






上一章:分割(Segmentation)
下一章:嵌入(Embeddings)
更多章节:人工智能入门课程
目录
课前练习
文本分类
在这一节课的第一部分,我们将聚焦于文本分类任务。我们将使用包含新闻文章的AG News数据集,它的解构如下:
- 目录(Category): 科学/技术(Sci/Tech)
- 标题(Title): 肯塔基州公司获得研究肽的资助(AP)
- 正文(Body): AP - 由路易斯维尔大学的化学研究员创办的一家公司获得了一笔资助来开发..
我们的目标是将新闻根据文本内容分类成不同的类别。
文本表示
如果我们想使用神经网络处理资源语言处理任务,我们需要采用某种方法将文本表示为张量。计算机已经将文本字符表示为数字,这些数字使用诸如ASCII或者UTF-8的编码映射到您屏幕上成为字体。
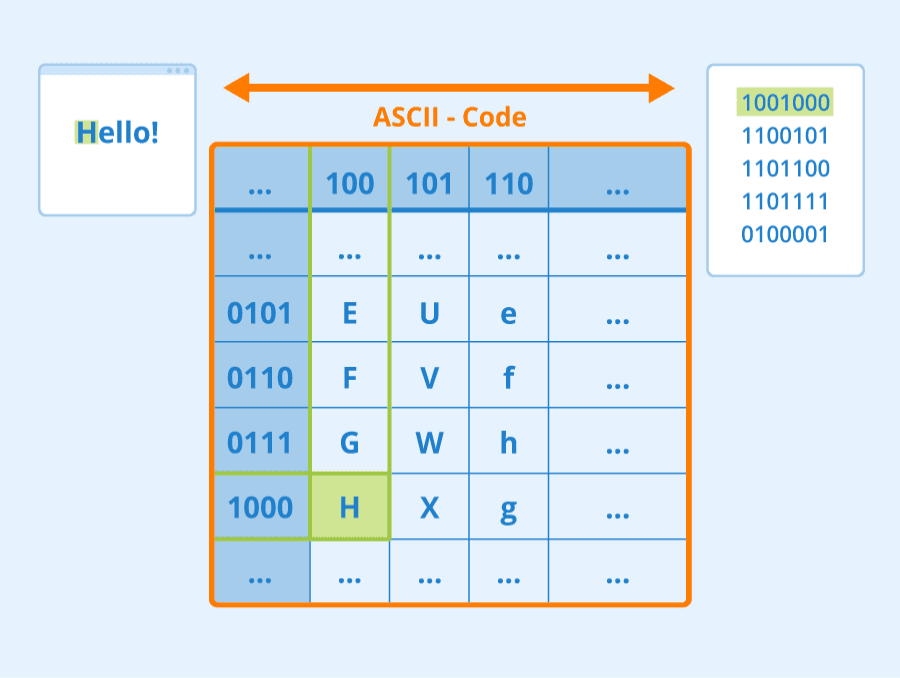
作为人类,我们理解每个字符的含义,以及字符如何组合成句子中的单词。然而,计算机本身并没有这种理解能力,因此神经网络需要通过训练学习文本的含义。
因此,我们在表示文本时,可以使用不同的方法:
- 字符级的表示(Character-level representation), 当我们表示文本时,把每个字符当作一个数字。假设在我们的文本集中有C个不同的字符,则单词“Hello”可以使用一个5*C的张量来表示。每个字母对应于一个使用one-hot编码的张量列。
- 单词级的表示(Word-level representation),我们创建文本中所有单词的词表,然后使用one-hot 编码表示单词。这种方法在某种程度上更好,因为每个字母本身并不存在太多的意义。因此,通过使用高级语义概念-单词-我们简化了神经网络的学习任务。但是,由于字典规模的庞大,我们需要处理高维稀疏张量。
不管采用哪种表示方式,我们首先需要把文本转化为token序列,每个token可以是一个字符,一个单词,或者有时甚至是一个单词的一部分。然后,我们通常使用词表将toke转化为数字,这个数字可以使用one-hot编码后输入到神经网络。
几点补充:
词表: 词表是包含所有单词及其对应索引的列表。
one-hot 编码: one-hot 编码是一种稀疏编码方式,对于一个包含 N 个元素的集合,使用长度为 N 的向量进行表示,只有对应元素的索引位置为 1,其余位置均为 0。
N元语法(N-Grams)
在自然语言中,单词的具体含义只有在语境上下文中才能确定。比如,神经网络(neural network)与渔网(fishing network)(中“网”)的含义完全不同。考虑上下文的一种方法是,将我们的模型构建在词对之上,同时将词对视作独立的词表项(vocabulary token)。在这种方法中,句子“我喜欢钓鱼(i like to go fishing)”会表示为如下token序列:I like,like to, to go,go fishing。这种方法的问题显而易见,字典规模会显著增长,同时单词组合比如“go fishing”和“go shoping”被视作不同的token,尽管它们拥有相同的动词,但依旧被视作语义上没有任何相似点。
在某些情况下,我们可能考虑使用三元语法(tri-grams)--三个词的组合。因此,这种方法通常被称作n元语法(n-grams)。此外,在字符级表示中使用n元语法也是有意义的,在这种情况下,n元语法大概率对应不同的音节。
词袋模型(Bag-of-Words)和TF/IDF
当处理像文本分类这种任务时,我们需要能够使用固定大小的向量表示文本,这些向量将作为最终稠密分类器(final dense classifier)的输入。一种最简单的实现方法是组合所有单词的表示,例如,通过将它们相加。如果我们把每个单词的one-hot编码加起来,我们最终将得到一个词频向量,该向量显示文本中每个单词出现的次数。这种文本表示方式被称作词袋模型(bag of words (BoW).)

图像由作者提供
词袋模型本质上反应了文本中出现了哪个单词以及出现次数,这确实可以很好的指示文字主题。例如,与政治相关的新闻文章通常包含诸如“总统”、“国家”等单词,而科学出版物则可能包含“对撞机”、“发现”等单词。因此,词频在很多情况下可以很好的指示文本内容的含义。
BoW的缺点是,诸如“和(and)”、“是(is)”等常用单词必然出现在大多数文本中。并且它们的词频最高,掩盖了真正重要的单词。我们通过考虑计算这些单词出现在整个文档集中出现的频率,来降低它们的重要性。这就是TF/IDF方法背后的核心思想,在本课的附加代码笔记本中将更详细的介绍它。
然而,这些方法都不能够完整的考虑到文本的语义。我们需要更强大的神经网络模型来做到这一点,我们将在本节的后续部分讨论。
✍️ 练习: 文本表示
通过以下笔记继续您关于文本表示的学习:
总结
到目前位置,我们学习了可以对文本中不同单词的词频赋予权重的技术。然而,这些技术不能表示词义和单词顺序。正如最著名的语言学家J. R. Firth 在1935年说的,“单词的完整意思总是依赖于上下文,任何脱离语义研究词义的行为都无关紧要。”我们将在本课程的后续部分学习如何通过语言模型从文本中捕获上下文信息。
挑战
使用词袋模型和其他不同的数据模型做一些其他练习。您也许能通过参加 Kaggle竞赛获取到灵感。
课后练习
复习与自学
在Microsoft Learn上实践文本embeddings和词袋模型技术的技能 on Microsoft Learn
作业: 代码笔记
上一章:分割(Segmentation)
下一章:嵌入(Embeddings)
更多章节:人工智能入门课程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









