’,‘可是’,‘但是’这些转折词。而且出现了’开什么玩笑’,‘怎么了’,‘不仅如此’,‘即使如此’这些分词没有分开的情况。那么这个时候有请我们的二号工具人——jieba分词和stopwords停顿词。jieba是目前特别流行的中文分词工具,可以恰到好处地对中文句子进行分词。而从stopwords中可以得到目前中文中出现频率极高但是却对分析文本没有意义的词。例如:‘因为’,‘所以’,‘不过’这些关联词等等。这里博主下载的是百度的停顿词库。链接见文末参考资料。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
txt = open('Re0.txt', encoding='ANSI').read()
txt = ' '.join(jieba.cut(txt))
#用jieba进行分词,再将分词用空格连接起来。这里分词会消耗很长的时间
stop_words = open('stopwords/baidu_stopwords.txt',
encoding='utf8').read().split()
#打开停顿词库,将其用空白符分割成列表
wc = WordCloud(font_path='Hiragino.ttf',width=800, height=600,
stopwords=stop_words,mode='RGBA',
background_color=None).generate(txt)
#把停顿词列表输入wordcloud对象中,这样wordcloud计数时便会忽略这些词
plt.imshow(wc)
plt.axis('off')
plt.show()
wc.to_file('Re0_tokenized_stopwords.png')

|
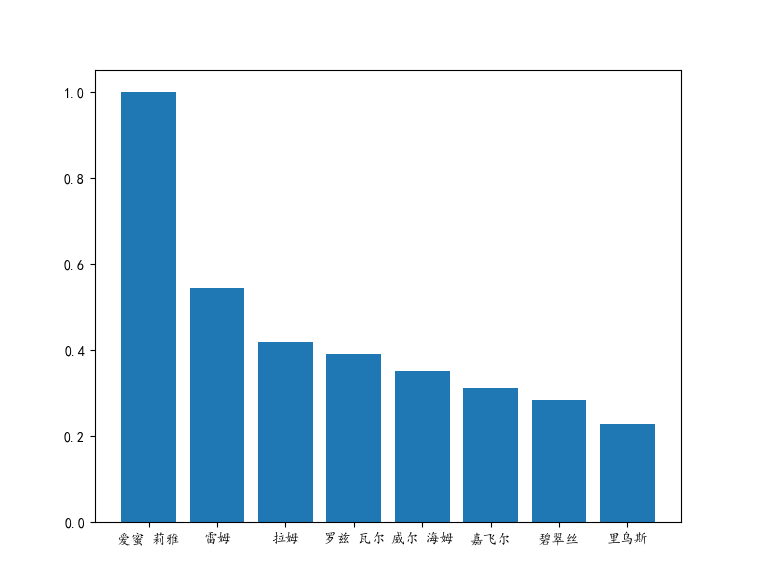
看到艾米莉亚这几个大字没有,这是EMT党的大胜利!!!但是我有觉得好像和雷姆差不多。那么让我们用数来说话吧。下面我们选取几个比较大的名字将他们在词云统计中的频率画出来。
#接续上一节代码
print(wc.words_)
# wc.words_是词云对象的一个成员,它是由词语:频率组成的字典,
# 我们将它打印观察一下
plt.rcParams['font.sans-serif']=['KaiTi'] #用来正常显示中文标签
plt.rcParams['font.serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#这一段是用来处理中文乱码的代码,原本是打算按照网上改成SimHei字体,
#发现还是乱码结果改成KaiTi才解决了这个问题。
new_keys = [u'爱蜜 莉雅', u'雷姆', u'拉姆', u'罗兹 瓦尔',
u'威尔 海姆', u'嘉飞尔', u'碧翠丝', u'里乌斯']
#这里每个中文词前面加u表示采用unicode编码
dic1 = {key : wc.words_[key] for key in new_keys}
# 这里我们根据选择的keys形成新的词典
plt.bar(*zip(*dic1.items()))
#用dic1.items()获得字典里面的全部内容,得到用二元组组成的列表
#zip(*)将其解压,得到一堆二元组。bar(*)将二元组一个个画出来
plt.show()
|
#打印的结果
{'爱蜜 莉雅': 1.0, '雷姆': 0.5444051387078757, '拉姆':
0.41817166263265687, '罗兹 瓦尔': 0.39136101284676966, '威尔 海姆':
0.3528207037795569, '嘉飞尔': 0.31297709923664124, '碧翠丝':
0.28542170917892384, '声音': 0.2619623906162726, '少女':
0.26084528020852726, '魔女': 0.25991435486873954, '就算':
0.25544591323775834, '身体': 0.23589648110221562, '世界':
0.23422081549059764, '真的': 0.2329175200148948, '感觉':
0.23273133494693726, '一个': 0.22938000372370135, '里乌斯':
0.2280767082479985,
我们可以看到艾米莉亚词频最高,EMT的大胜利。而雷姆从第二卷登场,第十卷沉睡,只在一半的章节登场,相对出场频率却占了艾米莉亚的一半还多,tql。而从词频上看,486根本没有上榜,可能是分词后‘菜月昴’无了,所以我们的男主是’罗兹瓦尔’,不接受反驳,谢谢。牛头人党的大胜利。另外,让人感到意外的是,Re0里面妹子这么多,没想到威尔海姆老爷子,加菲猫,尤里乌斯这几个大老爷们也上榜了。真就是无论男的女的我全都要呗。
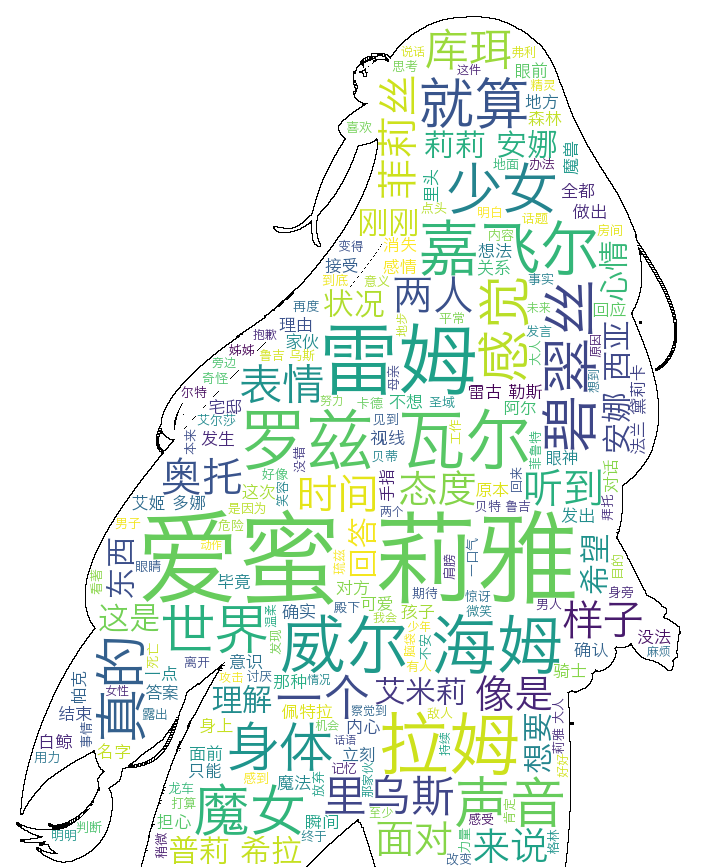
4.将词云变成艾米莉亚的形状
这样就完事也太无聊了,为了庆祝EMT党的大胜利,不如我们把词云改成艾米莉亚的形状。这里就要介绍我们的第3个工具人了——cv2库。它能够按照多维数组格式读入图片。wordcloud对象有一个mask参数,读入多维数组。然后wordcloud会将白色的像素视为背景删去,在剩余的像素点上绘图。因此要求我们选作蒙版的图片要么是白色背景的jpg,要么是无背景的PNG,并且尽量大一点且前景集中在一块,否则会出现字看不清和字分布得很离散的情况。
这里由于艾米莉亚穿的是白色的衣服,所以经常被剔除,得到残破不全的词云。无奈之下博主只能用PS P了一张黑白的。这是原图和P图
 图3.a 原图 图3.a 原图
|
 图3.b PS处理后的图 图3.b PS处理后的图
|
import matplotlib.pyplot as plt
import jieba
import cv2
from wordcloud import WordCloud
txt = open('Re0.txt', encoding='ANSI').read()
txt = ' '.join(jieba.cut(txt))
stop_words = open('stopwords/baidu_stopwords.txt',
encoding='utf8').read().split()
img = cv2.imread('aimi4.png', cv2.IMREAD_GRAYSCALE)
#用cv2库读入图图像,并且采用灰度方式读入。
#这里推荐使用600x800以上的图片,而且背景和角色最好分开,角色最好比较大,
#图片背景必须是透明或者全白,不能有其它杂色
wc = WordCloud(mask=img, font_path='Hiragino.ttf',
stopwords=stop_words,contour_width=1,contour_color='black',
background_color='white').generate(txt)
#设置Img为mask蒙版,控制词云形状
#为了将图片的轮廓画出来,所以指定contour_width就是轮廓宽度,默认等于
#0,就#是不画轮廓,contour_color指的是轮廓颜色。
#注意这里不能用RGBA模式否则报错
#operands could not be broadcast together
#with shapes (868,726,4) (868,726,3)猜测是因为RGBA是4维度的
#而画轮廓用的却是三维颜色
plt.imshow(wc)
plt.axis('off')
plt.show()
wc.to_file('Re0_black_shape.png')
|
5.给词云染上艾米莉亚的颜色
这还不够,博主希望控制云图的文本安装艾米莉亚的颜色来上色。也就是说根据原图中艾米莉亚的颜色分布控制云图文本颜色分布。这里我们可以借用WordCloud中的ImageColorGenerator函数得到原图的颜色分布,在利用wordcloud对象的recolor函数给云图重新上色。
# -*- coding: utf-8 -*-
from wordcloud import WordCloud, ImageColorGenerator
import cv2
import matplotlib.pyplot as plt
import jieba
txt = open('Re0.txt', encoding='ANSI').read()
txt = ' '.join(jieba.cut(txt))
stop_words = open('stopwords/baidu_stopwords.txt',
encoding='utf8').read().split()
mask = cv2.imread('aimi4.png', cv2.IMREAD_UNCHANGED)
#这里假如后面的词云要采用RGBA模式的话,读入png格式需要指定读入格式为
#cv2.IMREAD_UNCHANGED,否则alpha元素信息丢失,后面会报错。
wc = WordCloud(mask=mask, font_path='Hiragino.ttf',
stopwords=stop_words,
contour_width=1,contour_color='black',
background_color='gray').generate(txt)
#这里为了便于观看将背景色设为灰色
color = cv2.imread('aimi3.png', cv2.IMREAD_UNCHANGED)
img_color = ImageColorGenerator(color)
#从图片中获得原图的颜色分布
wc.recolor(color_func=img_color)
#根据图片颜色分布给词云上色
plt.imshow(wc)
plt.axis('off')
plt.show()
wc.to_file('Re0_color_mask.png')
|
图5.a 原图
|
 图5.b 染上艾米莉亚颜色的词云 图5.b 染上艾米莉亚颜色的词云
|
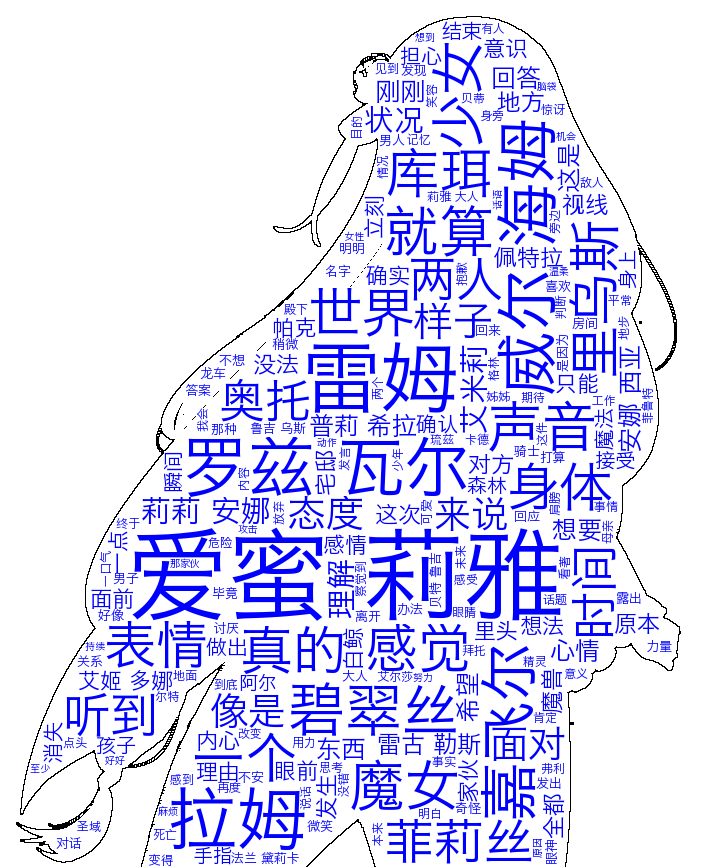
6.用雷姆蓝给词云上色
但是博主作为一个博爱的人,对于雷姆也特别喜欢,所以我希望将词云染上雷姆色。并且希望将词云用雷姆色表示。(希望各位EMT党放下你们手里的刀)。这里就要说到wordcloud对象的又一个参数了——color_func。它读入一个返回颜色的函数名,形参为word, font_size, position, orientation, font_path, random_state。例如random_color(word, font_size, position, orientation, font_path, random_state)。这里为了控制词云的颜色。根据官网的说法,可以这么写color_func=lambda *args, **kwargs: (255,0,0)便可以将字体颜色设置为红色。
# -*- coding: utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import cv2
import jieba
# 打开文本
text = open('Re0.txt', encoding='ANSI').read()
# 中文分词
text = ' '.join(jieba.cut(text))
#print(text[:100])
# 生成对象
mask = cv2.imread('aimi4.png', cv2.IMREAD_UNCHANGED)
stop_words = open('stopwords/baidu_stopwords.txt',
encoding='utf8').read().split()
wc = WordCloud(color_func=lambda *args, **kwargs: (0,0,255),
mask=mask, font_path='Hiragino.ttf',stopwords=stop_words,
contour_width=1,contour_color='black',
background_color='white').generate(text)
#这里设置词云的颜色为蓝色
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
# 保存到文件
wc.to_file('RE0_color_blue.png')
|
7.用频率说话
这里词云可以通过wordcloud对象的generate(文本字符串)生成,实际上,也可以用wordcloud对象的generate_from_frequencies(频率字典)函数形成。也就是说,该函数可以读入一个形如{词:词频}的字典,然后输出云图。我们看看利用这个函数会不会有什么区别。
# -*- coding: utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import cv2
import jieba.analyse
# In[1]:
# 打开文本
text = open('Re0.txt', encoding='ANSI').read()
# 提取关键词和权重
#freq = jieba.analyse.extract_tags(text, topK=200,
# withWeight=True, allowPOS=('ns','n'))
#这里allowPos是指允许提取的词性,这里选取的是ns--地名,n--名词,
#但是耗时长达2min,并且人名无法分析出来,很奇怪,于是果断放弃
freq = jieba.analyse.extract_tags(text, topK=200, withWeight=True)
print(freq[:20])
#这里由于jieba分析后得到的结果返回的是二元组构成的列表,
#因此需要将其修改为字典
freq = {i[0]: i[1] for i in freq}
mask = cv2.imread('aimi4.png')
stop_words = open('stopwords/baidu_stopwords.txt',
encoding='utf8').read().split()
wc = WordCloud(color_func=lambda *args, **kwargs: (0,0,255),
mask=mask, font_path='Hiragino.ttf', stopwords=stop_words,
contour_width=1,contour_color='black',
background_color='white').generate_from_frequencies(freq)
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
wc.to_file('RE0_Freq.png')
|
图7.a 文本生成的词云
|
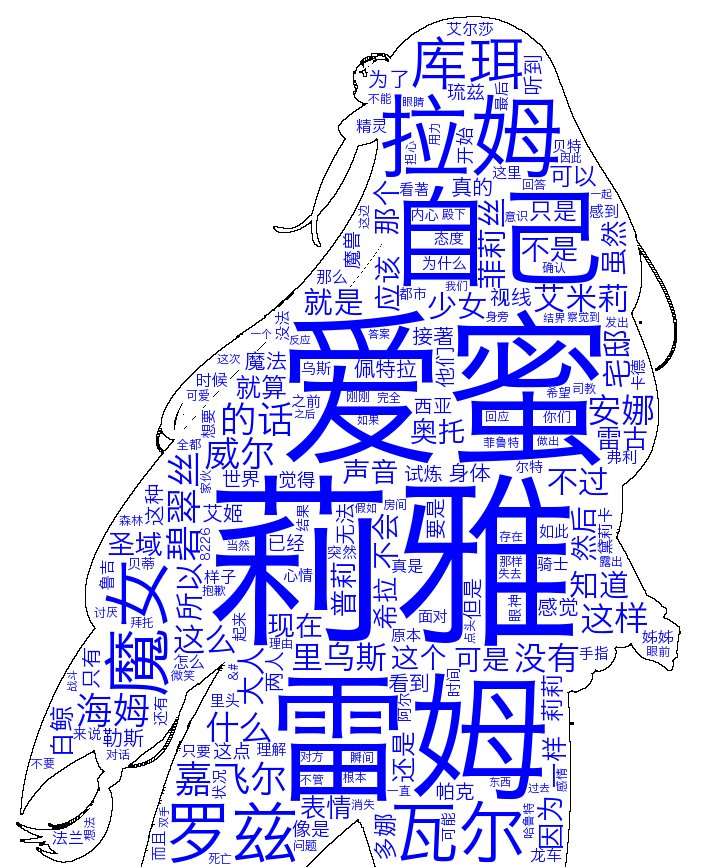 图7.b 频率生成的词云 图7.b 频率生成的词云
|
我们可以看到还是有些区别的,艾米莉亚被分成了两个词艾米和莉亚。罗兹瓦尔也是类似。而且还有不少的停顿词如‘只是’,‘只有’,‘什么’等等。看样子还是老老实实用generate吧。
图片均来自于百度,如若侵权请通知博主删除。刚刚入门wordcloud。如果有错误希望各位大佬不吝指教。代码,图片,字体文件在这里
PS
anaconda安装opencv经常出现问题
这里我用的如下语句,就安装完毕了
conda install -c menpo opencv















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









