






绝了,不用写代码也能训练大语言模型!🚀

LLaMA-Factory 是一个基于大型语言模型的微调框架,允许用户通过自定义数据集来优化模型表现。微调大模型可以如此轻松…
只需要在界面操作,无需写代码,即可以进行大模型训练
项目特色 🌟
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:增量预训练、多模态指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等。
- 多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
性能指标 📈
与 ChatGLM 官方的 P-Tuning 微调相比,LLaMA-Factory 的 LoRA 微调提供了 3.7 倍的加速比,同时在广告文案生成任务上取得了更高的 Rouge 分数。结合 4 比特量化技术,LLaMA-Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。
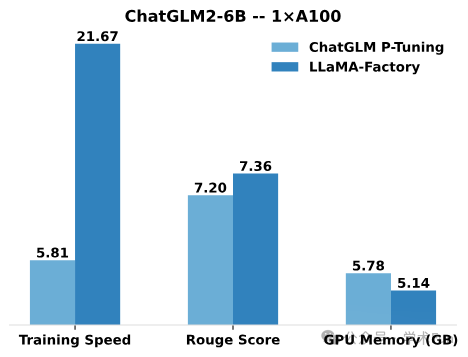 性能对比
性能对比
学术Fun 提供了一键启动包,点击即可使用,避免配置环境出现各种问题。下载地址(电脑浏览器访问):https://xueshu.fun/4757/。
电脑配置要求
- Windows 10/11 64位操作系统
下载使用教程 📥
-
下载压缩包
-
- 下载地址(电脑浏览器访问):https://xueshu.fun/4757/,在此页面右侧区域点击下载!
-
解压文件
-
- 最好不要有中文路径,解压后如下图所示,双击
启动.exe文件运行。
- 最好不要有中文路径,解压后如下图所示,双击
 解压文件
解压文件
-
浏览器访问
-
- 打开浏览器访问 http://127.0.0.1:7860/,即可在浏览器中使用。
支持的模型列表 📚
| 模型名 | 模型大小 | 默认模块 | Template |
|---|---|---|---|
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| Command-R | 35B/104B | q_proj,v_proj | cohere |
| DeepSeek (MoE) | 7B/16B/67B/236B | q_proj,v_proj | deepseek |
| Falcon | 7B/11B/40B/180B | query_key_value | falcon |
| Gemma/CodeGemma | 2B/7B | q_proj,v_proj | gemma |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | - |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| LLaMA-3 | 8B/70B | q_proj,v_proj | llama3 |
| LLaVA-1.5 | 7B/13B | q_proj,v_proj | vicuna |
| Mistral/Mixtral | 7B/8x7B/8x22B | q_proj,v_proj | mistral |
| OLMo | 1B/7B | q_proj,v_proj | - |
| PaliGemma | 3B | q_proj,v_proj | gemma |
| Phi-1.5/2 | 1.3B/2.7B | q_proj,v_proj | - |
| Phi-3 | 4B/7B/14B | qkv_proj | phi |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| Qwen1.5 (Code/MoE) | 0.5B/1.8B/4B/7B/14B/32B/72B/110B | q_proj,v_proj | qwen |
| StarCoder2 | 3B/7B/15B | q_proj,v_proj | - |
| XVERSE | 7B/13B/65B | q_proj,v_proj | xverse |
| Yi (1/1.5) | 6B/9B/34B | q_proj,v_proj | yi |
| Yi-VL | 6B/34B | q_proj,v_proj | yi_vl |
| Yuan | 2B/51B/102B | q_proj,v_proj | yuan |
训练方法 🔧
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ✅ | ✅ |
| PPO 训练 | ✅ | ✅ | ✅ | ✅ |
| DPO 训练 | ✅ | ✅ | ✅ | ✅ |
| KTO 训练 | ✅ | ✅ | ✅ | ✅ |
| ORPO 训练 | ✅ | ✅ | ✅ | ✅ |
| SimPO 训练 | ✅ | ✅ | ✅ | ✅ |
硬件依赖 💻
估算值
| 方法 | 精度 | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| Freeze | 16 | 20GB | 40GB | 80GB | 200GB | 360GB | 160GB | 400GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
各位新老朋友,麻烦点个赞👍和在看👀吧!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 3060
3060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









