






原文:Knowledge Representation and Expert Systems
上一章:一、人工智能简介
下一章:三、感知器
更多章节:人工智能入门课程
目录
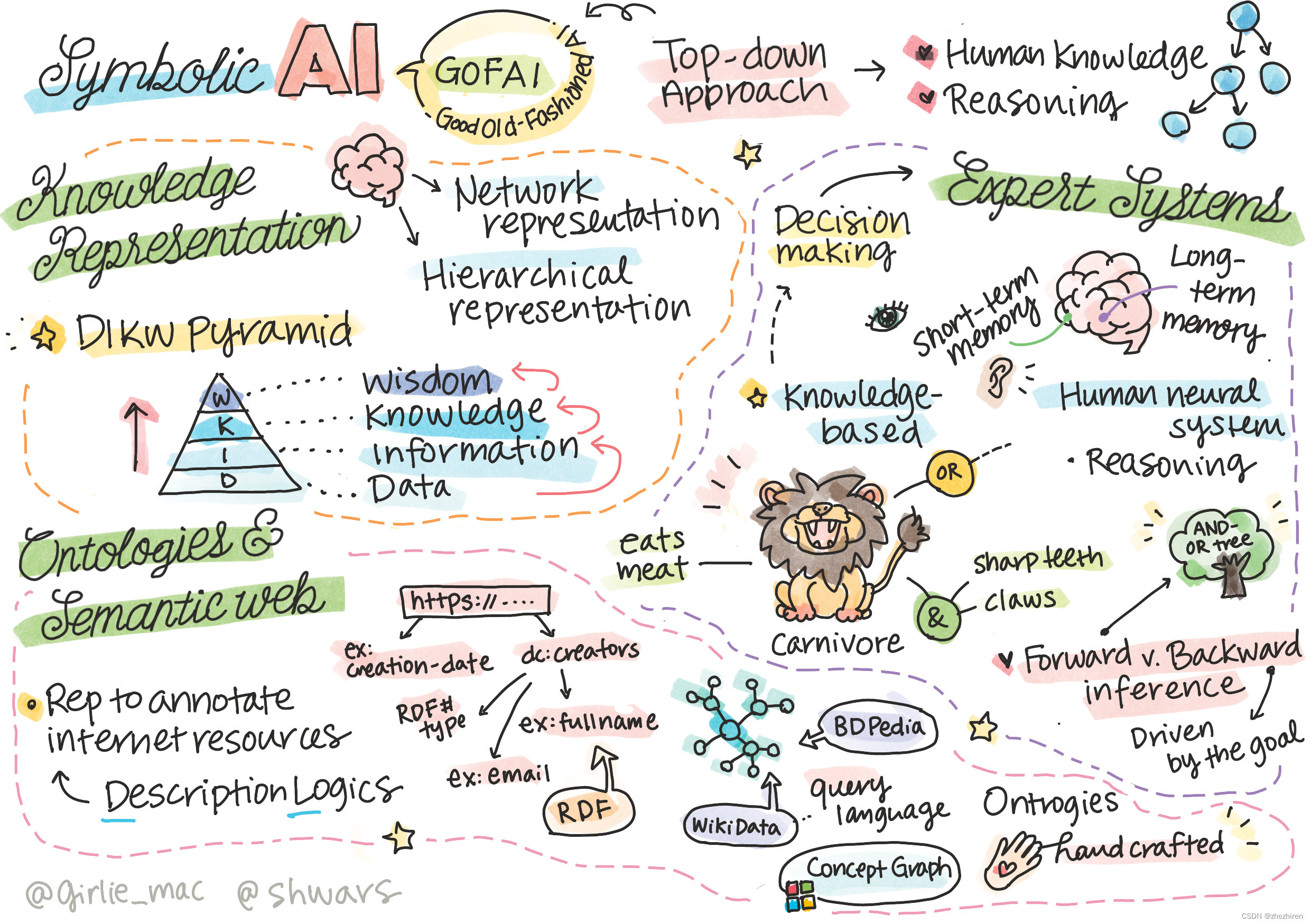
知识表示(Knowledge Representation)
本体论(Ontologies)和语义网(Semantic Web)
 Tomomi Imura速写笔记由Tomomi Imura绘制
Tomomi Imura速写笔记由Tomomi Imura绘制
探索人工智能是基于对知识的检索,以类似于人类的方式来理解世界。我们要如何实现这一点呢?
课前练习
早期的人工智能领域,基于自上而下的方法创建智能系统(在上一课有讨论)是非常流行的。实现方式就是从人类那里将知识提取成计算机可识别的形式,再利用它来自动解决问题。这种方法基于两个重要思想:
- 知识表达
- 推理
知识表示(Knowledge Representation)
知识是符号人工智能中最重要的概念之一。区别知识和信息或者数据很重要。比如说,我们可以说书本包含知识,因为我们能从书本学习,从而成为一个专家。但是,书本实际上包含的内容是数据,我们通过阅读书本将这些数据整合进我们的世界观,从而将数据转化为知识。
✅ 知识是存在于我们脑海里面,表达我们对世界的理解的东西。它是通过主动的学习过程获得的,该过程将我们接收到的信息片段整合到我们对世界的主动模型中。
大多数时候,我们没有严格的定义知识,而是将其和DIKW 金字塔(DIKW Pyramid,即Data、Information、Knowledge、Wisdom)等相关概念对齐:
- 数据(Data)是物理媒介中的表示,比如说书面文本或者口头语言。数据的存在独立于人类,能够人际间传播。
- 信息(Information)是在我们脑海对数据的理解。例如我们听到计算机一词,我们就对它有一定的理解。
- 知识(Knowledge)是整合在我们的世界模型中的信息。例如,一旦我们了解了计算机是什么,我们就开始对它的工作原理,它的成本,它的用途有一些概念。这个相互关联的概念的网络构成了我们的知识。
- 智慧(Wisdom)是我们对世界理解的又一个层次,他代表元知识,比如,如何以及何时使用知识的一些概念。
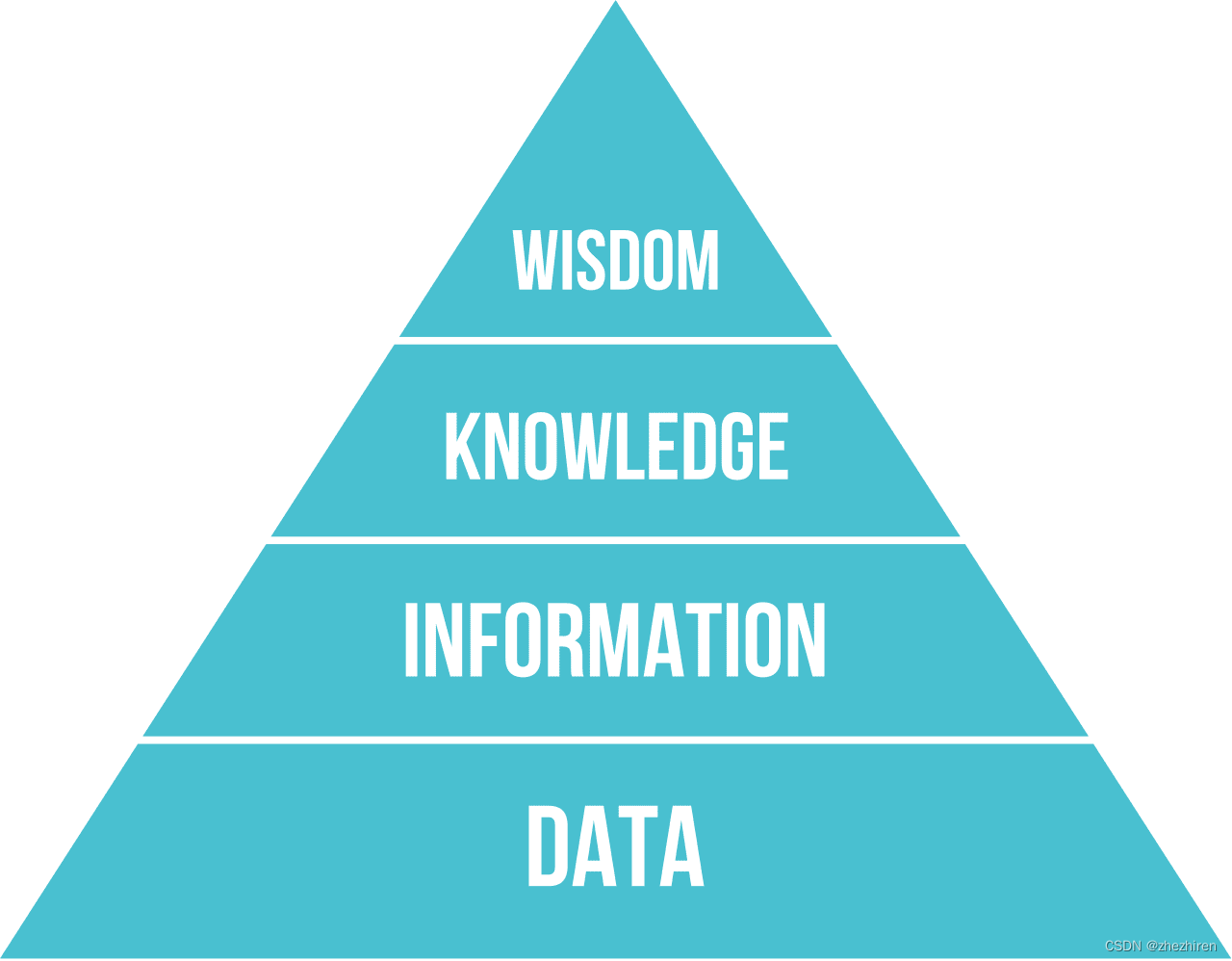
摘自维基百科, 作者Longlivetheux, CC BY-SA 4.0
因此,“知识表示”的问题是找到某个有效的方法,将计算机内的知识用“数据”的形式表示出来,使其自动可用。这可以看作是一个频谱:

图片由Dmitry Soshnikov提供
- 在左侧,有一些非常简单的,可供计算机有效使用的知识表示类型。当知识被计算机程序所表示时,其中最简单的方法是算法性的。然而,这不是表示知识的最佳方法,因为算法并不够灵活。在我们脑海中的知识很多时候是非算法性的。
- 在右侧,有类似自然文本等表示方式。这种方式最强大,但是不能用来自动推理。
✅ 花几分钟想想,你如何在你大脑里表示知识,并把它转化为笔记。是否有一种特别适合您的方式,有利于您增强记忆?
对计算机知识表示进行分类
我们能够将计算机知识表示分成以下几个类别:
- “网络表征”(Network representations )基于这么一个事实:我们的大脑内有一个相互关联的概念网络。我们可以尝试在计算机内重现相同的图形网络,叫做语义网络。
1“对象-属性-值”三元组(Object-Attribute-Value)或者“属性-值”对(attribute-value pairs )。由于图在计算机中能够表示为 “节点”( node)和“边”(edge)列表,因此我们可以通过使用包含“对象”(object)、属性(attribute)和值(value)的三元组列表来表示语义网络。例如,我们构建了以下关于编程语言的三元组:
| 对象 | 属性 | 值 |
| Python | is | Untyped-Language |
| Python | invented-by | Guido van Rossum |
| Python | block-syntax | indentation |
| Untyped-Language | doesn't have | type definitions |
✅ 想想如何使用三元组来表示其他类型的知识。
2 “分层表示”(Hierarchical representations)强调这么个事实:我们通常在我们的大脑中创建对象的层级结构。例如,我们知道金丝雀是鸟,所有的鸟都有翅膀。我们也知道金丝雀通常有哪些颜色,以及它们的飞行速度是多少。
- “框架表示”( Frame representation)基于如下事实:将“对象”(object)或者“类”(class)表示为一个包含许多“槽”(slot)的“框架”(frame)。槽可能有默认值,值有限制范围,或者可以获取槽的值的存储过程。所有的框架形成一个层次结构,类似于面向对象编程语言中的对象层次结构。
- “场景”( Scenarios)是一种特殊的框架,用来表示可以及时展开的复杂情况。
Python
| 槽(Slot) | 值(Value) | 默认值(Default value) | 区间(Interval) |
| Name | Python | ||
| Is-A | Untyped-Language | ||
| Variable Case | CamelCase | ||
| Program Length | 5-5000 lines | ||
| Block Syntax | Indent |
3.过程表示(Procedural representations )是基于通过在特定条件发生时可执行的一系列可执行的动作来表达知识。
- 产生式规则是一系列可以让我们我们得出结论的if-else声明语句。比如,医生可以制定一个规则:如果病人发高烧或者血液检测中c-反应蛋白较高,则说明他患有有炎症。如果我们遇到上述一种情况,我们就能够确诊炎症,然后在后续的推理中使用这个结论。
- 算法可以看做另一种形式的过程表示,尽管它们几乎从未直接在基于知识的系统中被使用。
4.逻辑最开始是由亚里士多德提出来的,作为表示人类普遍知识的一种方式。
- 谓词逻辑(Predicate Logic)作为一个数学理论因过于丰富而无法计算,因此通常使用其子集,比如说在Prolog中使用的霍恩子句(Horn clauses)。
- 描述逻辑(Descriptive Logic)是一组逻辑系统,用于表示和推理对象的分布式知识表示(比如语义网络- semantic web)的分层系统。
专家系统(Expert Systems)
符号人工智能的早期的成功(symbolic AI)之一是--所谓的专家系统--一个设计用来在某些有限的问题领域充当专家的计算机系统。他们基于从一个或多个人类专家那里提取的知识库,并包含一个在知识库基础上执行推理的推理引擎。
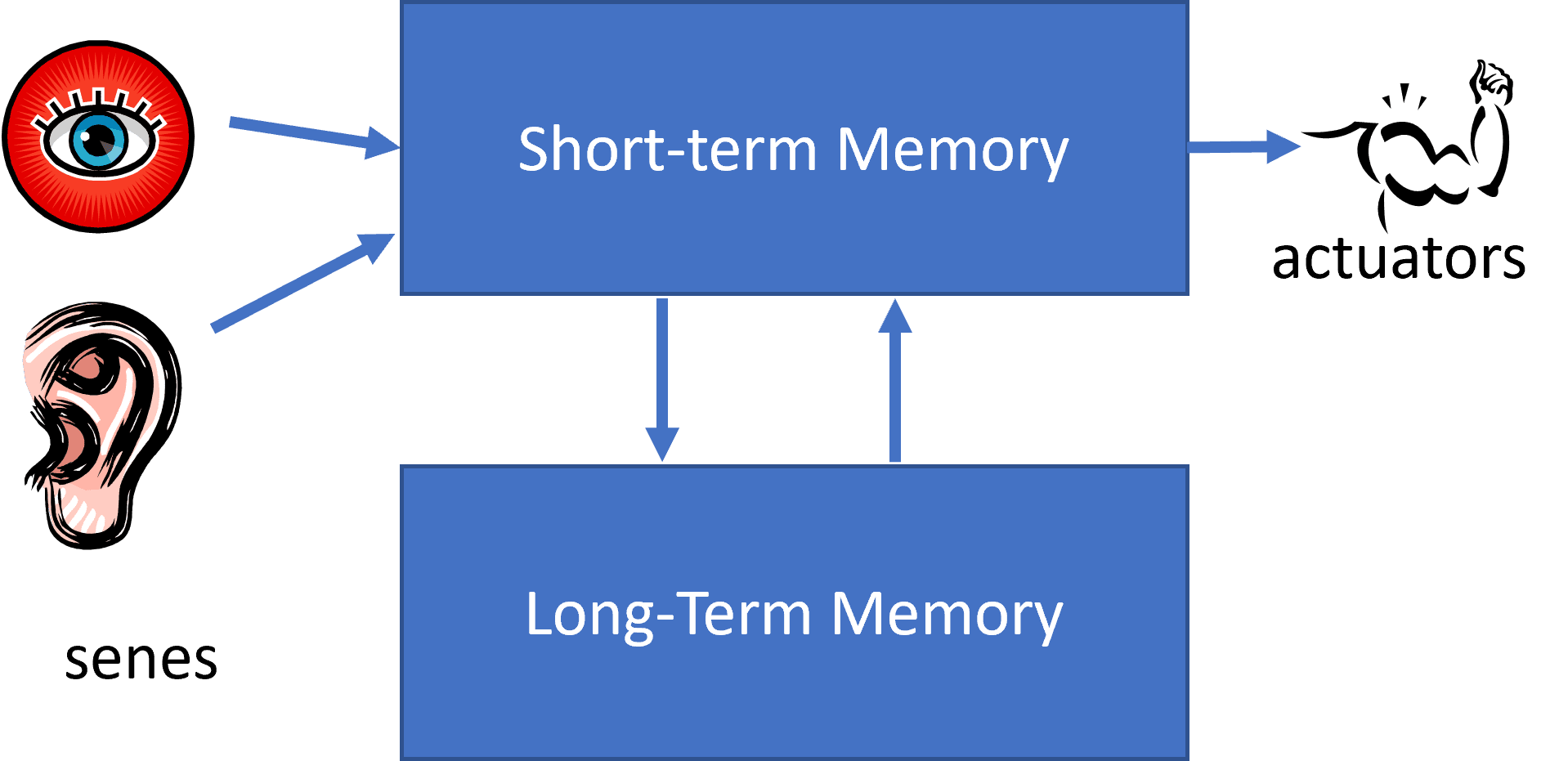 | 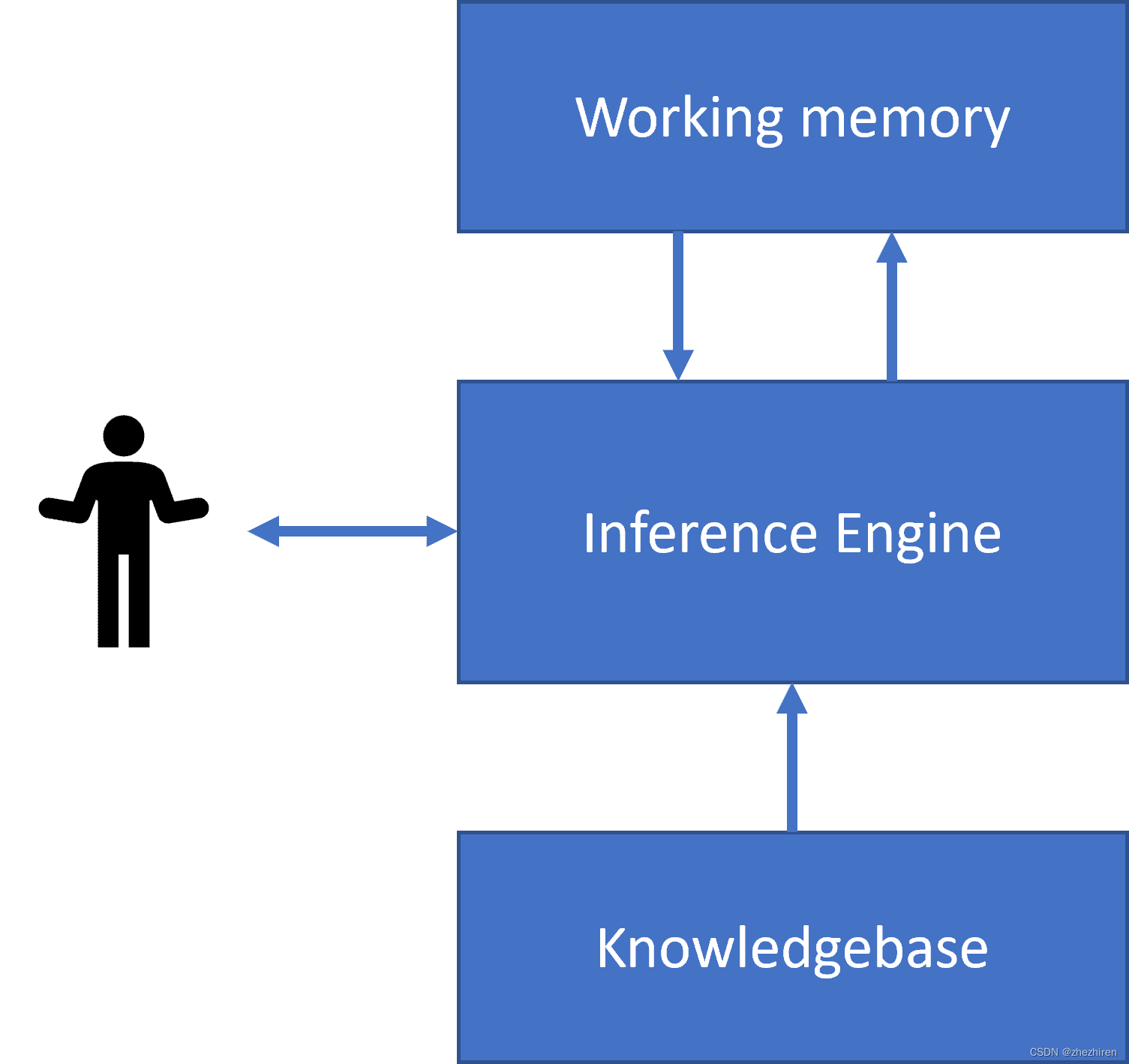 |
| 类神经系统的简化结构 | 知识库系统的架构 |
专家系统的构建类似于人类的推理系统,包含一个短期记忆和长期记忆。同样,在知识库系统中我们区分如下组件:
- 问题内存(Problem memory):包含当前正在解决的问题的知识,比如患者的体温或者血压,他是否有炎症,等等。这些知识也被称作静态知识(static knowledge),因为它包含了我们目前所知道的问题的快照-即问题状态。
- 知识库(Knowledge base):表示某个问题领域的长期知识。它是人类专家那里人工提取的,并且不会因咨询而变更。因为它允许我们从一个问题状态导航至另一个问题状态,所以它也被称作动态知识(dynamic knowledge)
- 推理引擎:协调在问题状态空间中搜索的整个过程,并在必要时向用户提出问题。它同时负责寻找使用于每个状态正确的规则。
以下是一个例子:让我们考虑以下根据动物的物理特征来识别动物的专家系统:
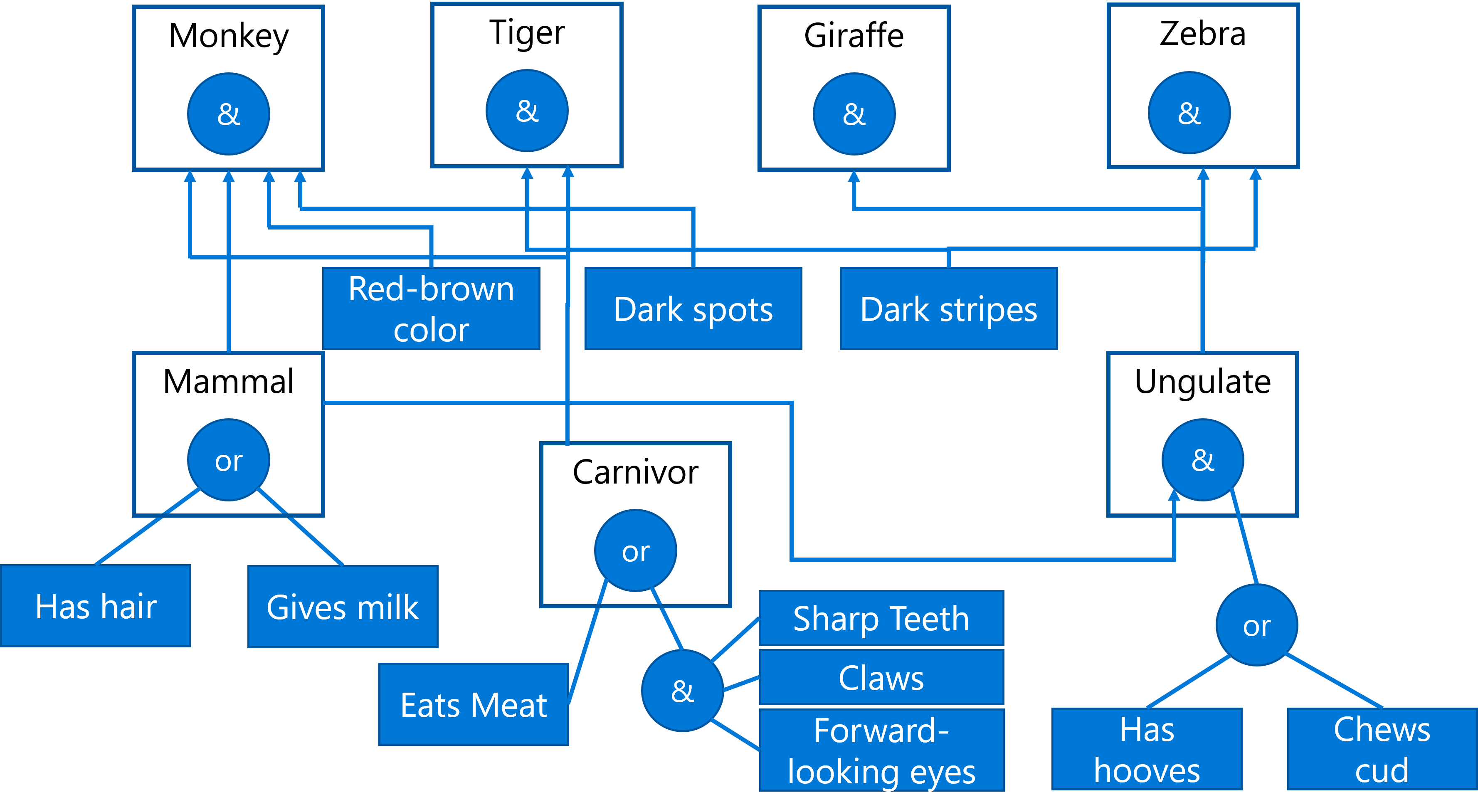
图片由 Dmitry Soshnikov提供
这个示意图被称作“与或树”( AND-OR tree),他是一系列产生式规则的图形表示。在开始从专家那里提取知识时,绘制一棵树是非常有用的。在计算机内部采用规则来表示知识往往更方便::
IF 动物吃肉
OR (动物有锋利的牙齿
AND 动物有爪子
AND 动物有朝前看的眼睛
)
THEN 动物是食肉动物
你能注意到,规则的左边的每个条件和操作,本质上是对象-属性-值(OAV)三元组。工作内存中包含与当前正在解决的问题相对应的OAV三元组集合。规则引擎查找那些满足条件的规则并应用他们,并将另一些三元组添加到工作内存中。
✅写一个你自己喜欢的主题的AND-OR tree
前向推理vs.后向推理
前面讨论的流程叫做前向推理。它从工作内存中的某些关于问题的初始化数据开始,执行如下推理环路:
- 如果目标属性存在于工作内存中,返回结果并终止进程。
- 查找那些当前满足条件的所有规则-获得冲突的规则集。
- 执行冲突解决-选择一个在这一步将会执行的规则。可能有不同的冲突解决策略:
- 选择知识库中第一个适合的规则
- 随机选择一个规则
- 选择一个更明确的规则,比如说,选择满足最多左侧(LHS)条件的规则
- 应用所选择的规则,并把新的知识片段插入问题状态中。
- 从步骤1重复执行。
然而,在某些情况下,我们需要处理某些问题,它一开始并不包含任何的知识(信息),通过询问问题,帮助我们达成结论。例如,我们进行医疗诊断,我们通常不会在诊断病人的一开始就执行所有医疗分析。我们更愿意在需要做判断的时候,再执行分析。
这个过程可以采用后向推理进行建模。他由目标(我们需要寻找的属性值)驱动:
- 选择所有提供目标值的规则(即在右侧(RHS)的目标)--一个冲突性集合。
- 如果已有的属性无法确定规则,或者另一方面存在这样一个规则,我们需要额外向用户询问一个值,则询问这个问题:
- 采用冲突解决策略选择一个我们假设的规则—然后我们尝试证明它
- 对这个规则的左侧(LHS)的属性重复执行这个过程,尝试证明他们是正确的目标(即证明所有的属性都满足假定的规则)。
- 如果在过程中任意位置失败了,采用步骤3中的另一个规则重新执行。
✅在哪种情况下,前向推理更合适?哪种情况下后向推理更合适?
专家系统实施
专家系统可以通过不同的工具实施:
采用某些高级编程语言直接编码实现他们。这不是最佳方法,因为知识库系统的主要优点是知识与推理分离,同时潜在问题领域的专家应该能够在不了解推理过程细节的情况下编写规则。
使用专家系统脚本,比如,采用某种知识表示语言专门设计一个系统用来补充知识。
✍️练习:动物推理
看Animals.ipynb中实现前向推理专家系统和后向推理专家系统的例子。
注意:这个示例相当简单,仅仅提供怎么样建立专家系统的方法。一旦你开始构建这样一个系统,只有达到一定数量的规则(大约200+),你才能注意到其中的一些智能行为。在某些时候,规则因变得变得太复杂而不能全部记住,这个时候,你可能会想知道系统为什么会作出某些决定。而基于知识库的系统的重要特征就是,你始终能准确解释系统是如何作出任一决策的。
本体论(Ontologies)和语义网(Semantic Web)
20世纪末,出现了使用知识表示来注解互联网资源的倡议,以便可以找到某个非常具体的查询条件相对应的资源。这个提议被称作语义网(Semantic Web),它依赖于如下几个概念:
- 一个基于描述逻辑(DL)的特殊知识表示。它类似于框架知识表示,因为它构建了一个拥有属性的对象的层次结构,但是它拥有规范的逻辑语义和推理。它有一组完整的描述逻辑(DL)系列,平衡了表示能力和推理算法的复杂性之间的关系。
- 分布式知识表示,其中所有概念都使用全局统一资源标识符(URI)表示,使得跨互联网创建知识层次结构成为可能。
- 一系列基于XML的知识描述语言:RDF(Resource Description Framework),RDFS (RDF Schema), OWL (Ontology Web Language)。
语义网络的一个核心概念是本体论(Ontology)。它是指使用某种形式的知识表示来对问题域进行明确规范。最简单的本体论可以是问题域中对象层级结构,但更复杂的本体包含可以用来推理的规则。
在语义网络中,所有的表示都是基于三元组。每个对象以及关系都使用URI唯一标识。例如,如果我们生命这个AI课程是由Dmitry Soshnikov在2022-01-01开发的这个事实,以下是我们可以使用的三元组:

1. http://github.com/microsoft/ai-for-beginners http://www.example.com/terms/creation-date “Jan 13, 2007”
2. http://github.com/microsoft/ai-for-beginners http://purl.org/dc/elements/1.1/creator http://soshnikov.com
✅ 在这里 http://www.example.com/terms/creation-date 和
http://purl.org/dc/elements/1.1/creator 是一些众所周知且普遍接受的URI,用于表达创作者和创建时间的概念。
在更复杂的情况下,如果我们想定义一系列创作者,我们可以使用某些定义在RDF中的数据结构。
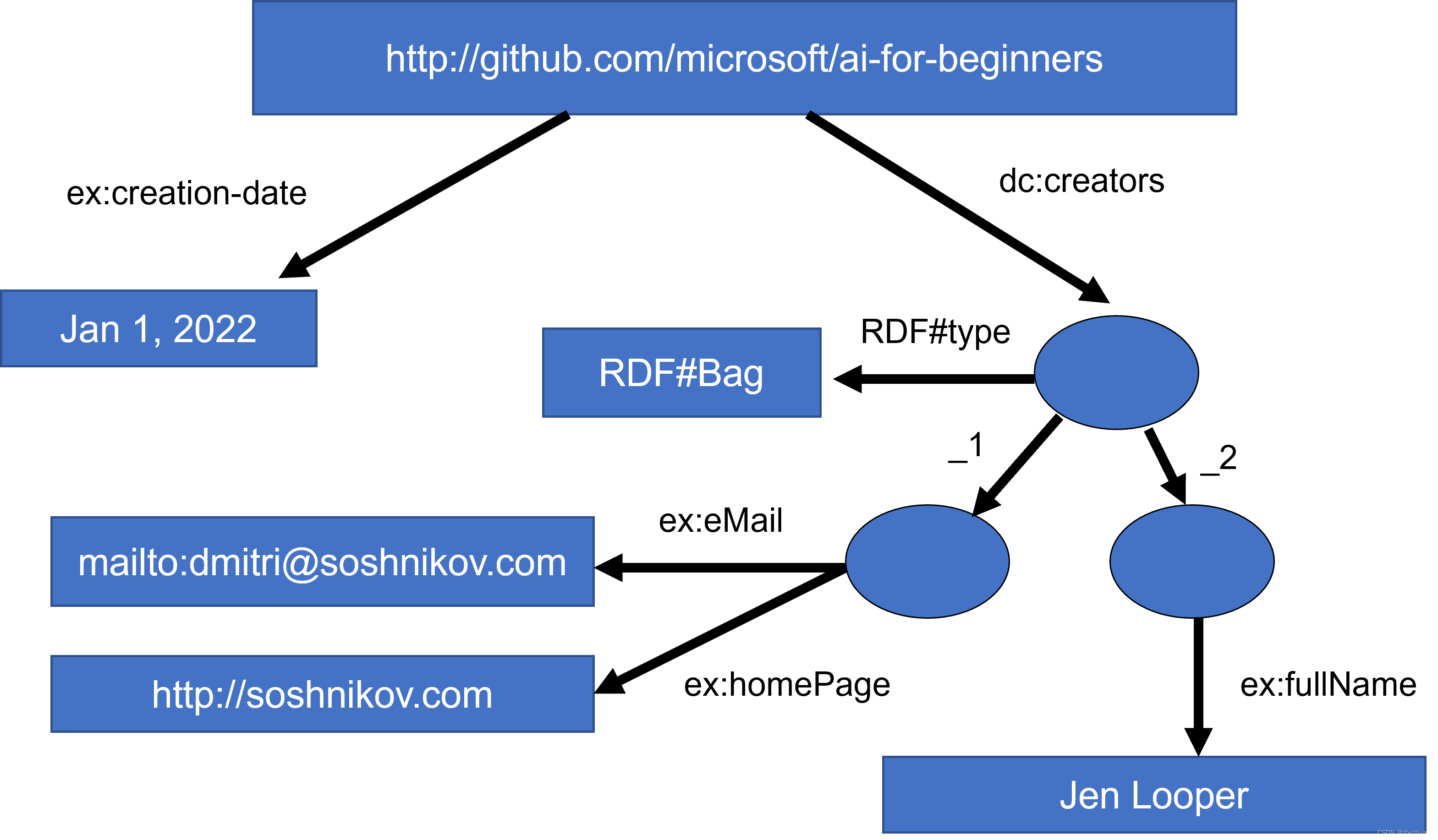
图像由 Dmitry Soshnikov提供
搜索引擎和自然语言处理技术(可以在文本中提取结构化数据)的成功减缓了语义网络的建设进程。然而,在某些领域,还是有一些出色的成就维持本体论和知识库的发展。以下是一些值得注意的工程
- WikiData是一个与维基百科相关的机器可读的知识库集。大部分数据是从维基百科信息框(infobox,维基百科页面内的结构化内容)中挖掘出来的。你能够使用SPARQL(一种语义网络的专用查询语言)查询wikidata。以下是一个查询示例,显示人类中最受欢迎的眼睛颜色(查询地址https://query.wikidata.org/):
#defaultView:BubbleChart
SELECT ?eyeColorLabel (COUNT(?human) AS ?count)
WHERE
{
?human wdt:P31 wd:Q5. # human instance-of homo sapiens
?human wdt:P1340 ?eyeColor. # human eye-color ?eyeColor
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
GROUP BY ?eyeColorLabel
- DBpedia是另一个类似于wikiData的项目。
✅如果你想试验你自己的本体,或者打开某个现有的,有一个很棒的可视化的本体编辑器叫Protégé。下载它,或者在线使用它。
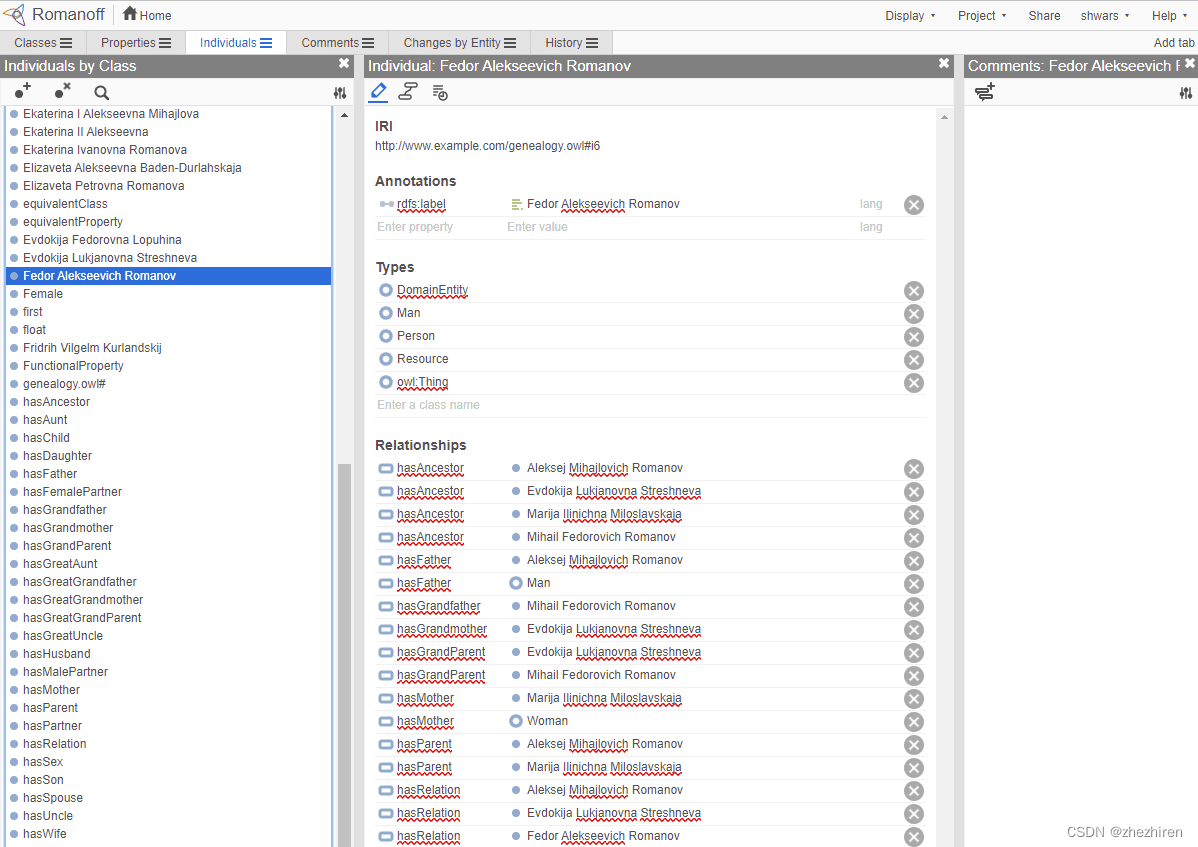
使用Web ProtégéW编辑器打开the Romanov Family ontology
由Dmitry Soshnikov 截图
✍️练习:一个家庭本体
参考FamilyOntology.ipynb,使用语义网络技术推理家庭关系的示例。我们将使用通用GEDCOM 格式构建一个族谱的表示,和一个家庭关系的本体,并为给定的一组个体构建一个所有家庭关系的图形。
微软概念图
在大多数情况下,本体(ontology)是人工精心创建的。然而,也可以从非结构化数据中挖掘本体,如从自然语言文本中挖掘。
微软研究研究在做这种尝试,并且产生了Microsoft Concept Graph。
它是一个使用is-a继承关系进行的分组的大型实体集合。它可以回答诸如 “什么是微软?”这类问题 - 答案接近于“85%概率是一家公司,75%概率是一个品牌”。
该图(上述集成关系图)可以通过REST API调用,也可以下载为一个列出所有实体对的大型文本文件。
✍️练习:一个概念图
尝试MSConceptGraph.ipynb笔记本,了解如何使用Microsoft Concept Graph 将新闻文章分组为几个类别。
总结
如今,人工智能通常被认为是机器学习或者神经网络的同义词。然而,人类也明显的展示出推理能力,这是神经网络无法处理的。在实际项目中,显示推理仍然用于执行需要解释的任务,或者能够以受控的方式修改系统行为的任务中。
挑战
在与本课程相关的家庭本体代码笔记(notebook)中,有机会实验其他家庭关系。尝试在族谱中发现人们之间新的关系。
课后练习
复习和自学
在互联网上研究,人类在哪些领域尝试了量化和系统化知识。关注一下布鲁姆(Bloom)的分类法,回顾历史,学习人类如何尝试理解他们的世界。探索林奈(Linnaeus)创造生物分类法的工作,并观察德米特里·门捷列夫(Dmitri Mendeleev)创造的化学元素的描述与分组的方法。你还能找到其他什么有趣的例子?
作业
上一章:一、人工智能简介
下一章:三、感知器
更多章节:人工智能入门课程

















 7195
7195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









