







自学强化学习,主要是看了网上大佬们写的一些文章,都是零零碎碎的强化学习的算法,所以这篇文章主要是总结我学的知识,可能知识点不是很全,后期慢慢补充吧,如果有理解错误也烦请指出。
概述
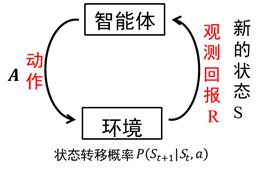
如上图,强化学习就是智能体和环境交互的过程,是一个
马
尔
科
夫
决
策
过
程
\color{red}{马尔科夫决策过程}
马尔科夫决策过程(当前状态仅与上个状态和所做的动作有关,即
P
(
S
t
+
1
∣
S
t
,
a
)
P(S_{t+1}|S_t,a)
P(St+1∣St,a)),在强化学习的模型中,我们最终的目的是找到一个最优的策略来最大化累计的回报R。
贝
尔
曼
方
程
:
\color{red}{贝尔曼方程:}
贝尔曼方程:这是强化学习的基础,我这边直接贴图。

下面这张图说明了贝尔曼方程和蒙特卡洛(MC)、时间差分法(TD)和动态规划(DP)的关系:
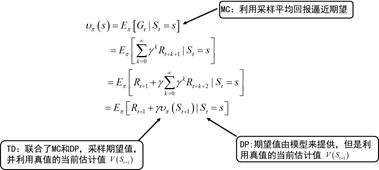
算法分类
模型
- 基 于 模 型 的 算 法 \color{red}{基于模型的算法} 基于模型的算法:假设智能体已经知道环境,包括条件转移概率,reward情况等,一般使用 动 态 规 划 \color{red}{动态规划} 动态规划方法来迭代出所有的可能,再作决策;
- 无 模 型 的 算 法 \color{red}{无模型的算法} 无模型的算法:智能体不了解环境,所以采用随机策略,通过一次次地与环境交互来获取试验采样数据,最后处理这些数据来更新策略。处理数据的方法主要是两种方法: 蒙 特 卡 洛 ( M C ) \color{red}{蒙特卡洛(MC)} 蒙特卡洛(MC)和 时 间 差 分 法 ( T D ) \color{red}{时间差分法(TD)} 时间差分法(TD),其中,之后算法用的最后的主要是TD算法。这两种方法的理论上的区别上图应该已经很明显了,在实际实现的时候TD算法是 单 步 更 新 \color{red}{单步更新} 单步更新的,而MC算法则是 回 合 更 新 \color{red}{回合更新} 回合更新的,简单的说:训练中,智能体和环境交互的时候,TD是边交互边更新它的策略,而MC则是每和环境交互完一轮更新一次。
策略和值
- 基 于 值 的 算 法 \color{red}{基于值的算法} 基于值的算法:上面提到的MC、TD和DP算法都是基于值得算法,我们可以看到每次通过采样数据更新的都是 v π ( s ) \mathcal{v}_\pi(s) vπ(s)或者 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a),其实最终得到的最优策略就是根据我们每个回合更新的 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)表,Q表也可以被称为值函数
- 基 于 策 略 的 算 法 \color{red}{基于策略的算法} 基于策略的算法:算法不是基于贝尔曼方程了,具体公式推导参照李宏毅教授的ppt(提取码:fe5l),里面写得很清楚,b站上也有教学视频。
off-policy和on-policy
- o f f − p o l i c y \color{red}{off-policy} off−policy:更新策略和自己的行动不一致,典型的又Qlearning,Qlearning更新的时候是拿 Q 值 最 大 \color{red}{Q值最大} Q值最大的下个状态来更新当前状态的Q值的,当前状态则采取随机策略来选取动作。
- o n − p o l i c y \color{red}{on-policy} on−policy:on-policy则是和off-policy相反的,典型的算法有sarsa算法。
强化学习&深度学习
强化学习算法运行的时候,程序都需要维护一张Q表,你的状态也多,可执行的动作越多,维护的表就越大,这会占去过多的内存,显然不合适。甚至有时状态是连续的,那维护Q表变得无法实现,这时我们希望有个函数,当我们输入状态行动的时候能够返回Q值,这就是Q表(值函数)的 逼 近 函 数 \color{red}{逼近函数} 逼近函数,逼近函数可以分为 参 数 逼 近 \color{red}{参数逼近} 参数逼近和 非 参 数 逼 近 \color{red}{非参数逼近} 非参数逼近,而参数逼近又可以分为 线 性 参 数 \color{red}{线性参数} 线性参数和 非 线 性 参 数 \color{red}{非线性参数} 非线性参数,其中非线性参数逼近就可以选我们熟悉的神经网络。这就是强化学习和深度学习的结合。
逼近函数选择神经网络,则需要更新神经网络,更新的方法其实就是一个监督学习的过程,数据标签:(s,R)其中s为状态,R为回报(在MC中则是 G t G_t Gt,在TD中则是 R t + 1 + γ Q π ( s t + 1 , a ) R_{t+1}+\gamma Q_\pi(s_{t+1},a) Rt+1+γQπ(st+1,a))。















 7749
7749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









