







强化学习的算法分类有多种方式:
- 免模型学习(Model-Free) vs 有模型学习(Model-Based)
-
Value-based vs Policy-based,Actor-Critic
- 蒙特卡罗方法和时间差分方法
-
On-policy vs Off-policy

目录
Value-based vs Policy-based,Actor-Critic
1、无模型学习(Model-Free) vs 基于模型学习(Model-Based)
1、无模型学习(Model-Free) vs 基于模型学习(Model-Based)
我们首先讨论基于模型的方法和无模型的方法,如图3.2所示。什么是“模型”?在深度学习 中,模型是指具有初始参数(预训练模型)或已习得参数(训练完毕的模型)的特定函数,例如 全连接网络、卷积网络等。而在强化学习算法中,“模型”特指环境,即环境的动力学模型。回 想一下,在马尔可夫决策过程(MDP)中,有五个关键元素:S,A,P,R,γ。S和A表示环境的 状态空间和动作空间;P 表示状态转移函数,p(s′|s,a)给出了智能体在状态s下执行动作a,并 转移到状态s′的概率;R代表奖励函数,r(s,a)给出了智能体在状态s执行动作a时环境返回的 奖励值;γ表示奖励的折扣因子,用来给不同时刻的奖励赋予权重。如果所有这些环境相关的元 素都是已知的,那么模型就是已知的。此时可以在环境模型上进行计算,而无须再与真实环境进 行交互,例如值迭代、策略迭代等规划(Planning)方法。在通常情况下,智能 体并不知道环境的奖励函数R和状态转移函数p(s′|s,a),所以需要通过和环境交互,不断试错 (Trials and Errors),观察环境相关信息并利用反馈的奖励信号来不断学习。这个不断学习的过程 既对基于模型的方法适用,也对无模型的方法适用。

在这个不断试错和学习的过程中,可能有某些环境元素是未知的,如奖励函数R和状态转移 函数P。此时,如果智能体尝试通过在环境中不断执行动作获取样本(s,a,s′,r)来构建对R和P 的估计,则p(s′|s,a) 和r 的值可以通过监督学习进行拟合。习得奖励函数R和状态转移函数P之后,所有的环境元素都已知,则前文所述的规划方法可以直接用来求解该问题。这种方式即称 为基于模型的方法。
另一种称为无模型的方法则不尝试对环境建模,而是直接寻找最优策略。例 如,Q-learning 算法对状态-动作对(s,a) 的Q值进行估计,通常选择最大Q值对应的动作执行, 并利用环境反馈更新Q值函数,随着Q值收敛,策略随之逐渐收敛达到最优;策略梯度(Policy Gradient)算法不对值函数进行估计,而是将策略参数化,直接在策略空间中搜索最优策略,最 大化累积奖励。这两种算法都不关注环境模型,而是直接搜索能最大化奖励的策略。这种不需要对环境建模的方式称为无模型的方法。可以看到,基于模型和无模型的区别在于,智能体是否利 用环境模型(或称为环境的动力学模型),例如状态转移函数和奖励函数。
通过上述介绍可知,基于模型的方法可以分为两类:一类是给定(环境)模型(Giventhe Model)的方法,另一类是学习(环境)模型(LearntheModel)的方法。对于给定模型的方法, 智能体可以直接利用环境模型的奖励函数和状态转移函数。例如,在AlphaGo算法(Silveretal., 2016) 中,围棋规则固定且容易用计算机语言进行描述,因此智能体可以直接利用已知的状态转 移函数和奖励函数进行策略的评估和提升。而对于另一类学习模型的方法,由于环境的复杂性或 不可知性,我们很难描述整个动力系统的规律。此时智能体无法直接获取模型,可行的替代方式 是先通过与环境交互学习环境模型,然后将模型应用到策略评估和提升的过程中。 第二类的典型例子包括WorldModels算法(Haetal.,2018)、I2A 算法 (Racanière et al., 2017) 等。例如在WorldModels 算法中,智能体首先使用随机策略与环境交互收集数据(St,At,St+1), 再使用变分自编码器(VariationalAutoencoder,VAE)(Baldi, 2012) 将状态编码为低维潜向量zt。 然后利用数据(Zt,At,Zt+1) 学习潜向量z 的预测模型。有了预测模型之后,智能体便可以通过 习得的预测模型提升策略能力。 基于模型的方法的主要优点是,通过环境模型可以预测未来的状态和奖励,从而帮助智能体 进行更好的规划。一些典型的方法包括朴素规划方法、专家迭代(Suttonetal.,2018)方法等。例 如,MBMF算法(Nagabandietal.,2018)采用了朴素规划的算法;AlphaGo算法(Silveretal.,2016) 采用了专家迭代的算法。基于模型的方法的缺点在于,存在或构建模型的假设过强。现实问题中 环境的动力学模型可能很复杂,甚至无法显式地表示出来,导致模型通常无法获取。另一方面, 在实际应用中,学习得到的模型往往是不准确的,这给智能体训练引入了估计误差,基于带误差 模型的策略的评估和提升往往会造成策略在真实环境中失效。
相较之下,无模型的方法不需要构建环境模型。智能体直接与环境交互,并基于探索得到的 样本提升其策略性能。与基于模型的方法相比,无模型的方法由于不关心环境模型,无须学习环 境模型,也就不存在环境拟合不准确的问题,相对更易于实现和训练。然而,无模型的方法也有 其自身的问题。最常见的问题是,有时在真实环境中进行探索的代价是极高的,如巨大的时间消 耗、不可逆的设备损耗及安全风险,等等。比如在自动驾驶中,我们不能在没有任何防护措施的 情况下,让智能体用无模型的方法在现实世界中探索,因为任何交通事故的代价都将是难以承 受的。
2 、基于价值的方法和基于策略的方法
深度强化学习中的策略优化主要有:基于价值的方法和基于策略的方法,两者的结合产生了Actor-Critic 类算法和QT-Opt(Kalashnikov et al., 2018) 等其他算法,它们利用价值函数的估计来帮助更新策略。其分类关系如图所示。基于价值的方法通常意味着对动作 价值函数Qπ(s,a)的优化。优化后的最优值函数表示为Qπ∗(s,a)=maxaQπ(s,a),最优策略通 过选取最大值函数对应的动作得到π∗≈argmaxπQπ(“≈”由函数近似误差导致)。
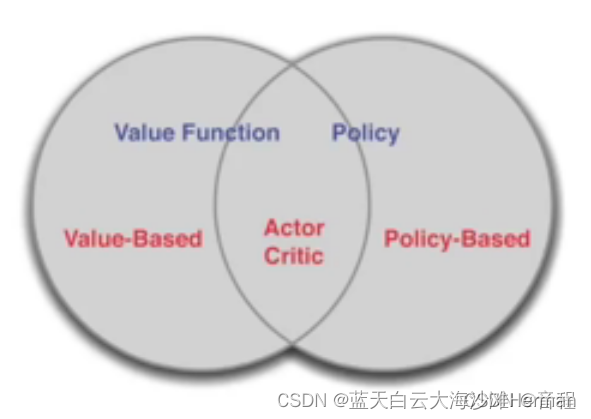
基于价值的方法的优点在于采样效率相对较高,值函数估计方差小,不易陷入局部最优;缺 点是它通常不能处理连续动作空间问题,且最终的策略通常为确定性策略而不是概率分布的形 式。此外,深度Q网络等算法中的ϵ-贪心策略(ϵ-greedy)和max算子容易导致过估计的问题。
常见的基于价值的算法包括Q-learning(Watkinsetal.,1992)、深度Q网络(DeepQ-Network, DQN)(Mnihetal.,2015)及其变体: (1)优先经验回放(PrioritizedExperienceReplay,PER)(Schaul et al., 2015) 基于 TD 误差对数据进行加权采样,以提高学习效率;(2)DuelingDQN(Wangetal., 2016) 改进了网络结构,将动作价值函数Q分解为状态值函数V 和优势函数A以提高函数近似 能力;(3)DoubleDQN(VanHasselt et al., 2016) 使用不同的网络参数对动作进行选择和评估,以解决过估计的问题;(4)Retrace (Munos et al., 2016) 修正了 Q 值的计算方法,减少了估计的方 差;(5)NoisyDQN(Fortunato et al., 2017) 给网络参数添加噪声,增加了智能体的探索能力;(6) Distributed DQN (Bellemare et al., 2017) 将状态-动作值估计细化为对状态-动作值分布的估计。
基于策略的方法直接对策略进行优化,通过对策略迭代更新,实现累积奖励最大化。与基于 价值的方法相比,基于策略的方法具有策略参数化简单、收敛速度快的优点,且适用于连续或高 维的动作空间。一些常见的基于策略的算法包括策略梯度算法(PolicyGradient,PG)(Suttonetal., 2000)、信赖域策略优化算法(TrustRegionPolicyOptimization,TRPO)(Schulmanetal.,2015)、近 端策略优化算法(ProximalPolicyOptimization,PPO)(Heesset al., 2017; Schulman et al., 2017) 等, 信赖域策略优化算法和近端策略优化算法在策略梯度算法的基础上限制了更新步长,以防止策略 崩溃(Collapse),使算法更加稳定。
除了基于价值的方法和基于策略的方法,更流行的是两者的结合,这衍生出了Actor-Critic方 法。Actor-Critic 方法结合了两种方法的优点,利用基于价值的方法学习Q值函数或状态价值函数 V 来提高采样效率(Critic),并利用基于策略的方法学习策略函数(Actor),从而适用于连续或 高维的动作空间。Actor-Critic方法可以看作是基于价值的方法在连续动作空间中的扩展,也可以 看作是基于策略的方法在减少样本方差和提升采样效率方面的改进。虽然Actor-Critic方法吸收 了上述两种方法的优点,但同时也继承了相应的缺点。比如,Critic存在过估计的问题,Actor存 在探索不足的问题等。
一些常见的Actor-Critic类的算法包括Actor-Critic(AC)算法(Suttonetal., 2018) 和一系列改进:(1)异步优势Actor-Critic算法(A3C)(Mnihetal.,2016)将Actor-Critic 方 法扩展到异步并行学习,打乱数据之间的相关性,提高了样本收集速度和训练效率;(2)深度确 定性策略梯度算法(DeepDeterministicPolicyGradient,DDPG)(Lillicrap et al., 2015) 沿用了深度 Q网络算法的目标网络,同时Actor是一个确定性策略;(3)孪生延迟DDPG算法(TwinDelayed Deep Deterministic Policy Gradient,TD3)(Fujimoto et al., 2018) 引入了截断的(Clipped)Double Q-Learning 解决过估计问题,同时延迟Actor更新频率以优先提高Critic拟合准确度;(4)柔性 Actor-Critic 算法(Soft Actor-Critic,SAC)(Haarnoja et al., 2018) 在 Q 值函数估计中引入熵正则 化,以提高智能体探索能力。
3、蒙特卡罗方法和时间差分方法
蒙特卡罗(MonteCarlo,MC)方法和时间差分(TemporalDifference,TD)方法。时间差分方法是动态规划(DynamicProgramming,DP)方法和蒙特卡罗方法的一种中间形式。
首 先,时间差分方法和动态规划方法都使用自举法(Bootstrapping)进行估计,其次,时间差分方法 和蒙特卡罗方法都不需要获取环境模型。这两种方法最大的不同之处在于如何进行参数更新,蒙 特卡罗方法必须等到一条轨迹生成(真实值)后才能更新,而时间差分方法在每一步动作执行都 可以通过自举法(估计值)及时更新。这种差异将使时间差分方法方法具有更大的偏差,而使蒙特卡罗方法方法具有更大的方差。

4、在线策略方法和离线策略方法
在线策略(On-Policy)方法和离线策略(Off-Policy)方法依据策略学习的方式对强化学习算 法进行划分(图3.5)。在线策略方法试图评估并提升和环境交互生成数据的策略,而离线策略方 法评估和提升的策略与生成数据的策略是不同的。这表明在线策略方法要求智能体与环境交互的 策略和要提升的策略必须是相同的。而离线策略方法不需要遵循这个约束,它可以利用其他智能 体与环境交互得到的数据来提升自己的策略。常见的在线策略方法是Sarsa,它根据当前策略选 择一个动作并执行,然后使用环境反馈的数据更新当前策略。因此,Sarsa与环境交互的策略和 更新的策略是同一个策略。它的Q函数更新公式如下:

Q-learning 是一种典型的离线策略方法。它在选择动作时采用max操作和ϵ-贪心策略,使得 与环境交互的策略和更新的策略不是同一个策略。它的Q函数更新公式如下:

参考书籍:ch3.pdf (deepreinforcementlearningbook.org)
Chap 3. Taxonomy of Reinforcement Learning - Deep Reinforcement Learning Book
















 8774
8774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









