






 本文介绍了如何使用XTuner在8GB显存环境下低成本地对大型语言模型进行微调,涉及FlashAttention技术以优化内存使用,以及DeepSpeedZeRO优化策略。文章详细说明了配置过程、训练方法、模型转换和部署测试步骤,还提及了AttentionisAllYouNeed论文的相关内容。
本文介绍了如何使用XTuner在8GB显存环境下低成本地对大型语言模型进行微调,涉及FlashAttention技术以优化内存使用,以及DeepSpeedZeRO优化策略。文章详细说明了配置过程、训练方法、模型转换和部署测试步骤,还提及了AttentionisAllYouNeed论文的相关内容。
XTuner 大模型单卡低成本微调实战
视频链接:https://www.bilibili.com/video/BV1yK4y1B75J/?vd_source=bebd279bbc043ae1c13d45838597180f
文档地址:https://github.com/InternLM/tutorial/tree/main/xtuner
XTuner Repo: https://github.com/InternLM/xtuner/tree/main
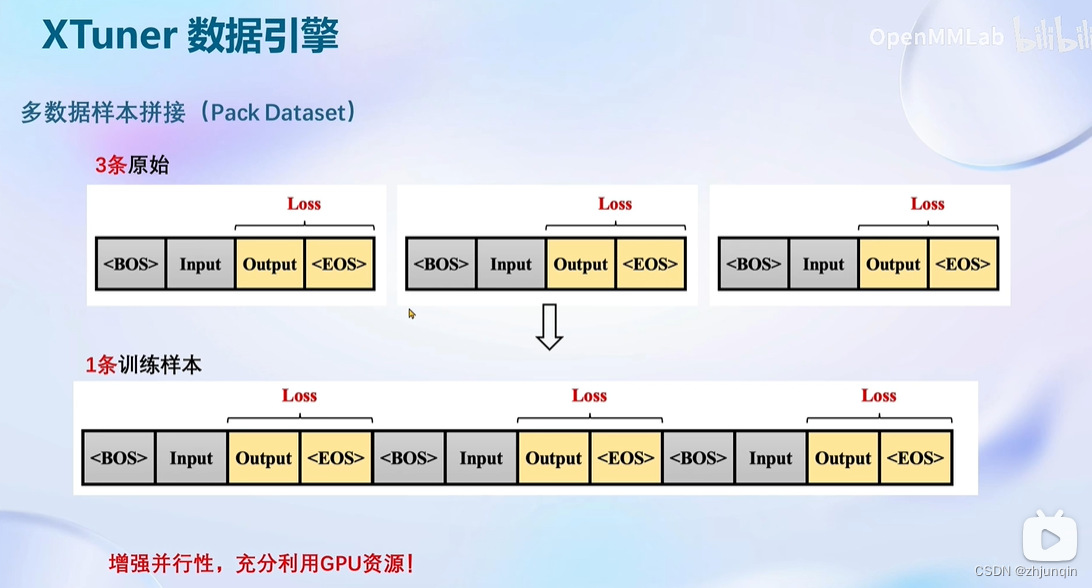
Finetune 简介




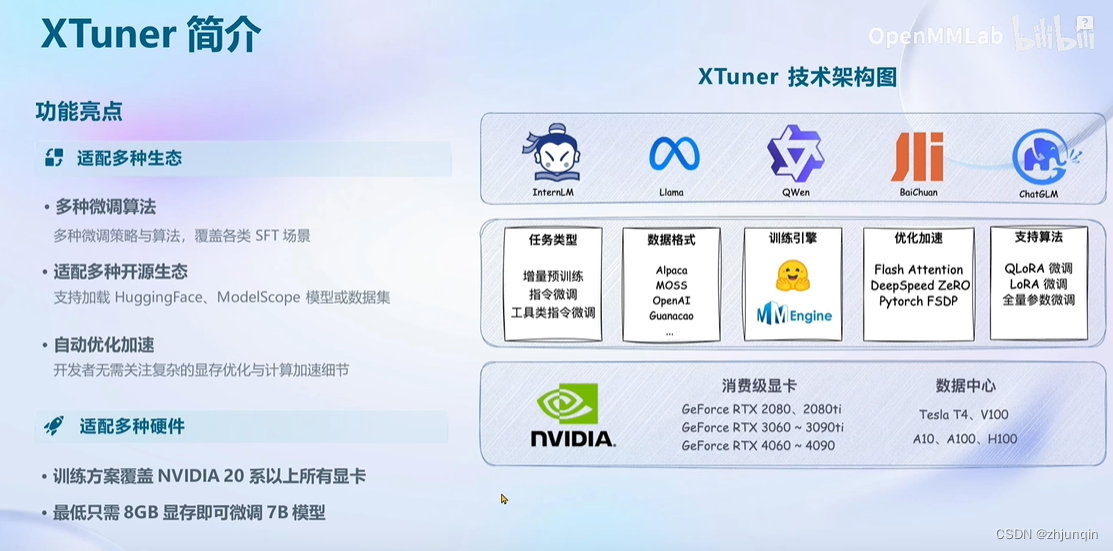
XTuner




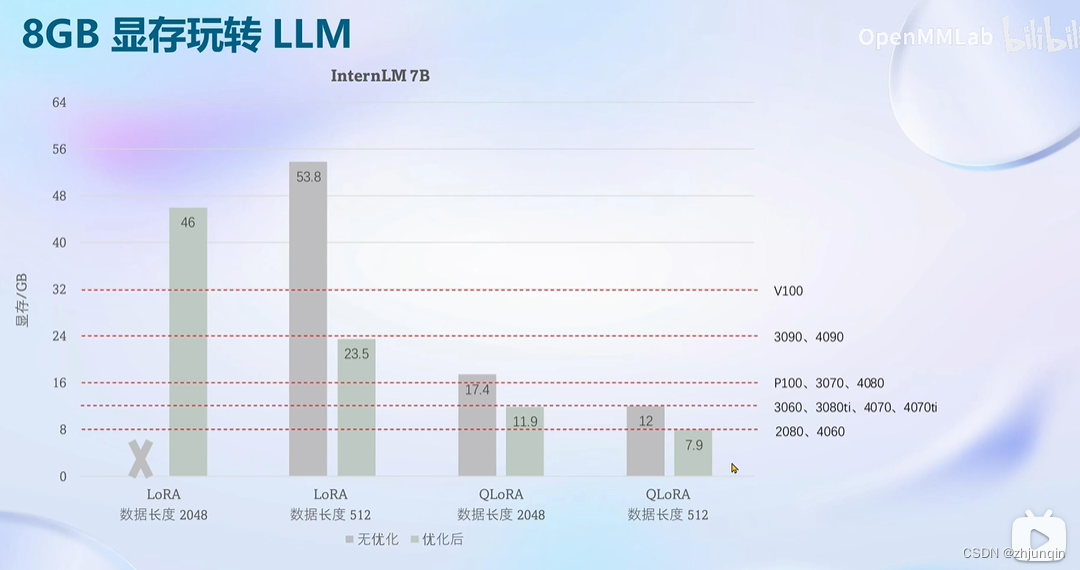
8GB 显存玩转 LLM

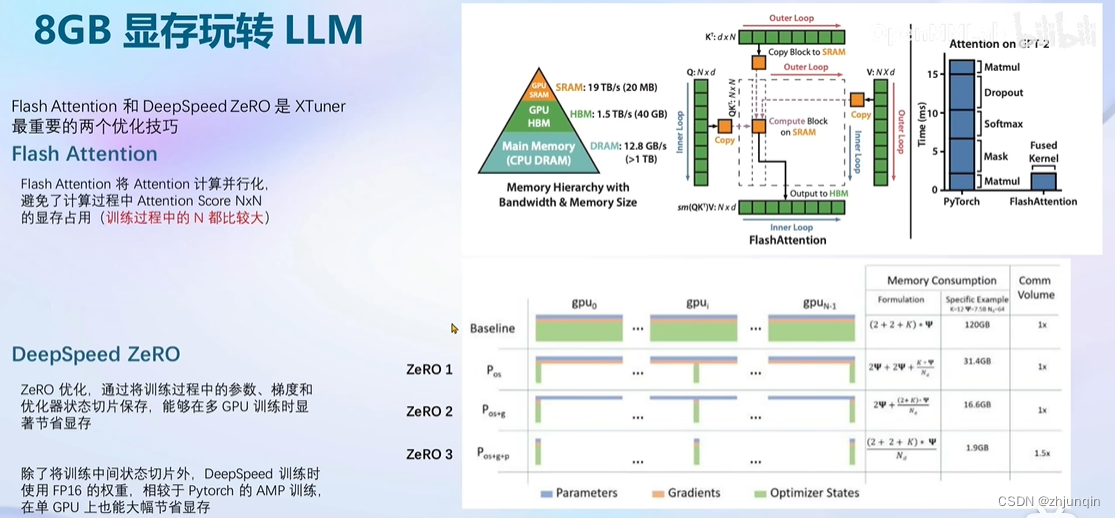
FlashAttention 旨在避免从 HBM(High Bandwidth Memory)中读取和写入注意力矩阵,这需要做到:
目标一:在不访问整个输入的情况下计算 softmax 函数的缩减;
目标二:在后向传播中不能存储中间注意力矩阵。
DeepSpeed ZeRO有三个主要的优化阶段(如下图所示),它们对应于优化器状态、梯度和参数的划分。
1.Optimizer State Partitioning(Pos):将优化器状态切分到不同的 GPU
2.添加梯度分区(Pos+g):将梯度切分到不同的 GPU
3.添加参数分区(Pos+g+p):将模型参数切分到不同的 GPU
整体基本步骤
- 准备数据
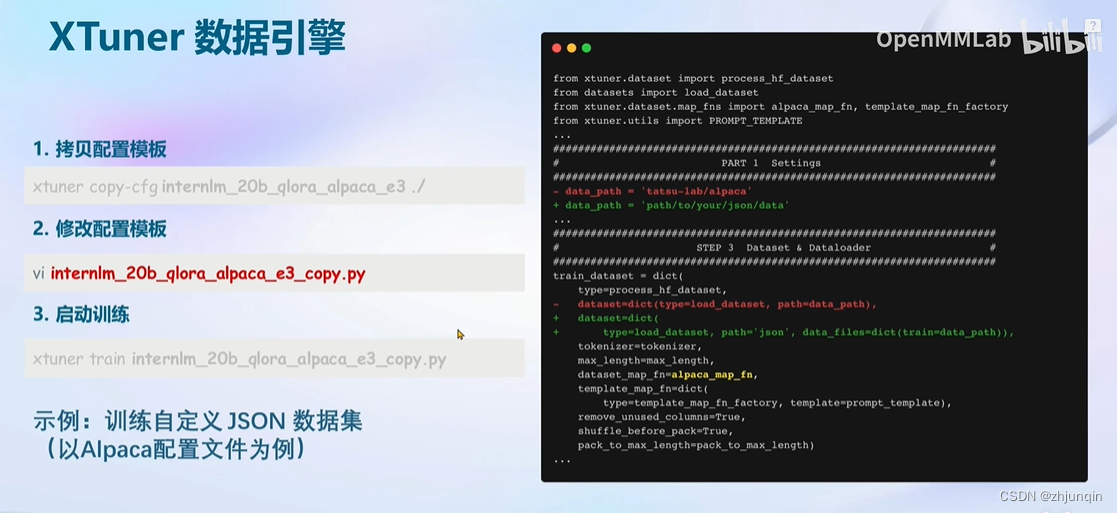
下载所需数据集,比如 https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main - 修改配置文件
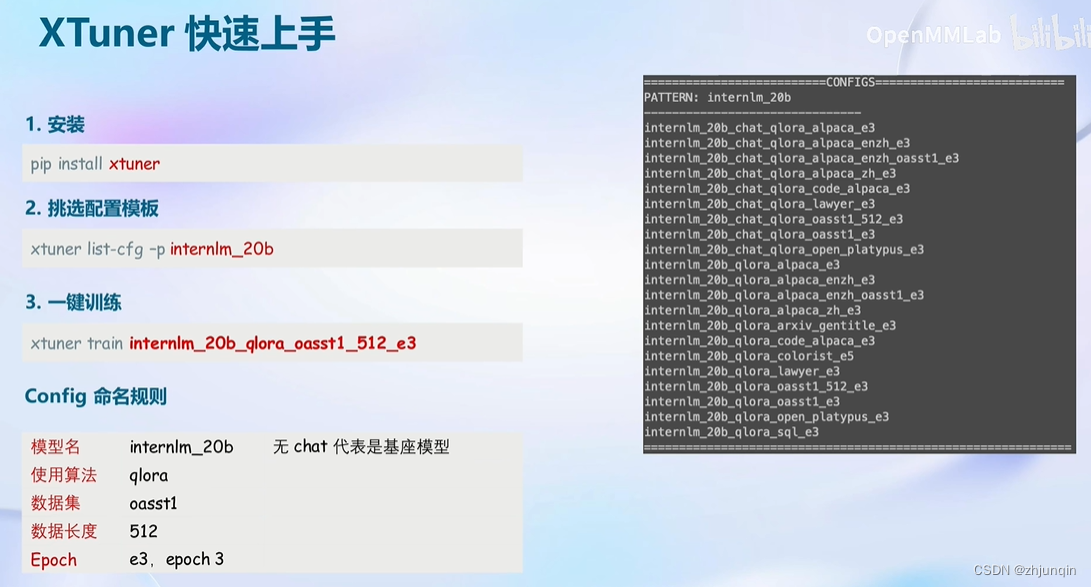
使用xtuner list-cfg查看支持的模型配置
# xtuner list-cfg
[2024-01-14 10:44:08,415] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-01-14 10:44:20,046] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect)
==========================CONFIGS===========================
省略...
internlm_20b_qlora_alpaca_e3
internlm_20b_qlora_alpaca_enzh_e3
internlm_20b_qlora_alpaca_enzh_oasst1_e3
internlm_20b_qlora_alpaca_zh_e3
internlm_20b_qlora_arxiv_gentitle_e3
internlm_20b_qlora_code_alpaca_e3
internlm_20b_qlora_colorist_e5
internlm_20b_qlora_lawyer_e3
internlm_20b_qlora_msagent_react_e3_gpu8
省略...
=============================================================
拷贝修改配置文件
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
- 训练微调
使用命令训练
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
- 模型转换
训练完成后,转换训练完成 pth 到 hugging face 格式的模型
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
- 部署与测试
将 HuggingFace adapter 合并到大语言模型:
xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH} --max-shard-size 2GB
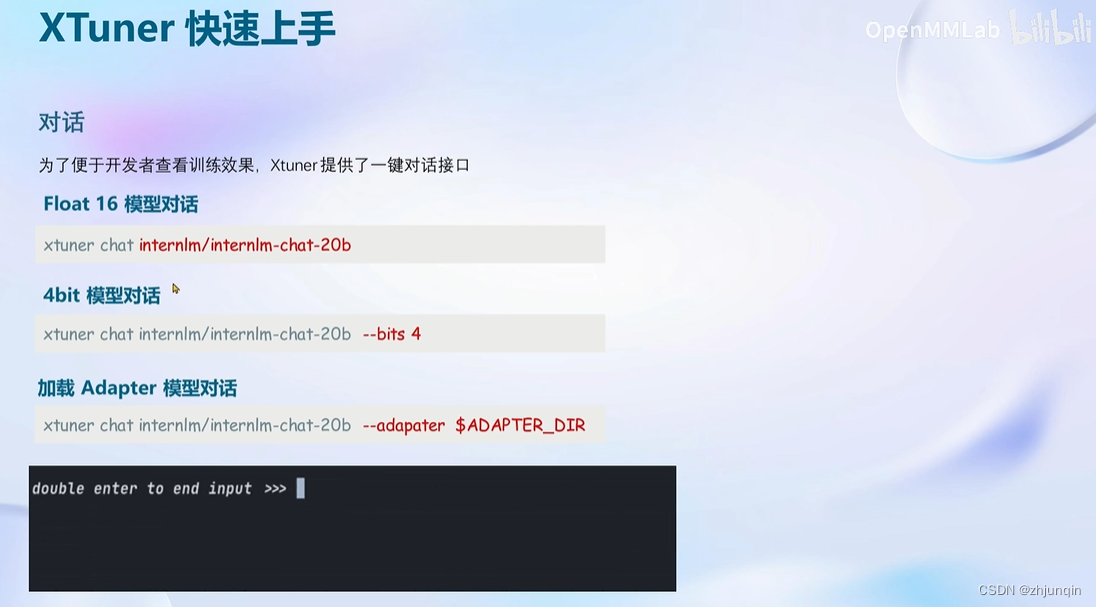
与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
不合并模型直接对话,增加 --adapter 参数来指定 Lora 的参数
xtuner chat $LLM --adapter $ADAPTER --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
MSAgent-Bench
ModelScope-Agent是一个通用且可定制的代理框架,用于实际应用,基于开源LLMs作为种树。它提供了一个用户友好的系统库,具有可定制的引擎设计,支持在多个开源LLMs上进行模型训练,同时还以一种统一的方式实现了与模型API和常见API的无缝集成。 https://modelscope.cn/datasets/damo/MSAgent-Bench/summary
下载已经训练好的参数
cd ~/ft-msagent
apt install git git-lfs
git lfs install
git lfs clone https://www.modelscope.cn/xtuner/internlm-7b-qlora-msagent-react.git
执行
到 serper.dev 注册后获得一个 api key
export SERPER_API_KEY=abcdefg
xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent
执行日志
# xtuner chat ./internlm-chat-7b/ --adapter ./internlm-7b-qlora-msagent-react/ --lagent
[2024-01-13 23:37:23,481] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Error: mkl-service + Intel(R) MKL: MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library.
Try to import numpy first or set the threading layer accordingly. Set MKL_SERVICE_FORCE_INTEL to force it.
[2024-01-13 23:37:27,892] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:09<00:00, 1.24s/it]
Loading adapter from ./internlm-7b-qlora-msagent-react/...
double enter to end input (EXIT: exit chat, RESET: reset history)请介绍 attention is all you need 论文
根据我的搜索结果,“attention is all you need”论文提出了一种基于注意力机制的简单网络架构,可以替代传统的递归和卷积神经网络,并在多个任务上取得了最新的翻译结果。此外,这篇论文还介绍了一些实验结果和应用场景。如果您对这个主题感兴趣,我可以为您提供更多相关信息。
在 serper.dev 上可以查询到日志

参考文献
https://zhuanlan.zhihu.com/p/618533434
https://zhuanlan.zhihu.com/p/624412809















 2172
2172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









