






书生·浦语大模型实战营
视频:https://www.bilibili.com/video/BV1Rc411b7ns/
文档:https://github.com/InternLM/tutorial/blob/main/helloworld/hello_world.md
InternLM 介绍
InternLM 是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个 GPU 的大型集群上进行预训练,并在单个 GPU 上进行微调,同时实现了卓越的性能优化。在 1024 个 GPU 上训练时,InternLM 可以实现近 90% 的加速效率。
基于 InternLM 训练框架,上海人工智能实验室已经发布了两个开源的预训练模型:InternLM-7B 和 InternLM-20B
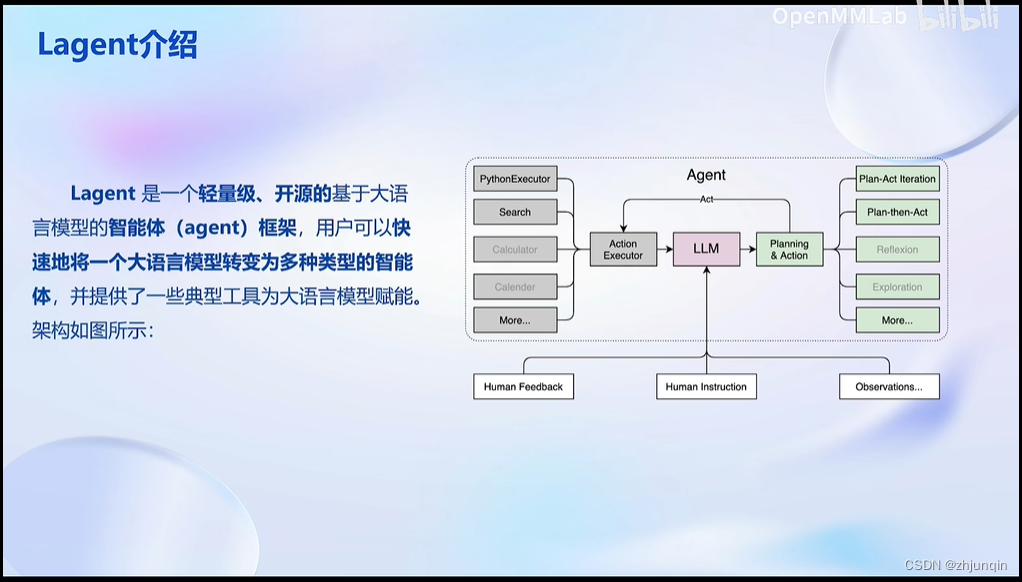
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。通过 Lagent 框架可以更好的发挥 InternLM 的全部性能。


InternLM-techreport
InternLM: A Multilingual Language Model with
Progressively Enhanced Capabilities
训练数据集

为了确保大型语言模型预训练的稳健和准确基础,开发了一个复杂的流程,其中包含多种数据清理和过滤技术。该流程包括几个独立的阶段:语言分类,基于规则的过滤,基于模型的过滤,去重处理。
训练系统
为了支持 InternLM 的训练,构建了一个名为 Uniscale-LLM 的训练系统,该系统专门设计和优化用于基于 Transformer 模型的训练。该系统集成了一系列并行训练技术,例如数据并行、张量并行、流水线并行和零冗余优化(ZeRO)。它还包含一个大规模的检查点子系统,可以每隔一小时或数小时异步地写入大型模型的检查点,并且有一个故障恢复子系统,可以快速从最后一个检查点恢复因硬件/网络故障或丢失峰值而中断的训练过程。
模型设计
采用了类似于 GPT 系列的基于 Transformer 的仅解码器架构。
多阶段渐进预训练
在训练过程中,将整个过程分为多个阶段,每个阶段都通过控制数据的不同比例来定义其优化目标。选择适当的数据集来评估达到这些目标的进展情况。如果某个阶段的性能不符合预期,我们可以从该阶段结束的地方恢复训练,而无需重新开始,从而提高训练效率。
对齐
预训练的语言模型进一步进行微调,遵循类似于 InstructGPT 的流程,以更好地遵循指令并与人类偏好保持一致。该过程包括以下三个阶段:Supervised fine-tuning (SFT), Reward model training, Reinforcement Learning from Human Feedbacks (RLHF)。
模型结构
下面是 InternLM-Chat-7B 的结构和参数。
InternLMForCausalLM(
(model): InternLMModel(
(embed_tokens): Embedding(103168, 4096, padding_idx=2)
(layers): ModuleList(
(0-31): 32 x InternLMDecoderLayer(
(self_attn): InternLMAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=True)
(k_proj): Linear(in_features=4096, out_features=4096, bias=True)
(v_proj): Linear(in_features=4096, out_features=4096, bias=True)
(o_proj): Linear(in_features=4096, out_features=4096, bias=True)
(rotary_emb): InternLMRotaryEmbedding()
)
(mlp): InternLMMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): InternLMRMSNorm()
(post_attention_layernorm): InternLMRMSNorm()
)
)
(norm): InternLMRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=103168, bias=False)
)
总参数量:
103168 * 4096 + 32 * (4096 * 4096 * 4 + 4096 * 11008 * 3) + 4096 * 103168 = 7,321,157,632
配置文件
{
"architectures": [
"InternLMForCausalLM"
],
"auto_map": {
"AutoConfig": "configuration_internlm.InternLMConfig",
"AutoModel": "modeling_internlm.InternLMForCausalLM",
"AutoModelForCausalLM": "modeling_internlm.InternLMForCausalLM"
},
"bias": true,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 2048,
"model_type": "internlm",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"pad_token_id": 2,
"rms_norm_eps": 1e-06,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.33.2",
"use_cache": true,
"vocab_size": 103168
}
Demo
操作过程不详细记录,贴几张 Demo 的截图。
InternLM-Chat

Lagent

internlm-xcomposer
















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









