







 本文介绍了如何将卷积神经网络(CNN)应用于自然语言处理(NLP),通过矩阵表示输入文本,CNN的过滤器在词向量上滑动,不同于图像处理中的过滤器。讨论了CNN的超参数,包括窄卷积与宽卷积、步幅大小、汇聚层和通道,并指出其在文本分类任务中的优势。同时,指出了CNN在NLP中的局限性和可能的改进方向。
本文介绍了如何将卷积神经网络(CNN)应用于自然语言处理(NLP),通过矩阵表示输入文本,CNN的过滤器在词向量上滑动,不同于图像处理中的过滤器。讨论了CNN的超参数,包括窄卷积与宽卷积、步幅大小、汇聚层和通道,并指出其在文本分类任务中的优势。同时,指出了CNN在NLP中的局限性和可能的改进方向。
博客地址:http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
首先申明本人的英语很搓,看英文非常吃力,只能用这种笨办法来方便下次阅读。有理解错误的地方,请别喷我。
CNN怎么应用到NLP
什么是卷积和什么是卷积神经网络就不讲了,自行google。从在自然语言处理的应用开始(SO, HOW DOES ANY OF THIS APPLY TO NLP?)。
和图像像素不同的是,在自然语言处理中用矩阵来代表一句话或者一段话作为输入,矩阵的每一行代表一个token,可以是词,也可以是字符。这样每一行是一个向量,这个向量可以是词向量像word2vec或者GloVe。也可以是one-hot向量。如果一句话有10个词,每个词是100维的词向量,那么得到10*100的矩阵,这就相当于图像识别中的图像(input)。
在图像中,过滤器是在图像的部分滑动,而在NLP中过滤器在整行上滑动。意思是过滤器的宽度和输入矩阵的宽度是一致地。(就是说过滤器的宽度等于词向量的维度。)在高度上常常是开2-5个词的滑动窗口。总结起来,一个在NLP上的CNN长这样:
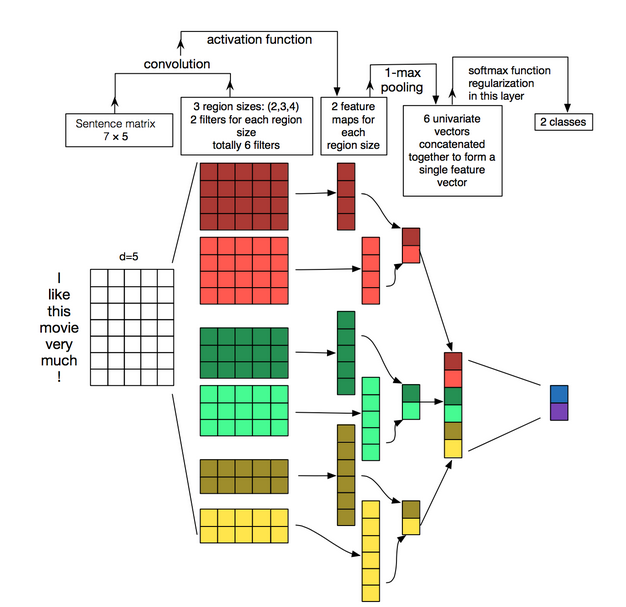
这里有3种过滤器,滑动窗口为2、3、4,每种有2个。后面阐述了CNN在NLP上的不足(没看明白)。表示RNN更符合语言的理解习惯。后面又说模型跟实现的理解有偏差,但是CNN在NLP上的表现是不错的。同时也吐槽了词袋模型也一样。(原因鬼知道)
CNN的另一个优势是快,这里用N-Gram模型做对比。我们都知道在VSM模型中采用3-gram的维度就很恐怖了,文中说google也处理不了超过5-gram的模型。这是CNN模型的优势,同时在CNN的输入层采用n-size的滑动窗口和n-gram处理是相似的。(不能同意再多,个人认为部分功劳在word embeddings上。当然不全是,因为即使采用one-hot,维度也不会随着窗口的size变化。而在n-gram中是随着n的变化爆发性增
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5584
5584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









