






上一章:十三、文本的张量表示
下一章:十五、语言模型
更多章节:人工智能入门课程
课前练习
在基于BoW 或者TF/IDF训练分类器时,我们处理的是长度是词表大小(vocab_size)的高维词袋向量,并且需要明确的将低维位置表示向量转换为稀疏one-hot表示,然而,one-hot表示并不是内存高效的。另外,每个单词都被独立对待,即one-hot编码向量并不表达单词之间的语义相似度。
embedding的思想是使用低维稠密向量表示单词,这些向量在某种程度上反映了单词的语义含义。我们将在稍后讨论如何构建有含义的单词embeddings,但是现在我们先把embeddings视作一种降低单词向量维度的方法。
因此,embedding层将接收单词作为输入,并生成一个特定嵌入大小(embedding_size)的向量输出。在某种意义上,embedding层非常类似于线性层,但不同于线性层接收one-hot编码向量作为输入,embedding层能够接收单词的编号作为输入,从而避免创建大规模的one-hot编码向量。
通过在我们分类网络中使用embedding层作为第一层,我们可以从词袋模型(bag-of-words)转变为嵌入袋(embedding bag)模型,在这一层我们首先把文本中的每个单词转换为相应的embedding,然后对所有这些embeddings执行聚合函数,比如说求和,求平均值,或者最大值。
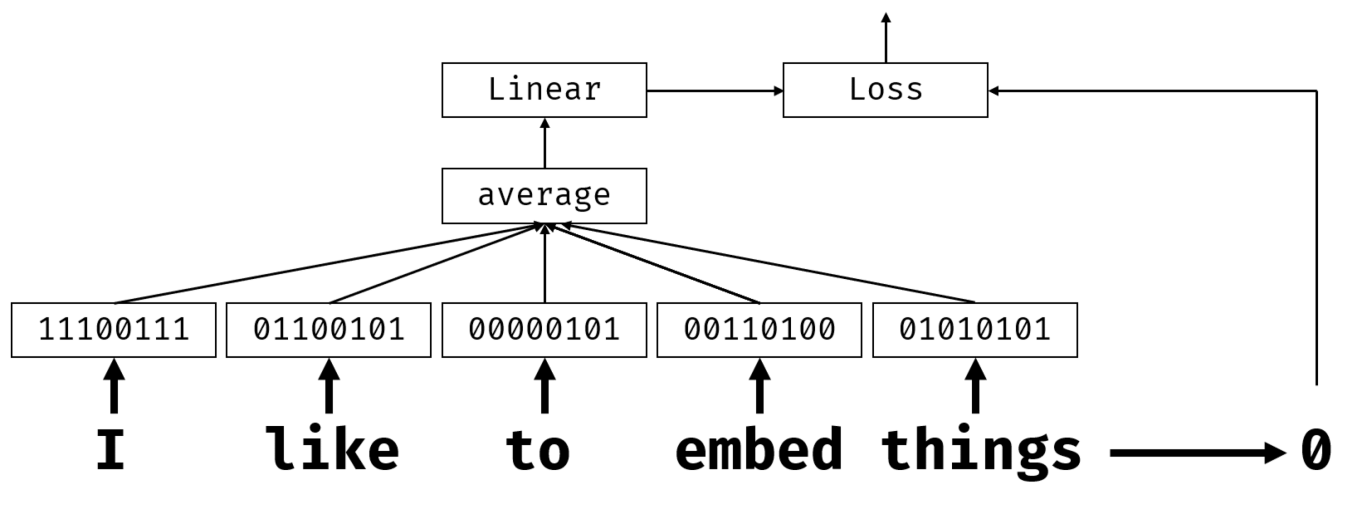
图片由作者提供
✍️ 练习: Embeddings
在以下代码笔记中继续学习:
语义Embeddings(Semantic Embeddings): Word2Vec
虽然embedding层学习将单词映射成向量表示,但是,这个向量表示并不具有多少语义含义。理想的情况下,我们可以学习一种向量表达,使得近义词或者同义词对应的向量在某种向量距离(如欧氏距离)上彼此靠近。
为了做到这一点,我们需要在大量的文本上以特定的方式预训练我们的embedding模型。一种训练语义embeddings的方法称为Word2Vec。它基于两种主要架构,来生成单词的分布式表示:
- 连续词袋(Continuous bag-of-words (CBoW) )—在这种架构中,我们训练模型以周围的上下文来预测一个单词。给定n元语法(ngram)(即n个连续单词)$(W_{-2},W_{-1},W_0,W_1,W_2)$,模型的目标是通过$(W_{-2},W_{-1},W_1,W_2)$上下文来预测单词$W_0$ 。
- 连续跳字(Continuous skip-gram)与CBoW相反。该模型使用周围窗口的上下文单词,来预测当前单词。
CBoW 更快,skip-gram更慢,但skip-gram 在表示不频繁的单词方面效果更好。
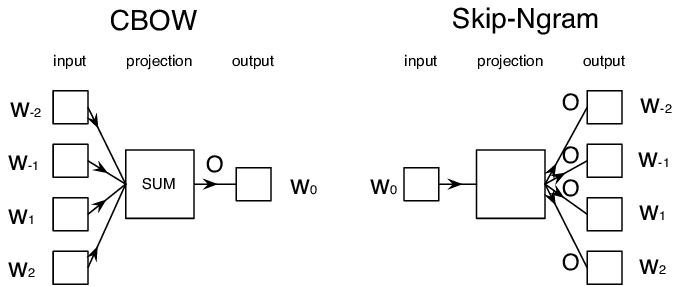
图像出自这篇论文
Word2Vec 预训练embeddings (以及其他类似模型,比如GloVe) 也可以替代神经网络中的embedding层。然而,我们需要处理词汇表,因为用于预训练Word2Vec/GloVE的词汇表,很可能与我们文本语料库中的词汇表不同。 查看上面的代码笔记,看看如何解决这个问题。
语境Embedding(Contextual Embeddings)
像Word2Vec这种传统预训练embedding表示技术的关键限制是词义歧义消除问题。虽然预训练embeddings能够捕获单词在上下文的一些含义,但单词的所有可能含义都被编码进同一个embedding中。这可能会给下游模型带来问题,因为很多单词,比如会说‘玩(play)’使用在不同的上下文中有不同的意思。
例如单词‘玩(play)’在这两个不同的句子中意思很不相同:
- 我去剧院看了场戏剧(play)(I went to a play at the theatre)。
- john想和他的朋友们一起玩(play)(John wants to play with his friends)
上述预训练embeddings把使用相同的embedding表示单词‘play’的含义。为了解决这个限制,我们需要基于语言模型来构建embeddings,该模型使用大型文本语料库进行训练,并且能够理解如何在不同的上下文中组合使用词语。基于上下文的embeddings不在本教程的讨论范围,但我们将在本课程后续讨论语言模型时再次讲到它。
总结
在这节课中,您发现了如何在TensorFlow和Pytorch中构建并使用embedding层,以更好的反应单词的含义。
挑战
Work2Vec已经在某些有趣的应用中使用到了,包括生成歌词和诗歌。关注这篇文章,它介绍了作者如何使用Word2Vec来生成诗歌。观看这个由Dan Shiffmann提供的视频,了解另一种关于Word2Vec的不同的解释。然后在您自己的文本语料库上应用这些技术,也许您可以从Kaggle下载相关语料库。
课后练习
复习与自学
通读这篇关于Word2Vec的论文:在向量空间中高效评估单词表示。
作业: 代码笔记
上一章:十三、文本的张量表示
下一章:十五、语言模型
更多章节:人工智能入门课程















 1895
1895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









