






背景
Llama 3是支持中文的,但是明显对中文世界还是不太擅长。
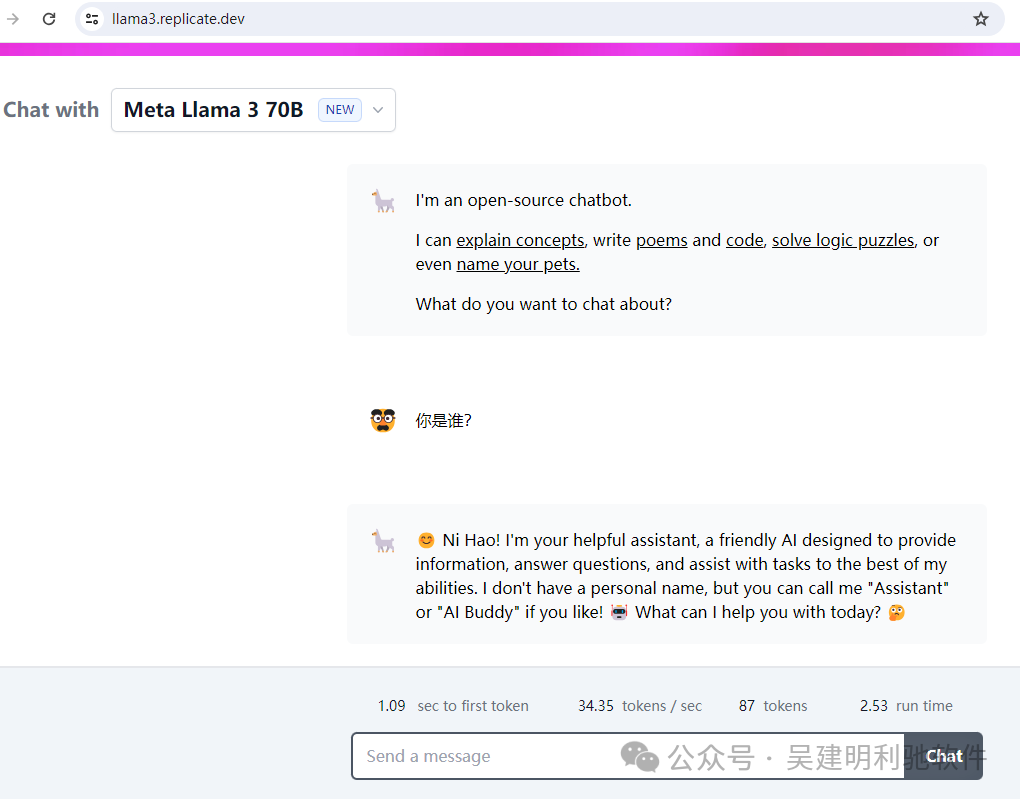
速度很快,中文支持不行
那``微调、量化、本地知识库的接入、部署、及Agent上线的技术路线是什么?
1、微调
使用中文得到更好的支持需要进行微调,最简单的方法之一是使用Llama Factory。
它几乎不需要任何编程基础,直接使用即可微调出一个适用于您的模型。

Llama Factory的主要特色
-
• 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen(阿里通义)、Yi(零一万物)、Gemma、Baichuan(百川)、ChatGLM(智谱)、Phi 等等。
-
• 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
-
• 多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
-
• 先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调。
-
• 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
-
• 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
-
• 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
微调过程的视频
微调的数据集
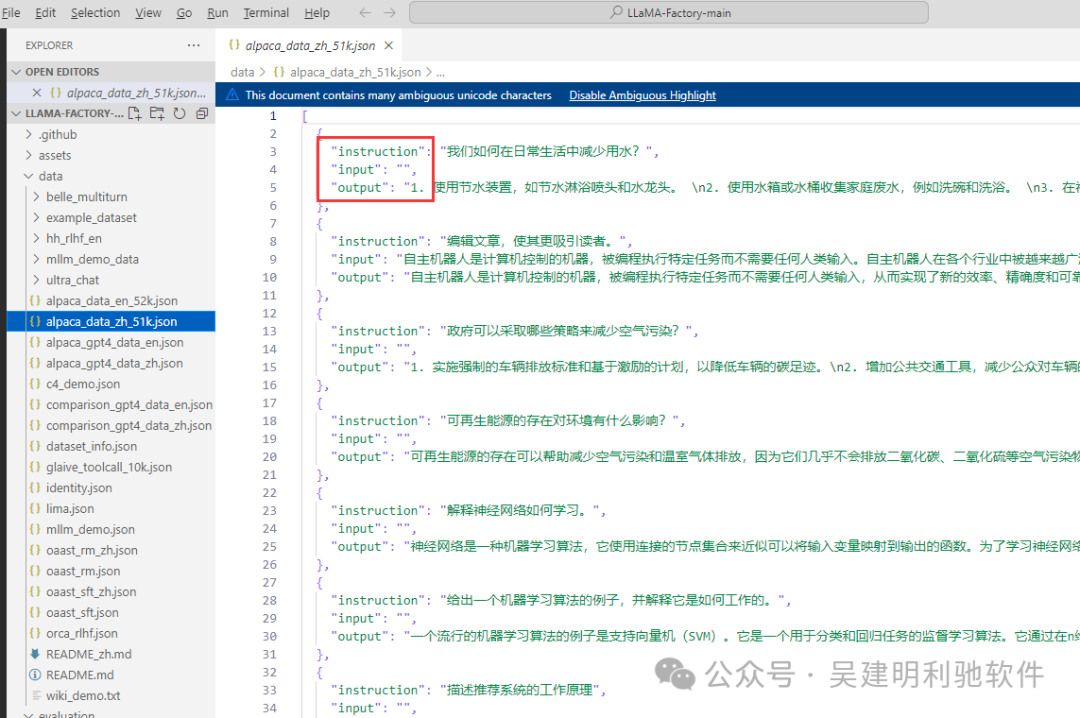
2、量化
微调出来的这个模型有点太大了,推理的时候速度比较慢,占用显存比较多,这时需要量化。
大模型量化主要是为了减小模型的体积和提高运算速度,让模型在资源有限的设备上也能高效运行。同时,量化还能降低能耗和成本,让模型部署更加经济实用。
那量化的时候有没好用的框架呢?
最常见的就是直接用Llama.Cpp。可以快速的帮我们把这个模型给它量化的比较小。

llama.cpp 的主要目标是在本地和云端的各种硬件上以最少的设置和最先进的性能实现 LLM 推理。
量化后,大小能缩小到原来的 31 。
3、本地知识库接入、部署、智能体上线
最后就是,本地知识库接入、部署、智能体上线。
有没简单的方式去做呢?
Phidata做了很好的封装,它不用我们做太多繁琐的操作。
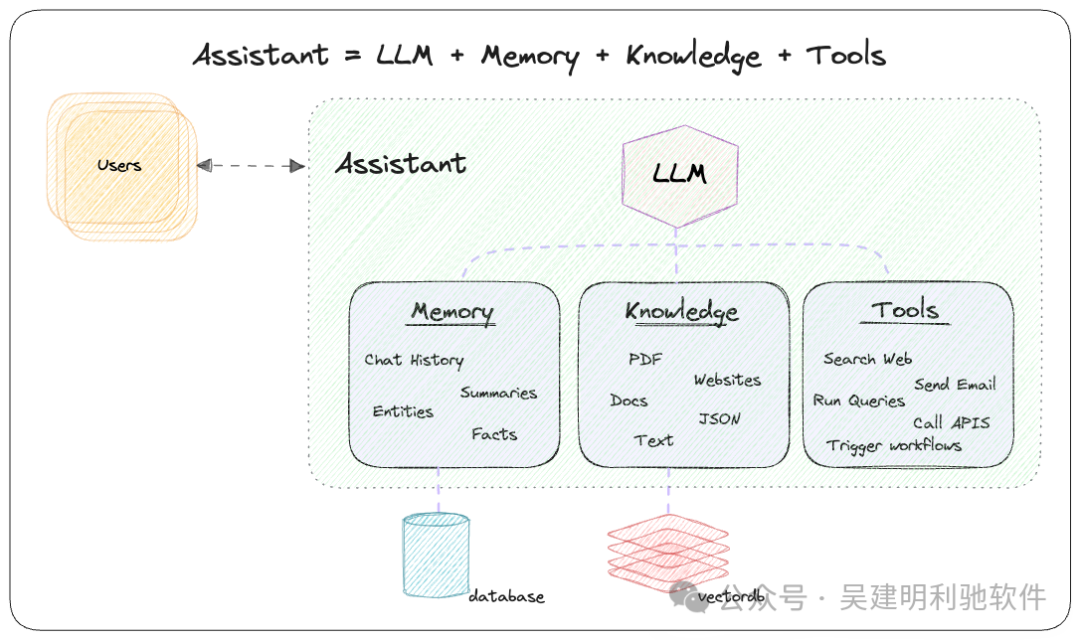
Phidata为LLMs添加了记忆、知识库和工具。只需要做简单的配置。
3步运行
1、创建 Assistant
2、添加工具(功能)、知识(矢量数据库)和存储(关系型数据库)
3、使用 Streamlit、FastApi 或 Django 构建我们的AI 应用程序
**比如:**读取本地 docx 文件,将其转换为向量嵌入并将其加载到向量数据库中。
from phi.knowledge.text import DocxKnowledgeBase from phi.vectordb.pgvector import PgVector from resources import vector_db knowledge_base = DocxKnowledgeBase( path="data/docs", # Table name: ai.docx_documents vector_db=PgVector( collection="docx_documents", db_url=vector_db.get_db_connection_local(), ), )
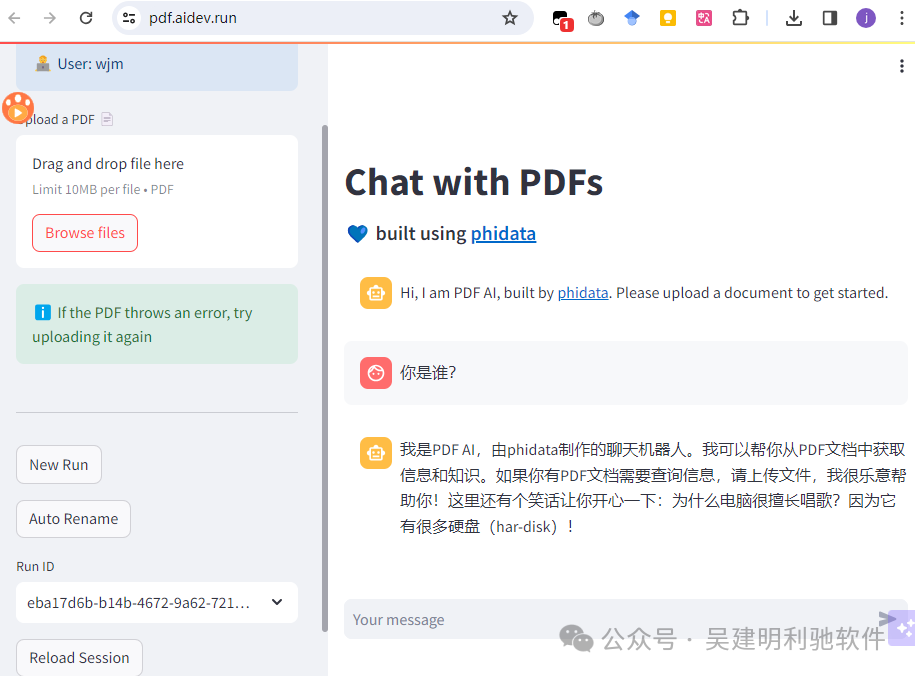
最后看看效果
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









