






 本文介绍了如何利用InternLM和LangChain技术搭建自己的知识库,包括大模型开发范式、LangChain简介、文本分块与向量化、NLTK在句子分割中的应用,以及如何创建和加载模型进行问答。通过实例代码展示了关键步骤和解决常见问题的方法。
本文介绍了如何利用InternLM和LangChain技术搭建自己的知识库,包括大模型开发范式、LangChain简介、文本分块与向量化、NLTK在句子分割中的应用,以及如何创建和加载模型进行问答。通过实例代码展示了关键步骤和解决常见问题的方法。
基于 InternLM 和 LangChain 搭建你的知识库
视频链接:https://www.bilibili.com/video/BV1sT4y1p71V/
文档:https://github.com/InternLM/tutorial/tree/main/langchain
视频课程
本次课介绍如何基于 InternLM 和 LangChain 搭建你的知识库。

1. 大模型开发范式


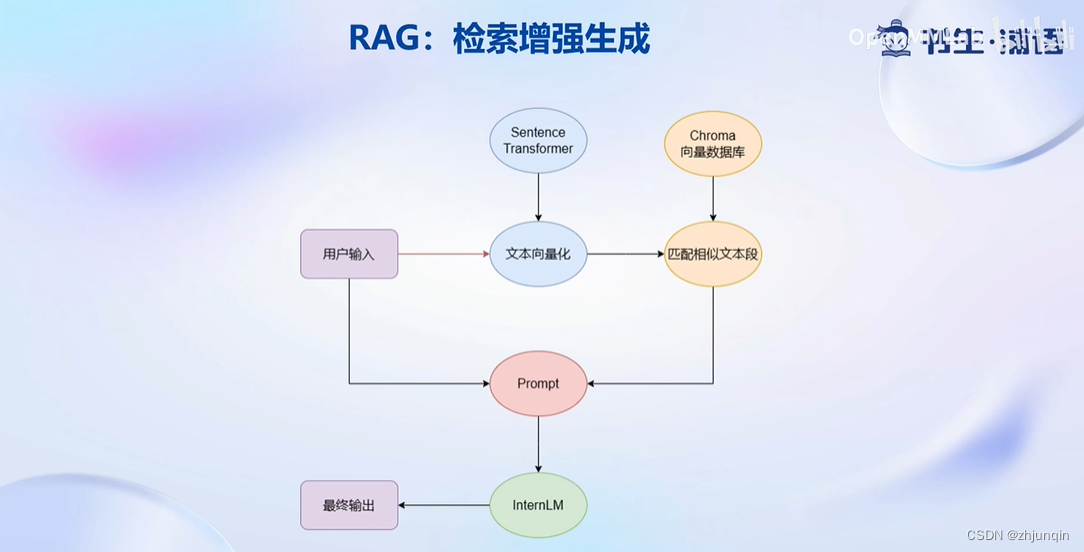
2. LangChain 简介


3. 构建向量数据库
4. 搭建知识库助手

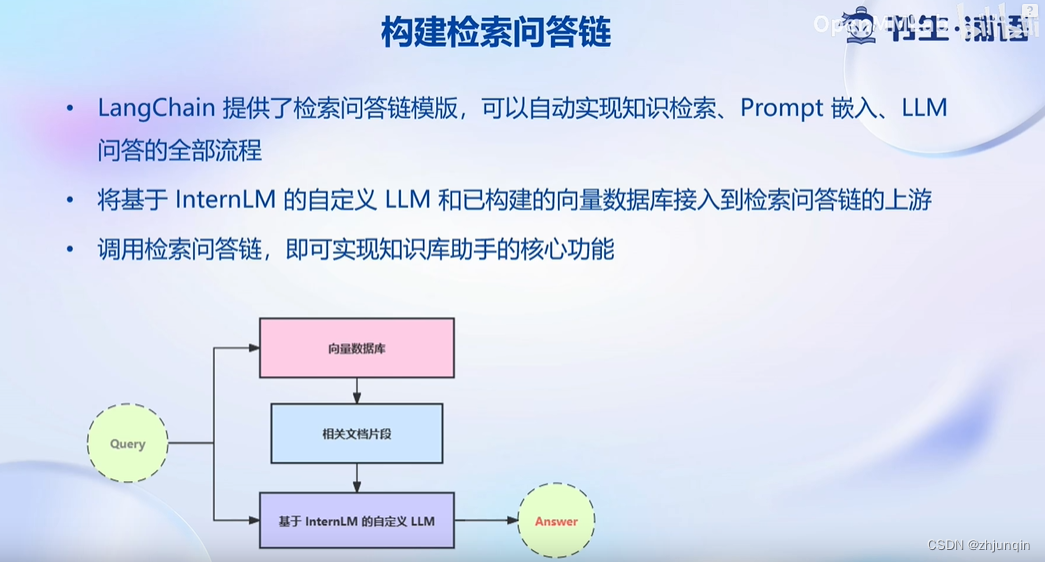

操作过程
详细操作过程就不一一记录,文档里面挺详细,这里记录一些知识点和问题。
1. NLTK
NLTK (Natural Language Toolkit) 是一个用于自然语言处理 (NLP) 的Python库。NLTK 包含了一系列用于文本处理、分析、语言学研究以及机器学习的函数和类。
其中的 punkt 是 NLTK (Natural Language Toolkit) 库中的一个重要模块,用于句子分割(句子切分)。
在 NLTK 中,punkt 是一个训练好的分词器(tokenizer)模型,它能够根据不同语言中的标点、空格和其他规则来将文本分割成句子或单词。这个模块使用的是一种基于无监督学习的方法,通过分析大量文本来自动学习句子和单词的分割规则,因此可以适用于多种语言和不同文本类型。
Langchain 依赖于 NLTK 中的 punkt 模块。 这个文档 https://python.langchain.com/docs/integrations/document_loaders/unstructured_file 里面需要先下载 punkt 。
# import nltk
# nltk.download('punkt')
2. create_db.py
如果直接使用这个文件 https://github.com/InternLM/tutorial/blob/main/langchain/demo/create_db.py
记得修改下面的代码
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs[:10]) # 这里只截取了前10 个文件,需要修改成 docs
主要是下面几个 API 完成了文本的分块和向量化
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
3. 加载模型
常见的加载模型的代码,下面代码用了 bf16
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()
self.model = self.model.eval()
4. 问答的代码
下面的代码完成了,加载向量数据库,查询向量数据库,构造 prompt,然后将查询的消息提交到 LLM。
# 加载问答链
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embeddings
)
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
template = """使用以下上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答你不知道。
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
# 运行 chain
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
原来的 prompt 有时候会答非所问,而且偶尔还会有乱码,我尝试修改了一下,把顺序换了一下,问句放到后面去了,感觉效果好很多
template = """请使用以下提供的上下文来回答用户的问题。如果无法从上下文中得到答案,请回答你不知道,并总是使用中文回答。
提供的上下文:
···
{context}
···
用户的问题: {question}
你给的回答:"""
参考文档
- https://www.cnblogs.com/chentiao/p/17617402.html















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









