






背景
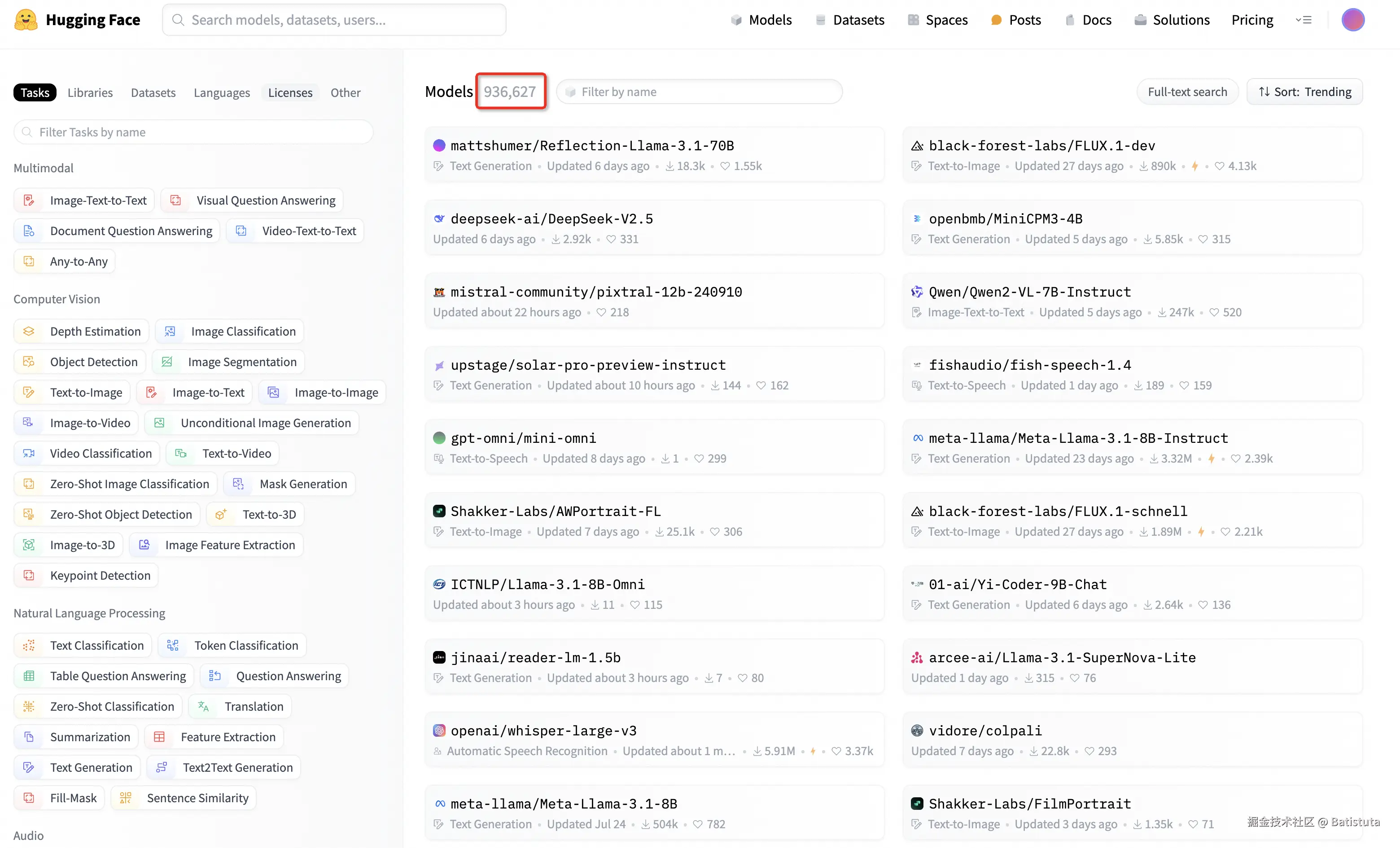
随着行业内越来越多的通用大模型进行开源,目前huggingface上的模型数量已达93w之多,相信过不了几天就会突破百万甚至千万,大家也是基于业内的开源大模型,针对某些特殊使用场景(如问题回答、编程、医学、法学等场景)进行微调,使得模型的输出更符合我们的预期。
微调大模型的好处:
- 提高准确性:微调可以显着提高大模型在特定任务上的准确性。例如,在对医学数据集进行微调后,大模型可能能够更准确地识相关医学术语与疾病表现。
- 提高效率:可以使大模型在特定任务.上更有效。例如,在对问答数据集进行微调后,大模型可能能够更快、更准确地回答问题。
- 提高泛化能力:可以提高大模型的泛化能力,这意味着它们可以更好地执行与训练数据中数据不同的任务。例如,在对不同类型的创意文本格式(如诗歌、代码、脚本、音乐作品、电子邮件、信件等)的数据集进行微调后,大模型可能能够生成我们用看件下微调大模型的优可以减少训练大模型所需的数据量。
- 数据安全:如果数据敏感,内部组织可能更愿意使用微调而不是公开模型,以保护数据隐私。
微调
微调是基于一个已经训练好的神经网络模型,通过对其参数进行细微调整,使其更好地适应特定的任务或数据。通过在新的小规模数据集上继续训练模型的部分或全部层,模型能够在保留原有知识的基础上,针对新任务进行优化,从而提升在特定领域的表现。 根据微调参数范围划分,微调范围分为两种:
- 全微调(Full Fine-tuning):就是对整个预训练模型来个全套改造,包括所有的模型参数。这种招式适合任务和预训练模型之间相差大的情况,或者任务要求模型超级灵活自适应的时候。虽然这招消耗资源多,时间也长,但效果杠杠的。
- 部分微调(Partial Fine-Tuning):这个招式就是只调整模型的上层或者少数几层,底层参数不动。这招适合任务和预训练模型比较相似,或者数据集不大的情况。因为只动少数层,所以资源消耗少,速度快,不过有时候效果可能差点。
目前我们绝大部分场景都使用的是部分微调,种方法减少了计算和存储成本,同时降低了过拟合的风险,适合数据较少的任务,但在任务复杂度较高时可能无法充分发挥模型的潜力。
根据微调使用的数据集类型,大模型微调还可以分为:
- 监督微调(Supervised Fine-tuning):就是用有标签的训练数据集进行微调。这些标签告诉模型在微调中应该怎么做。比如分类任务,每个样本都有对应的标签。用这些标签指导模型微调,可以让它更适应具体任务。
- 无监督微调(Unsupervised Fine-tuning):这个就是用无标签的训练数据集进行微调。也就是模型只能看数据,不知道啥是对啥是错。这种方法通过学习数据内在结构或者生成数据,来提取有用特征或者改善模型表示能力。 本文后续微调采用的是SFT的方式进行微调,微调的理论我就不做过多篇幅介绍,有兴趣的同学可以自行搜索资料,本文重点是希望通过实操的方式,让大家对大模型的微调有亲身操作的体感,从而激发大家对于模型微调的研究兴趣。
流程
- 准备数据集:找到和任务相关的数据,保证数据质量和标签准确,然后做好清洗和预处理。
- 选模型:根据任务和数据,选一个合适的微调的基座模型。
- 微调策略参数:根据任务需求和资源,选择合适的微调策略,配置LoRA参数、微调参数如学习率,确保模型收敛。
- 训练模型:在训练集上训练模型,,按照设定的超参数和优化算法,调整参数降低损失,防止过拟合。
- 评估模型:在验证集上评估模型性能。
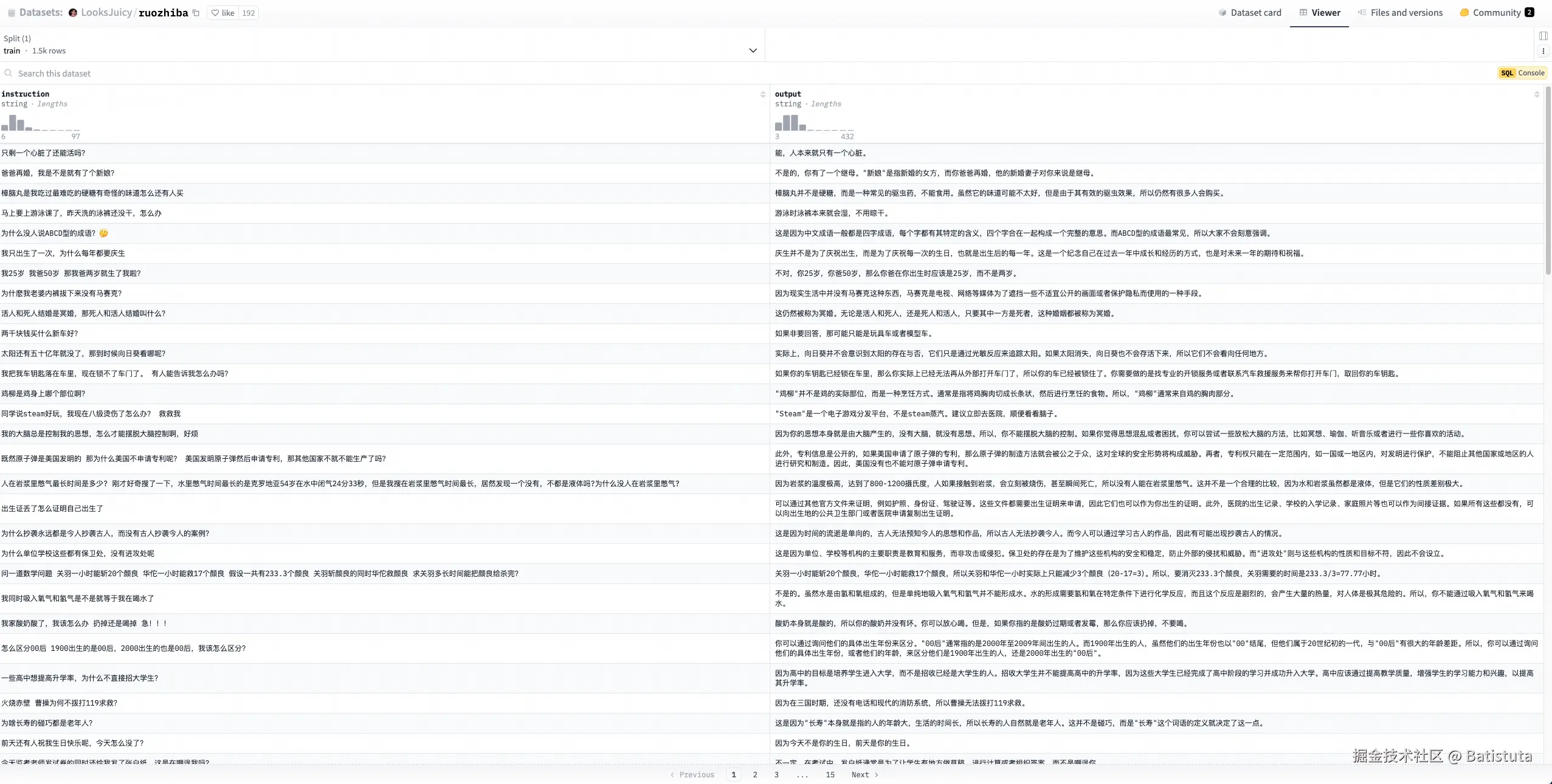
数据集-弱智吧
由于当前大模型的预训练集已经较为完善,普通的训练集的微调效果可能很难让大家看出通用大模型与微调后模型的效果区别,所以本文的数据集采用了大名鼎鼎的“弱智吧”训练集。在huggingface搜索ruozhiba关键字,选择适合自己的弱智吧数据集即可。
基座模型还是采用了较为新的llama3.1-8b,首先还是看一下未训练前的大模型针对这类问题的回答效果,是不是乍一看还是挺对的😄。

训练框架-unsloth
由于苹果提供的MLX本地训练框架并未非常成熟,本文采用的unsloth框架来进行大模型的微调,unsloth对常见的模型都提供了相应的微调python代码示例,对新人是非常友好的的,微调代码也均可以通过colab提供的免费T4 GPU快速完成。
训练平台-colab

使用步骤如下:
-
首先准备账户登录colab
-
登录成功后,先访问colab页面,通过左上角文件菜单

-
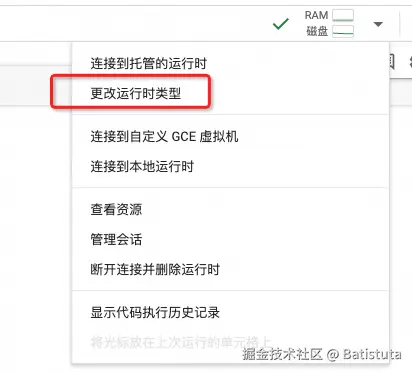
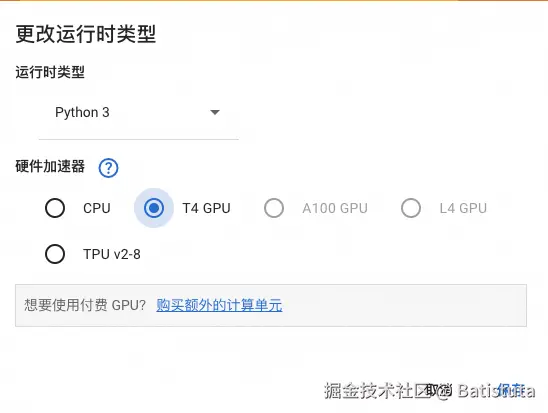
点击右上角的更改运行时类型,选择T4 GPU,点击保存后,就可以开始进行微调代码的编辑了
微调代码解读
1、安装unsloth训练框架以及相关的依赖训练框架
%%capture
# Installs Unsloth, Xformers (Flash Attention) and all other packages!
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
# We have to check which Torch version for Xformers (2.3 -> 0.0.27)
from torch import __version__; from packaging.version import Version as V
xformers = "xformers==0.0.27" if V(__version__) < V("2.4.0") else "xformers"
!pip install --no-deps {xformers} trl peft accelerate bitsandbytes triton
2、加载unsloth/Meta-Llama-3.1-8B模型,并通过load_in_4bit参数的调整以节省内存使用
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit", # Llama-3.1 15 trillion tokens model 2x faster!
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"unsloth/Meta-Llama-3.1-405B-bnb-4bit", # We also uploaded 4bit for 405b!
"unsloth/Mistral-Nemo-Base-2407-bnb-4bit", # New Mistral 12b 2x faster!
"unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"unsloth/mistral-7b-v0.3-bnb-4bit", # Mistral v3 2x faster!
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/Phi-3.5-mini-instruct", # Phi-3.5 2x faster!
"unsloth/Phi-3-medium-4k-instruct",
"unsloth/gemma-2-9b-bnb-4bit",
"unsloth/gemma-2-27b-bnb-4bit", # Gemma 2x faster!
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
点击运行后在线下载相应模型
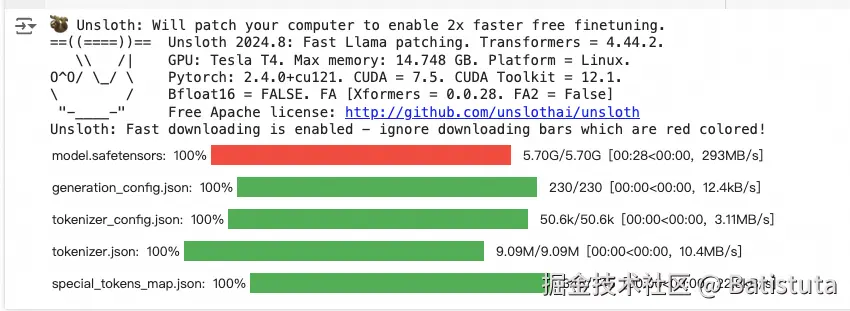
3、对目标模型进行参数扩展技术的配置,增强FastLanguageModel模型的功能,优化内存使用,提示出来长文本序列能力
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)

4、加载LooksJuicy/ruozhiba数据集,定义数据集的map函数formatting_prompts_func来格式化每个样本的指令、输出等
alpaca_prompt = """Below is an instruction that describes a question, paired with an output that answer the question.
### Instruction:
{}
### output:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
outputs = examples["output"]
texts = []
for instruction, output in zip(instructions, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("LooksJuicy/ruozhiba", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)

5、设置训练环境,通过SFTTrainer、TrainingArguments来配置微调过程中的数据集、优化器、学习率调度器,并针对处理器类型进行优化
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)

6、打印训练环境的GPU显存情况
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")

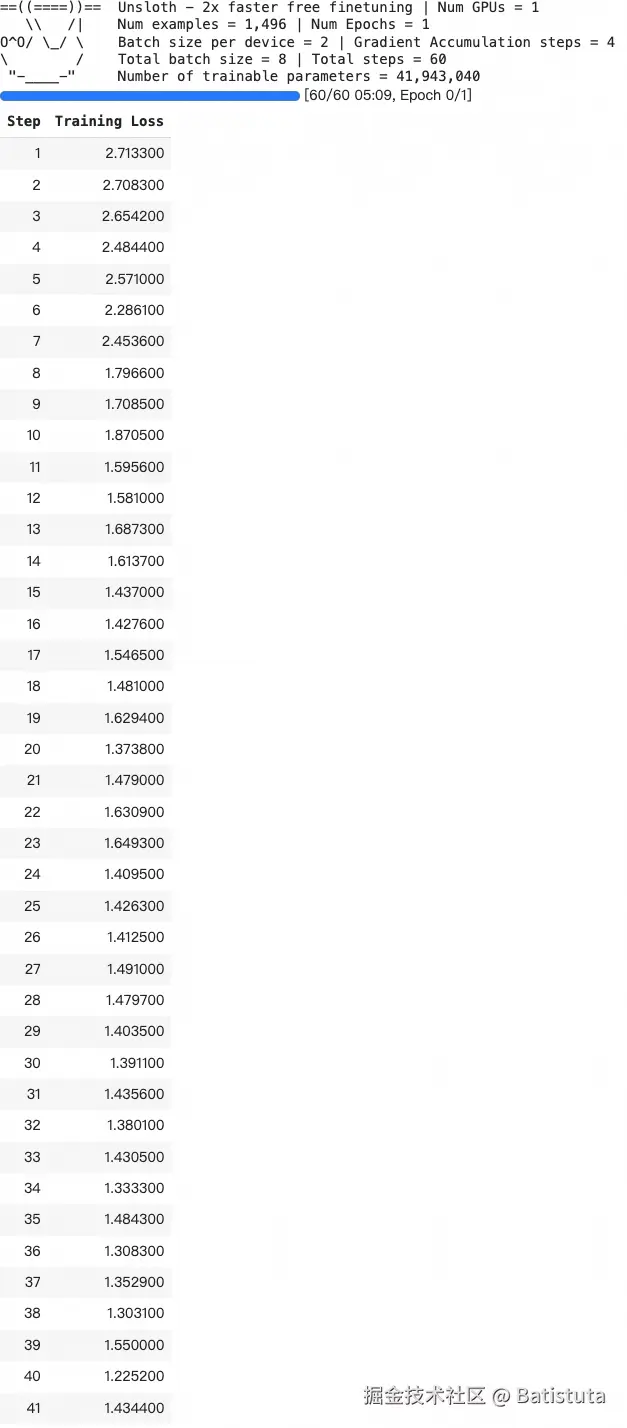
7、开始训练
最终loss值不是特别理想,但后续测试感觉也还行,就没修改max_steps、num_train_epochs等参数调整再训练了
trainer_stats = trainer.train()
8、使用微调后的模型进行推理
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"赤壁之战曹操为什么不拨打火警电话灭火?", # instruction
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 2048, use_cache = True)
tokenizer.batch_decode(outputs)

9、保存微调后的模型 仅保存LoRA的是适配层,此次选择本地保存,保存的文件是存放在colab的云端,也可以推送到自己账号下面的huggingface仓库
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
# model.push_to_hub("your_name/lora_model", token = "...") # Online saving
# tokenizer.push_to_hub("your_name/lora_model", token = "...") # Online saving

10、加载微调后的模型进行推理测试
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "lora_model", # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
# alpaca_prompt = You MUST copy from above!
inputs = tokenizer(
[
alpaca_prompt.format(
"赤壁之战曹操为什么不拨打火警电话灭火?", # instruction
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 2048)

11、保存微调模型为GGUF格式并推送至huggingface 此处保存的是q4_k_m方法的量化版本
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
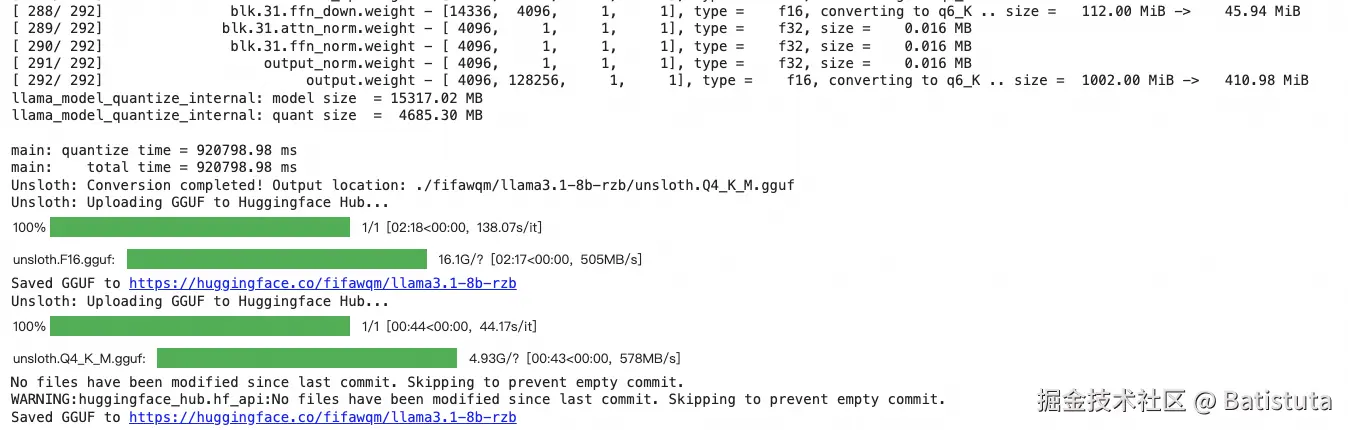
signature%3D86rog5hjFeTxlGHRCegnEbjVA70%253D&pos_id=img-5c8upIol-1741663112167) 后续可以将相应的微调模型文件下载至本地,通过ollama、LM-Studio等工具进行导入使用 具体的一些微调参数说明可以访问github.com/unslothai/u…
写到最后
大家在开发一款AI应用时,模型微调并不应该是最先要考虑的事情,目前细分的垂类模型生态已经非常丰富,微调也仅仅能解决对特定任务下大模型的泛化推理能力,而针对需要解决问题的信息实时性、准确性也是通过RAG等方案来解决,有时候对提示词的优化也能起到比较好的效果,所以建议大家在AI应用开发流程上,切勿上来就开始进行模型微调,微调的数据集比例选择(通用/专业)、微调参数选择的不准确,都可能使得基准的大模型失去通用的泛化能力,起到意想不到的反效果。
本文属于AI新人动手科普篇,希望大家通过自己动手来了解模型微调的全过程,了解目前模型微调的一些本质与原理。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 9360
9360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









