







题目来源
题目描述

class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
}
};
题目解析
回溯 VS 深度优先遍历
- 回溯法:采用试错的思想,它尝试分布的去解决一个问题。在分布解决问题的过程中,当它通过尝试发现现有的分布答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。回溯法通常用最简单的递归方法来实现,在反复重复上述的步骤后可能出现两种情况:
- 找到了一个可能存在的正确答案
- 在尝试了所有可能的分布方法后宣告该问题没有答案。
- DFS是一种用于遍历树或者图的算法。这种算法会尽可能深的搜索树的分支。当节点
v所在的边已经被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这个过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的结点,则选择其中一个作为源结点并重复以上过程,整个进程反复进行直到所有结点都被访问为止。
「回溯算法」与「深度优先遍历」都有「不撞南墙不回头」的意思。
- 「回溯算法」强调了「深度优先遍历」思想的用途,用一个 不断变化的变量,在尝试各种可能的过程中,搜索需要的结果。强调了回退操作对于搜索的合理性。
- 而「深度优先遍历」强调一种遍历的思想,与之对应的遍历思想是「广度优先遍历」。
搜索与遍历
我们每天使用的搜索引擎帮助我们在庞大的互联网上搜索信息。搜索引擎的「搜索」和「回溯搜索」算法里「搜索」的意思是一样的。
搜索问题的解,可以通过 遍历 实现。所以很多教程把「回溯算法」称为爆搜(暴力解法)。因此回溯算法用于搜索一个问题的所有的解 ,通过深度优先遍历的思想实现。
与动态规划的区别
共同点:用于求解多阶段决策问题。多阶段决策问题即:
- 求解一个问题分为很多步骤(阶段)
- 每一个步骤可以有很多选择
不同点:
- 动态规划只需要我们评估最优解是多少,最优解对应的具体解是什么并不要求。因此很适合用于评估一个方案的效果
- 回溯算法可以搜索得到的所有的方案(当然包括最优解),但是它本质上它是一种遍历算法,时间复杂度很高
从全排列问题开始理解回溯算法
我们尝试在纸上写 3 个数字、4 个数字、5 个数字的全排列,相信不难找到这样的方法。以数组 [ 1 , 2 , 3 ] [1, 2, 3] [1,2,3] 的全排列为例。
- 先写以 1 开头的全排列,它们是: [ 1 , 2 , 3 ] , [ 1 , 3 , 2 ] [1, 2, 3], [1, 3, 2] [1,2,3],[1,3,2],即 1 + [ 2 , 3 ] 1 + [2, 3] 1+[2,3]的全排列(注意:递归结构体现在这里);
- 再写以 2 开头的全排列,它们是: [ 2 , 1 , 3 ] , [ 2 , 3 , 1 ] [2, 1, 3], [2, 3, 1] [2,1,3],[2,3,1],即 2 + [ 1 , 3 ] 2 + [1, 3] 2+[1,3]的全排列;
- 最后写以 3 开头的全排列,它们是: [ 3 , 1 , 2 ] , [ 3 , 2 , 1 ] [3, 1, 2], [3, 2, 1] [3,1,2],[3,2,1],即 3 + [ 1 , 2 ] 3 + [1, 2] 3+[1,2]的全排列。
总结搜索的方法:按照顺序枚举每一位可能出现的情况,已选择的数字在当前要选择的数字中不能出现。按照这种搜索就能做到不重不漏。这样的思路,可以用一个树形结构表示。
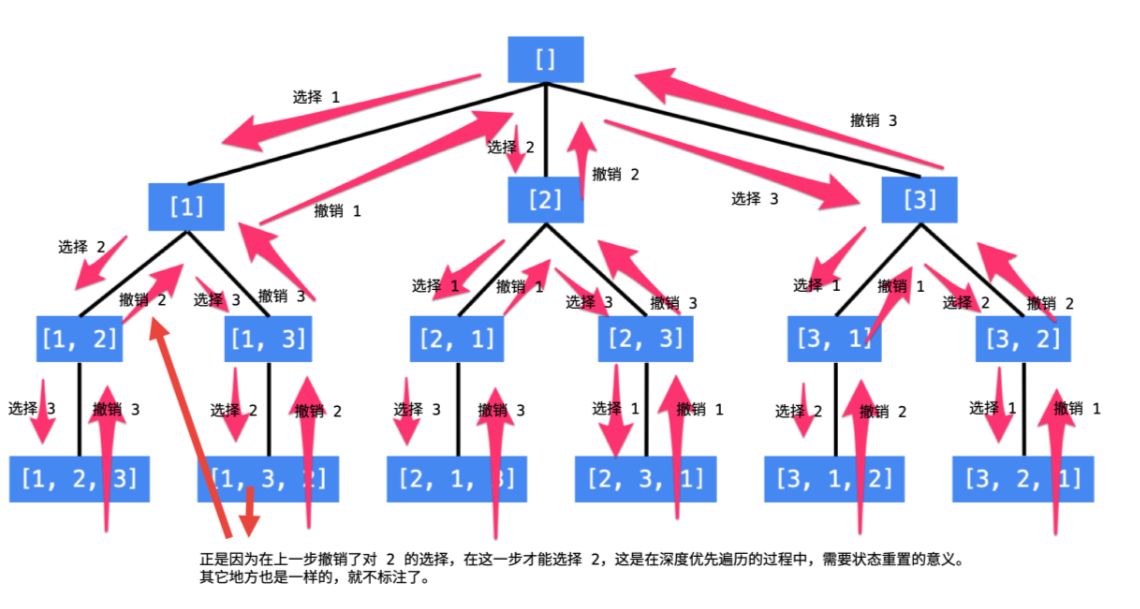
说明:
- 每一个节点表示了求解全排列问题的不同的阶段,这些阶段通过变量的[不同的值]体现,这些变量的不同的值,称之为[状态]
- 使用深度优先遍历有[回头]的过程,在[回头]之后,状态变量需要设置成之前的一样,因此在回到上一节点的过程中,需要撤销上一次的选择,这个操作称之为[状态重置]
- 深度优先遍历,借助系统栈空间,保存所需要的状态变量,在编码中只需要注意遍历到相应的结点的时候,状态变量的值是正确的,具体的做法是:往下走一层的时候,path 变量在尾部追加,而往回走的时候,需要撤销上一次的选择,也是在尾部操作,因此 path 变量是一个栈;
- 深度优先遍历通过「回溯」操作,实现了全局使用一份状态变量的效果。
- 使用编程的方法得到全排列,就是在这样的一个树形结构中完成 遍历,从树的根结点到叶子结点形成的路径就是其中一个全排列。
设计状态变量
- 首先这棵树除了根节点和叶子节点之外,每一个节点做的事情其实是一样的,即:在已经选择了一些数的前提下,在剩下的还没有选择的数中,依次选择一个数,这显然是一个递归结构
- 递归的终止条件是:一个排列中的数字已经选够了,因此我们需要一个变量来表说当前程序递归到了第几层,我们把这个变量叫做 depth,或者命名为 index ,表示当前要确定的是某个全排列中下标为 index 的那个数是多少;
- 布尔数组 used,初始化的时候都为 false 表示这些数还没有被选择,当我们选定一个数的时候,就将这个数组的相应位置设置为 true ,这样在考虑下一个位置的时候,就能够以 O(1)O(1) 的时间复杂度判断这个数是否被选择过,这是一种「以空间换时间」的思想。
这些变量称为「状态变量」,它们表示了在求解一个问题的时候所处的阶段。需要根据问题的场景设计合适的状态变量。
代码实现
class Solution {
// 全排列,每个元素只用一次,每个**有效结果**都包含全部元素,不同顺序代表不同答案
void dfs(vector<int>& nums, int len, int depth, vector<int>& path,
vector<int>& used, std::vector<std::vector<int>>&res){
// 什么时候结束搜索:当前结果的长度==列表的长度,,就说明我结束一次搜索,并且是一个有效的结果
if(depth == len){
res.push_back(path);
return;
}
//回溯范围: 因为每个有效结果都包含全部元素, 所以需要全部遍历,因为每一层都要考虑全部元素
for (int i = 0; i < len; ++i) {
// 剪枝条件:
// 1.每一个元素值用一次--->当某个元素用过了,那下一层就不会再使用了
if(used[i]){
continue;
}
path.push_back(nums[i]); // 既然是遍历,那么一次都能拿到一个元素,每一层的新元素都应该和上一层的累计结果相结合
used[i] = true; // 在backtrack之前,需要把当前元素的check值改为1,标记为使用过
dfs(nums, len, depth + 1, path, used, res);
// 注意:下面这两行代码发生 「回溯」,回溯发生在从 深层结点 回到 浅层结点 的过程,代码在形式上和递归之前是对称的
used[i] = false; // 等到backtrack结束后,需要把check的值改回为0,这样不影响其他搜索对于这个元素的判断
path.pop_back();
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
int len = nums.size();
std::vector<std::vector<int>> res;
if(len == 0){
return res;
}
std::vector<int> used(len);
std::vector<int> path;
dfs(nums, len, 0, path, used, res);
return res;
}
};
func permute(nums []int) (ans [][]int) {
n := len(nums)
path := make([]int, n)
onPath := make([]bool, n)
var dfs func(int)
dfs = func(i int) {
if i == n {
ans = append(ans, append([]int(nil), path...))
return
}
for j, on := range onPath {
if !on {
path[i] = nums[j]
onPath[j] = true
dfs(i + 1)
onPath[j] = false
}
}
}
dfs(0)
return
}
看个例子: [1, 2, 3]
- 第一层:也就是全排列解的第一个值
这个值可以从(1,2,3)中选择:
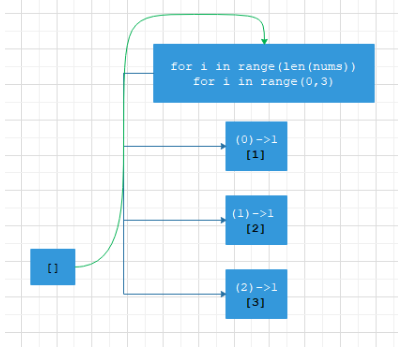
此时有三种情况,我们继续看第一种情况,即当i选择第0个元素也就是1的时候,此时sol=[1],check=[1,0,0]:
继续搜索,因为还没有到有效结果的结束条件,下一层,仍然有三种情况,(1,2,3),但是此时check中显示1这个元素被用过了,于是实际值选择的是(2,3):

继续回溯搜寻,因为还没有到结束条件:
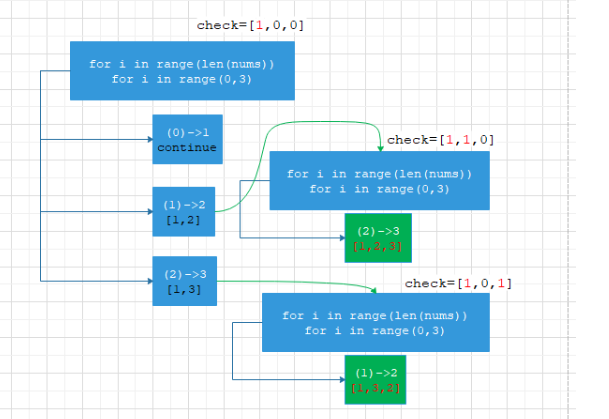
总结:回溯类题一定要考虑的几个方面
- 有效结果:当长度为输入长度的时候停止,并保存当前结果
- 回溯条件:每一层都是全部元素遍历:例如答案为[2,1,3]时,第二个元素也是从1开始
- 剪枝条件:要用check数组来保存用过的元素,用过的不能再用了,这是回溯里面的一个重要考虑因素
为什么回溯不是广度优先遍历
- 首先是正确性,只有遍历状态空间,才能得到所有符合条件的解,这一点 BFS 和 DFS 其实都可以;
- 在深度优先遍历的时候,不同状态之间的切换很容易 ,可以再看一下上面有很多箭头的那张图,每两个状态之间的差别只有 11 处,因此回退非常方便,这样全局才能使用一份状态变量完成搜索;
- 如果使用广度优先遍历,从浅层转到深层,状态的变化就很大,此时我们不得不在每一个状态都新建变量去保存它,从性能来说是不划算的;
- 如果使用广度优先遍历就得使用队列,然后编写结点类。队列中需要存储每一步的状态信息,需要存储的数据很大,真正能用到的很少 。
- 使用深度优先遍历,直接使用了系统栈,系统栈帮助我们保存了每一个结点的状态信息。我们不用编写结点类,不必手动编写栈完成深度优先遍历。
排列 VS 组合
我们先画出其回溯树来看看
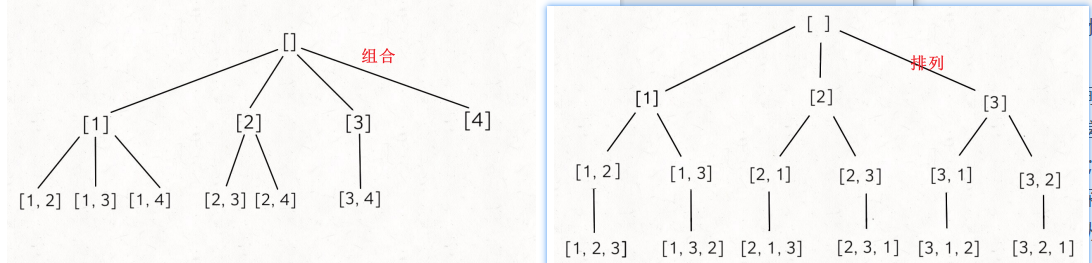
可以看出,排列问题的树⽐较对称,⽽组合问题的树越靠右节点越少。
体现在代码中:排列问题每次通过used来排除在dfs中已经选择过的数字;而组合问题通过每次传入一个start参数,来排除start索引之前的数字
类似题目
| 题目 | 思路 |
|---|---|
| leetcode:77. 给定集合[1…n],从中挑选k(指定)个数,返回所有组合(每个数可以用一次) combination | 组合是顺序无关的,如 [1,2] 和 [2,1] 是同一个组合不同排列。组合时需要一个idx来排除已经选过的数:对于每个数,有两种选择,要,不要;当path.size()==k时时表示找到了一种组合 |
| leetcode:216. 给定集合[1…9],从中挑选k(指定)个数,令其和为target,返回所有组合(每个数可以用一次) combination-sum-iii | 比77题多了一个限制,和为target。组合时需要一个idx来排除已经选过的数:对于每个数,有两种选择,要,不要;当path.size() == k && currSum == targetSum时表示找到了一种组合 |
| leetcode:17. 给定一个数字到字母集的映射表,和一个数字组成的字符串,返回所有可能的组合 Letter Combinations of a Phone Number | 组合是顺序无关的,如 [1,2] 和 [2,1] 是同一个组合不同排列。组合时需要一个idx来排除已经选过的数:从str[0]中选一个数(枚举所有可能的选择),从str[1]中选择一个数… …当idx==str.size()时,表示找到了一种组合 |
| leetcode:401. 二进制手表所有可能的表示时间 Binary Watch | 时针集合取k个,分针集合取num-k个,然后将所有符合要求的生成时间表示存入结果中即可 |
| leetcode:22. 给定n,生成所有合法的括号组合 generate-parentheses | 因为要所有组合,所以应该回溯。从左到右尝试,对于当前位置,可以放(还是) |
| leetcode:39. 无序(不重复)数组中选出一些数,令其和=target,返回所有可能的组合(每个数可以使用无限次) Combination Sum | 因为不知道要选几个数,所以不可以指针或者迭代;因为需要返回方案而不是方案个数,所以用回溯。对于每个数,有两种选择:不要、要(1、2…次);当restT == 0时就说明找到了一条路径;当restT < 0或者idx == N时递归返回 |
| leetcode:40. 无序(可重复)数组中选出一些数,令其和=target,返回所有可能的组合(每个数可以使用一次) Combination Sum II | 和39题目一样,唯一的区别是需要去重。怎么去重了,在要了之后,要先跳过所有和nums[curr]相同的数字,再看要还是不要 |
| leetcode:377. 无序(不重复)数组中选出一些数,令其和=target,返回所有可能的组合个数(每个数可以使用无限次) Combination Sum IV | 对于每一个rest,在搜索开始之前,如果rest=0,说明找到了一种;否则每次均从nums[0....]开始使用每一个nums去拼接rest,如果rest > nums[idx],那么就使用它;否则什么也不干 |
| leetcode:254. 整数可以由因子相乘得来,给出一个整数,返回所有可能的因子组合 | 由于题目中说明了1和n本身不能算其因子,那么可以从2开始遍历到n,如果当前的数i可以被n整除,说明i是n的一个因子,将其存入一位数组 out 中,然后递归调用 n/i,此时不从2开始遍历,而是从i遍历到 n/i;停止的条件是当n等于1时,如果此时 out 中有因子,将这个组合存入结果 res 中 (start排除已经选过的数,初始时start为2,最多为sqrt(n)) |
| leetcode:78. 无序(不重复)数组所有的不重复子集 | 对于每一个元素,都有选择和不选择两种选择,一直到没有元素可选了,才收集可能的答案 |
| leetcode:90. 无序(可重复)数组所有的不重复子集 Subsets II | 怎么去重呢?重复的原因是:刚刚选择了,然后撤销了这个选择,之后又选择了和刚刚相同的元素;所以先排序,然后去重(为什么要排序,将重复的元素放在一起,便于剪枝) |
| leetcode:46. 无序(不重复)数组所有的全排列 Permutations | 数要全部用光(每个答案长度是固定的),所以对于第一位可以选择num[0…x],对于第二位可以选择除了第一位的所有选择…直到所有数全部用完 |
| leetcode:47. 无序(可重复)数组所有的全排列(不重复) Permutations | 怎么去重呢?对于两个相同的元素,可以两个都选,两个都不选,只选择一个(那么选哪一个都可以,因为和选择另一个是相同的情况,所以只有这种情况我们需要剪枝)。所以应该先排序,然后去重。去重条件是:和前一个元素值相同,并且前一个元素已经被使用过 |
| leetcode:320.列举单词的全部缩写 Generalized Abbreviation | 对于每一个字符,可以用1代替或者取原来的。如果发现有多个1就变为加起来的数 |
| leetcode:784. 给定一个字符串,可以将字母变大写或者小写,能够得到的全排列 letter-case-permutation | 对于每一个字母,有变大写、边小写两种选择 。到了idx == str.size(),说明已经得到了一个答案 |
| leetcode:1755. 最接近目标值的子序列和 | 将数组一分为二,分别枚举出左半边和右半边的子集和。那么原数组的一个子序列和,一定是下面三者之一:lsum中的某个元素、rsum中的某个元素,lsum和rsum中的某个元素之和。对于第三种情况,相当于:给定两个数组,如何在两个数组中各选出一个整数,令它们的和尽可能的接近目标值。可以用双指针来做 |
| leetcode:113. 二叉树找到路径(从根到叶),令其和=target,返回所有可能的组合 | 先判断当前节点是否满足,然后去左右子树找,找完之后,返回上一个结点时,需要把该结点从path 中移除 |

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









