







1
安装python 虚拟环境
安装 Miniconda3
Step 1: 下载
$ wgethttps://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
Step2: 运行脚本
$ sh Miniconda3-latest-Linux-x86_64.sh
Step3: 设置环境变量
vi /etc/profile
export PATH=“/data/apps/miniconda3/bin:$PATH”
source /etc/profile
Step 4: 卸载
$ rm -rf /data/apps/miniconda3/
创建虚拟环境
//创建
conda create -n test python=3.10
退出shell 重新登录 才生效
//激活
conda activate test
//销毁
conda deactivate test
//查看
conda info --env
2Vanna 借助 OpenAI, Marqo 生成 MySql SQL语句
2.1Vanna三个主要基础设施
1Database,即需要进行查询的关系型数据库
2VectorDB,即需要存放RAG“模型”的向量库
3LLM,即需要使用的大语言模型,用来执行Text2SQL任务

2.2下载向量数据库marqo
docker pull docker.rainbond.cc/marqoai/marqo:latest
docker run --name marqo -it -p 8882:8882 docker.rainbond.cc/marqoai/marqo:latest
需要服务器翻墙才能从hf上下载下来
open_clip/ViT-B-32/laion2b_s34b_b79k
hf/e5-base-v2

安装marqo客户端
(test) root@ubuntu:/data/scripts# pip install marqo
测试marqo client
(test) root@ubuntu:/data/scripts# cat marqo_test.py
import marqo
mq = marqo.Client(url='http://10.0.2.15:8882')
mq.delete_index("my-first-index")
mq.create_index("my-first-index", model="hf/e5-base-v2")
mq.index("my-first-index").add_documents([
{
"Title": "The Travels of Marco Polo",
"Description": "A 13th-century travelogue describing Polo's travels"
},
{
"Title": "Extravehicular Mobility Unit (EMU)",
"Description": "The EMU is a spacesuit that provides environmental protection, "
"mobility, life support, and communications for astronauts",
"_id": "article_591"
}],
tensor_fields=["Description"]
)
results = mq.index("my-first-index").search(
q="What is the best outfit to wear on the moon?"
)
print(results)
(test) root@ubuntu:/data/scripts#

2.3mysql 数据库导入
数据库表结构和数据
mysql> show create table host;
| host | CREATE TABLE `host` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`ApplicationID` varchar(128) DEFAULT NULL COMMENT '应用ID',
`AssetID` int(11) DEFAULT NULL COMMENT '资产ID',
`BakOperator` varchar(128) DEFAULT '' COMMENT '备份操作人',
`Cpu` int(3) NOT NULL DEFAULT '0' COMMENT 'CPU',
`CreateTime` datetime NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '创建日期',
`Description` varchar(256) DEFAULT '' COMMENT '备注',
`Env` varchar(20) DEFAULT NULL,
`DeviceClass` varchar(50) DEFAULT '一级',
`HostName` varchar(32) NOT NULL DEFAULT '' COMMENT '主机名',
`InnerIP` varchar(128) NOT NULL DEFAULT '' COMMENT '网内地址',
`LastTime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新日期',
`Mem` int(8) NOT NULL DEFAULT '0',
`OS_kernel` varchar(128) DEFAULT NULL,
`Operator` varchar(128) DEFAULT '' COMMENT '管理员',
`OS_type` varchar(128) NOT NULL DEFAULT '' COMMENT '系统类型',
`OuterIP` varchar(128) NOT NULL DEFAULT '' COMMENT '外网地址',
`Status` varchar(10) DEFAULT '1',
`Extend001` varchar(255) NOT NULL DEFAULT '',
`Extend002` varchar(255) NOT NULL DEFAULT '',
`Extend003` varchar(255) NOT NULL DEFAULT '',
`Extend004` varchar(255) NOT NULL DEFAULT '',
`Extend005` varchar(255) NOT NULL DEFAULT '',
`Disk_mount` varchar(255) DEFAULT NULL COMMENT '硬盘挂载信息',
`Disk` int(8) DEFAULT NULL COMMENT '硬盘信息',
`IdcName` varchar(128) DEFAULT '' COMMENT '机房名称',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=614 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='主机基础信息表' |
mysql> show create table server;
| server | CREATE TABLE `server` (
`ApplicationID` int(11) DEFAULT NULL COMMENT '应用ID',
`ID` int(64) NOT NULL AUTO_INCREMENT COMMENT '主键',
`HardMemo` varchar(16) NOT NULL DEFAULT '' COMMENT '服务器品牌型号',
`Cpu_model` varchar(128) DEFAULT '0' COMMENT 'CPU',
`Cpu_number` int(4) DEFAULT NULL COMMENT '物理cpu个数',
`HostName` varchar(32) NOT NULL DEFAULT '',
`DeviceClass` varchar(50) DEFAULT '一级',
`Region` varchar(8) DEFAULT '' COMMENT '区域-ucloud使用',
`OS_type` varchar(32) DEFAULT '' COMMENT '系统类型',
`OS_kernel` varchar(32) NOT NULL DEFAULT '' COMMENT '系统内核',
`SN` varchar(32) NOT NULL DEFAULT '' COMMENT 'SN编号',
`ServerRack` varchar(16) NOT NULL DEFAULT '' COMMENT '架机号',
`CreateTime` datetime NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '创建日期',
`IdcName` varchar(128) DEFAULT '' COMMENT '房机名称',
`LastTime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新日期',
`Operator` varchar(128) NOT NULL DEFAULT '' COMMENT '理管员',
`BakOperator` varchar(128) DEFAULT '' COMMENT '备份操作人',
`Status` varchar(10) DEFAULT '1',
`ManagerIP` varchar(128) NOT NULL DEFAULT '' COMMENT '管理地址',
`Raid` varchar(255) DEFAULT NULL COMMENT 'raid级别',
`Is_virtualization` varchar(10) DEFAULT '1',
`InnerIP` varchar(128) NOT NULL DEFAULT '' COMMENT '网内地址',
`OuterIP` varchar(128) DEFAULT '' COMMENT '外网地址',
`Description` varchar(256) NOT NULL DEFAULT '' COMMENT '备注',
`Extend001` varchar(255) DEFAULT NULL,
`Extend003` varchar(255) DEFAULT '',
`Extend004` varchar(255) DEFAULT '',
`Extend005` varchar(255) DEFAULT '',
`Extend002` varchar(255) DEFAULT '',
`Cpu_cores` int(4) DEFAULT NULL COMMENT 'cpu核数',
`Mem` int(18) DEFAULT '0',
`Disk_mount` varchar(2000) DEFAULT NULL COMMENT '硬盘分区',
`Disk_total` int(255) DEFAULT NULL COMMENT '硬盘',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=33 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='资产基础信息表' |
mysql>
2.4OpenAI 模型准备
私有化部署自己的模型或者使用 siliconflow.cn 免费体验 获取apikey 和 base_url
2.5Vann使用本地向量数据库和OpenAI测试MySQL
安装相应的包:
%pip install 'vanna[marqo,openai,mysql]'
(base) root@ubuntu:/data/scripts# more vanna_test.py
from vanna.openai import OpenAI_Chat
from vanna.marqo import Marqo_VectorStore
from openai import OpenAI
MARQO_URL='http://10.0.2.15:8882'
MARQO_MODEL="hf/e5-base-v2"
client = OpenAI(
api_key="EMPTY",
base_url="http://111.111.111.111:30880/v1/"
)
class MyVanna(Marqo_VectorStore, OpenAI_Chat):
def __init__(self,client=None, config=None):
Marqo_VectorStore.__init__(self, config={'marqo_url': MARQO_URL, 'marqo_model': MARQO_MODEL})
OpenAI_Chat.__init__(self,client=client, config=config)
vn = MyVanna(client=client, config={"model": "Qwen2.5-72B-Instruct"})
vn.connect_to_mysql(host='192.168.0.13', dbname='test', user='test', password='123456', port=3306)
from vanna.flask import VannaFlaskApp
VannaFlaskApp(vn).run(host='0.0.0.0',port=5000)
VannaFlaskApp启动更多参数

//参数具体含义
auth:要使用的身份验证方法。
debug:控制是否显示调试控制台。
allow_llm_to_see_data:指示是否允许LLM查看数据。
logo:用户界面中显示的标志。默认为Vanna标志。
title:设置要在UI中显示的标题。
subtitle:设置要在UI中显示的副标题。
show_training_data:控制是否在UI中显示训练数据。
sql:控制是否在UI中显示SQL输入。
table:控制是否在UI中显示表格输出。
csv_download:指示是否允许将表格输出作为CSV文件下载。
chart:控制是否在UI中显示图表输出。
ask_results_correct:指示是否询问用户结果是否正确。
summarization:控制是否显示摘要。
运行vanna_test.py脚本
(test)root@ubuntu:/data/scripts# python vanna_test.py
浏览器访问地址:http://127.0.0.1:5000

3、训练数据
3.1 命令行训练数据
1.添加表机构DDL
2.添加任意可以向量化的ducoment
3.添加 指定的sql 语句
读取列数据让训练
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
# If you like the plan, then uncomment this and run it to train
vn.train(plan=plan)
通过DDL告诉大模型每个字段确切的含义
# DDL statements are powerful because they specify table names, colume names, types, and potentially relationships
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS user (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL COMMENT '名字',
age INT NOT NULL COMMENT '年龄'
)ENGINE=InnoDB COMMENT='用户信息表';
""")
有时候需要告诉大模型约定一些定制化的需求
# Sometimes you may want to add documentation about your business terminology or definitions.
vn.train(documentation="请注意,在我们公司一般将1作为否,0作为是。")
有时间还需要指定指定的问题和对应的sql,纠正大模型给出的错误sql
# You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
vn.train(question="查查老吴的信息",sql="SELECT * FROM user WHERE name = '老吴'")
获取训练数据-----一般图形界面操作
# At any time you can inspect what training data the package is able to reference
training_data = vn.get_training_data()
training_data
删除训练数据----一般图形界面操作
# You can remove training data if there's obsolete/incorrect information.
vn.remove_training_data(id='1-ddl')
# Asking the AI
vn.ask(question=...)
3.2 图形界面添加训练数据

3.3 实验训练的表结构
需要注意的是表机构的备注要足够清晰,以便大模型能更好的理解表结构
1.服务器主机表(包括虚拟机)
CREATE TABLE `host` ( `ID` int(11) NOT NULL AUTO_INCREMENT,
`ApplicationID` varchar(128) DEFAULT NULL COMMENT '应用ID',
`AssetID` int(11) DEFAULT NULL COMMENT '资产ID',
`BakOperator` varchar(128) DEFAULT '' COMMENT '备份操作人',
`Cpu` int(3) NOT NULL DEFAULT '0' COMMENT 'CPU',
`CreateTime` datetime NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '创建日期',
`Description` varchar(256) DEFAULT '' COMMENT '备注',
`Env` varchar(20) DEFAULT NULL,
`DeviceClass` varchar(50) DEFAULT '一级',
`HostName` varchar(32) NOT NULL DEFAULT '' COMMENT '主机名',
`InnerIP` varchar(128) NOT NULL DEFAULT '' COMMENT '网内地址',
`LastTime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新日期',
`Mem` int(8) NOT NULL DEFAULT '0',
`OS_kernel` varchar(128) DEFAULT NULL,
`Operator` varchar(128) DEFAULT '' COMMENT '管理员',
`OS_type` varchar(128) NOT NULL DEFAULT '' COMMENT '系统类型',
`OuterIP` varchar(128) NOT NULL DEFAULT '' COMMENT '外网地址',
`Status` varchar(10) DEFAULT '1',
`Extend001` varchar(255) NOT NULL DEFAULT '',
`Disk_mount` varchar(255) DEFAULT NULL COMMENT '硬盘挂载信息',
`Disk` int(8) DEFAULT NULL COMMENT '硬盘信息',
`IdcName` varchar(128) DEFAULT '' COMMENT '机房名称',
PRIMARY KEY (`ID`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8 ROW_FORMAT = DYNAMIC COMMENT = '主机基础信息表';
2.服务器物理机表
CREATE TABLE `server` (
`ApplicationID` int(11) DEFAULT NULL COMMENT '应用ID',
`ID` int(64) NOT NULL AUTO_INCREMENT COMMENT '主键',
`HardMemo` varchar(16) NOT NULL DEFAULT '' COMMENT '服务器品牌型号',
`Cpu_model` varchar(128) DEFAULT '0' COMMENT 'CPU',
`Cpu_number` int(4) DEFAULT NULL COMMENT '物理cpu个数',
`HostName` varchar(32) NOT NULL DEFAULT '',
`DeviceClass` varchar(50) DEFAULT '一级',
`Region` varchar(8) DEFAULT '' COMMENT '区域-ucloud使用',
`OS_type` varchar(32) DEFAULT '' COMMENT '系统类型',
`OS_kernel` varchar(32) NOT NULL DEFAULT '' COMMENT '系统内核',
`SN` varchar(32) NOT NULL DEFAULT '' COMMENT 'SN编号',
`ServerRack` varchar(16) NOT NULL DEFAULT '' COMMENT '架机号',
`CreateTime` datetime NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '创建日期',
`IdcName` varchar(128) DEFAULT '' COMMENT '房机名称',
`LastTime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新日期',
`Operator` varchar(128) NOT NULL DEFAULT '' COMMENT '理管员',
`BakOperator` varchar(128) DEFAULT '' COMMENT '备份操作人',
`Status` varchar(10) DEFAULT '1',
`ManagerIP` varchar(128) NOT NULL DEFAULT '' COMMENT '管理地址',
`Raid` varchar(255) DEFAULT NULL COMMENT 'raid级别',
`Is_virtualization` varchar(10) DEFAULT '1',
`InnerIP` varchar(128) NOT NULL DEFAULT '' COMMENT '网内地址',
`OuterIP` varchar(128) DEFAULT '' COMMENT '外网地址',
`Description` varchar(256) NOT NULL DEFAULT '' COMMENT '备注',
`Extend001` varchar(255) DEFAULT NULL,
`Cpu_cores` int(4) DEFAULT NULL COMMENT 'cpu核数',
`Mem` int(18) DEFAULT '0',
`Disk_mount` varchar(2000) DEFAULT NULL COMMENT '硬盘分区',
`Disk_total` int(255) DEFAULT NULL COMMENT '硬盘',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=33 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='资产基础信息表';
3.训练表结构
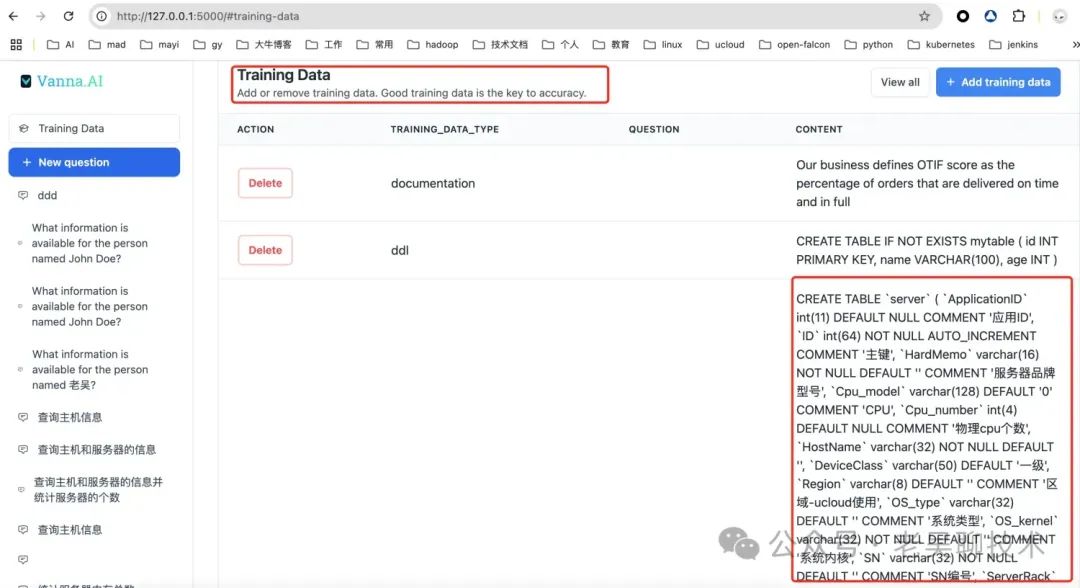
4.提问问题测试
统计服务器内存总数

统计虚拟机操作系统类型

如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 4451
4451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









