







1、前言
viterbi算法是HMM模型的三大算法之一。HMM模型解决三大问题:评估、解码和学习。viterbi用于解决解码问题,在自然语言处理中用于解决划分问题,分词是对于句子的划分,viterbi是很好的分词算法。推荐参看的是《HMM学习最佳范例》。这里的术语将参照《HMM最佳学习范例》。关于HMM模型中的数值引用于结巴分词中的源代码。
2、初始向量
这里start_p是初始向量,下文用π表示:
P={
'B': -0.26268660809250016,
'E': -3.14e+100,
'M': -3.14e+100,
'S': -1.4652633398537678}从向量中可以看出,多字词的概率要大于单字词,其中-3.14e+100表示一个极小的概率。
3、状态转移矩阵
trans_P表示状态转移矩阵,下文用A表示:
P={
'B': {
'E': -0.510825623765990, 'M': -0.916290731874155},
'E': {
'B': -0.5897149736854513, 'S': -0.8085250474669937},
'M': {
'E': -0.33344856811948514, 'M': -1.2603623820268226},
'S': {
'B': -0.7211965654669841, 'S': -0.6658631448798212}}A中的元素值为一个隐藏状态转移到另一个隐藏状态的概率,代码中数据结构用嵌套的字典,并只包含了非零元素。例如:B状态只能转移到E或者M状态,分词表示双字词和多字词。
4、混合矩阵
emit_P表示混合矩阵,下文用C表示(为了防止和隐藏状态B混淆,使用C):
P={
'B': {
'\u4e00': -3.6544978750449433,
'\u4e01': -8.125041941842026,
'\u4e03': -7.817392401429855,
'\u4e07': -6.3096425804013165,
'\u4e08': -8.866689067453933,
'\u4e09': -5.932085850549891,
'\u4e0a': -5.739552583325728,
....}C矩阵中行为隐藏状态,列为观察状态,每一行所有元素的和为1。矩阵的值表示P(观察状态|隐藏状态)。
申明:矩阵A和C都是和时间无关的,不随时间而改变。我们把(π,A,C)叫作一个HMM模型。
5、局部最佳路径和局部概率
在分词中我们把待分词的句子看为时序列,即我们把第一个字看为t=1。对于任意的中间状态或者终止状态都有许多能够到达该状态的路径,我们把这些路径中概率最大的称为局部最佳路径。局部最佳路径的概率称为该状态的局部概率。
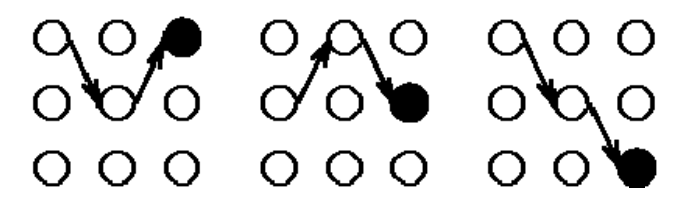
图片来源于《HMM最佳学习范例》,其中的路径即为到达黑点的最佳路径。那么在终止状态时即句子的末尾,我们有所有隐藏状态的局部最佳路径和局部概率,那么就可以选择出全局的最佳路径(最佳隐含状态序列),即得到句子的划分。
在t=1时,因为没有指向隐藏状态j的路径,局部概率为初始概率乘以相应的观察概率。以“英语单词”为例
在t=2时,利用数学归纳法的思想,我们已经知道t=1时,所有隐藏状态j的局部概率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2710
2710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









