










VGG16-keras实现步骤
文章目录
最近在复现一些基础的论文,怕自己忘得太快了,记录一下笔记,后续会逐渐更新。
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
创建Notebook环境
在ModelArts中创建免费的GPU资源环境,存储空间为5GB,存储路径为/home/ma-user/work,Tensorflow-1.18.1。
下载数据资源
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \
-O cats_and_dogs_filtered.zip
解压数据
!unzip cats_and_dogs_filtered.zip
引入相关库
import keras,os
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPool2D , Flatten
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
数据读取
trdata = ImageDataGenerator()
traindata = trdata.flow_from_directory(directory="cats_and_dogs_filtered/train",target_size=(224,224))
tsdata = ImageDataGenerator()
testdata = tsdata.flow_from_directory(directory="cats_and_dogs_filtered/validation", target_size=(224,224))

建立模型
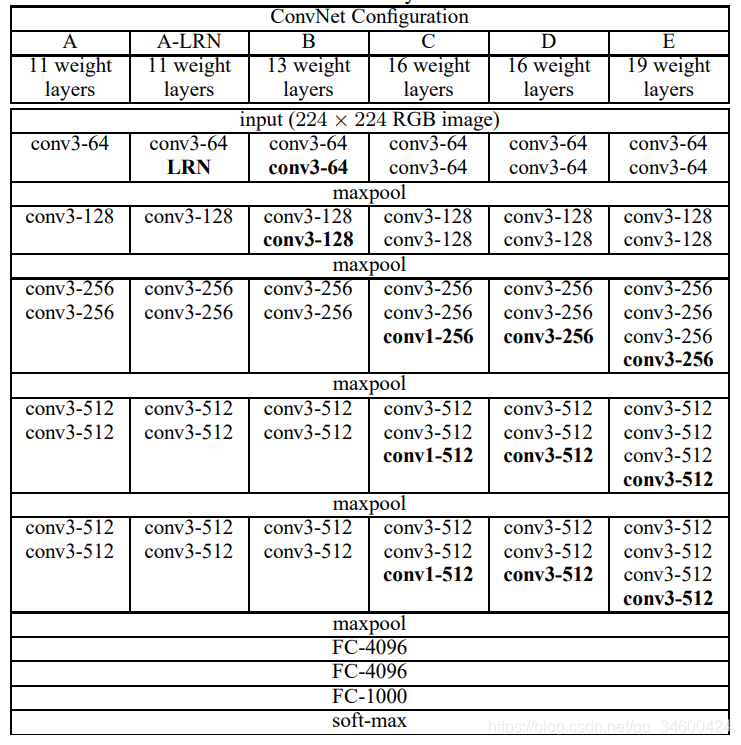
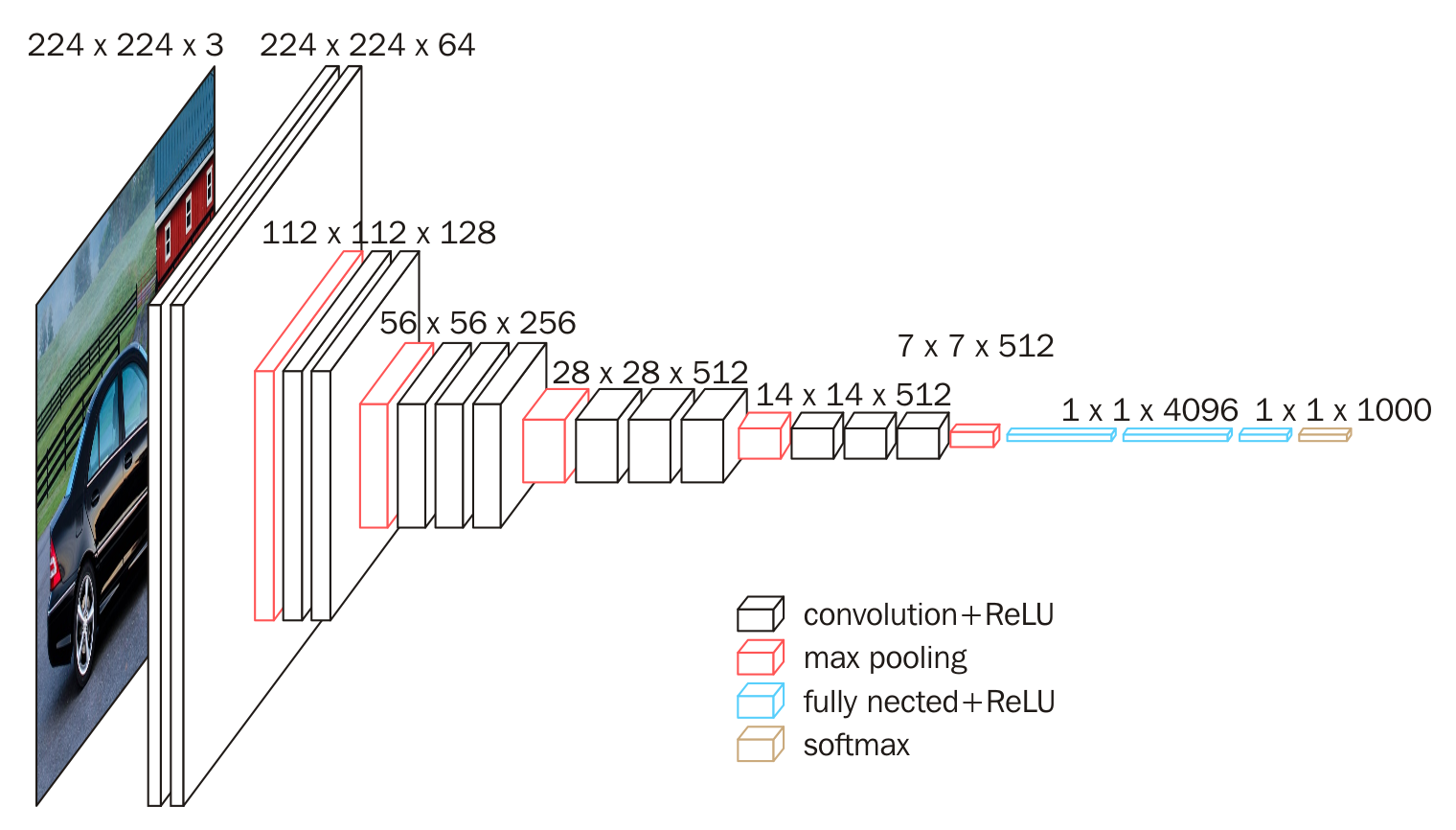
上图上半部分相对直观,下半部分是一种常见的普通网络结构的表示方法,下半部分最后一层不应该是4096,应该是分类问题的类别数目 num_classes。对照上述模型结构图,添加相关层结构,建立序贯式模型如下
# 使用序贯式模型
model = Sequential()
# 两个3*3*64卷积核 + 一个最大池化层
model.add(Conv2D(input_shape=(224,224,3),filters=64,kernel_size=(3,3),padding="same", activation="relu"))
model.add(Conv2D(filters=64,kernel_size=(3,3),padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
# 两个3*3*128卷积核 + 一个最大池化层
model.add(Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=128, kernel_size=(3,3), padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
# 三个3*3*56卷积核 + 一个最大池化层
model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=(3,3), padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
# 三个3*3*512卷积核 + 一个最大池化层
model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
# 三个3*3*512卷积核 + 一个最大池化层
model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=(3,3), padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
# Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
# 连接三个全连接层Dense,最后一层用于预测分类。
model.add(Flatten())
model.add(Dense(units=4096,activation="relu"))
model.add(Dense(units=4096,activation="relu"))
model.add(Dense(units=2, activation="softmax"))
# 打印模型结构
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
conv2d_2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 112, 112, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
conv2d_4 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 56, 56, 128) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv2d_6 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
conv2d_7 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 28, 28, 256) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
conv2d_10 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 14, 14, 512) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_13 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 7, 7, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 25088) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 102764544
_________________________________________________________________
dense_2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_3 (Dense) (None, 2) 8194
=================================================================
Total params: 134,268,738
Trainable params: 134,268,738
Non-trainable params: 0
_________________________________________________________________
训练模型
# 定义模型优化器, 使用分类交叉熵损失
from keras.optimizers import Adam
opt = Adam(lr=0.001)
model.compile(optimizer=opt, loss=keras.losses.categorical_crossentropy, metrics=['accuracy'])
# 定义模型和精度计算方式
from keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint = ModelCheckpoint("vgg16_1.h5", monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
early = EarlyStopping(monitor='val_acc', min_delta=0, patience=20, verbose=1, mode='auto')
# 训练模型并计算精度
hist = model.fit_generator(steps_per_epoch=100,generator=traindata, validation_data= testdata,\
validation_steps=10,epochs=100,callbacks=[checkpoint, early])
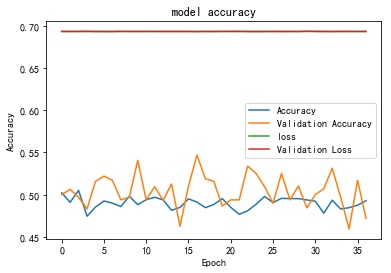
最终训练到17个epoch就收敛了,训练过程如下:

绘制精度和损失函数
import matplotlib.pyplot as plt
plt.plot(hist.history["acc"])
plt.plot(hist.history['val_acc'])
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title("model accuracy")
plt.ylabel("Accuracy")
plt.xlabel("Epoch")
plt.legend(["Accuracy","Validation Accuracy","loss","Validation Loss"])
plt.show()
推理预测
from keras.preprocessing import image
img = image.load_img("Pomeranian_01.jpeg",target_size=(224,224))
img = np.asarray(img)
plt.imshow(img)
img = np.expand_dims(img, axis=0)
from keras.models import load_model
saved_model = load_model("vgg16_1.h5")
output = saved_model.predict(img)
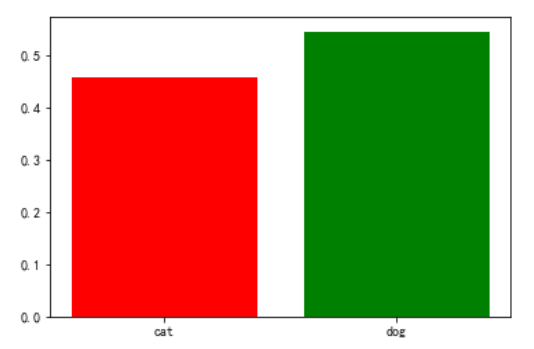
if output[0][0] > output[0][1]:
print("cat")
else:
print('dog')
dog

# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
name_list = ['cat','dog']
num_list = [output[0][0], output[0][1]]
plt.bar(range(len(num_list)), num_list,color='rgb',tick_label=name_list)
plt.show()
提升策略
降低学习率
上面我们看到模型的精度不是很高,对比了其他人的代码,发现学习率设置的有点太大了,我是 1 e − 3 1e^{-3} 1e−3,结果别人是 1 e − 5 1e^{-5} 1e−5,让我们把学习率降低试试。
下面是训练结果,精度果然提升了很多

模型训练精度得到了很大提升,不过验证精度还是停在了85%左右。

推理预测
同样进行推理预测,可以看出预测结果的置信度也提高了很多。


思考总结
最后训练好的模型为什么这么大?
存在问题
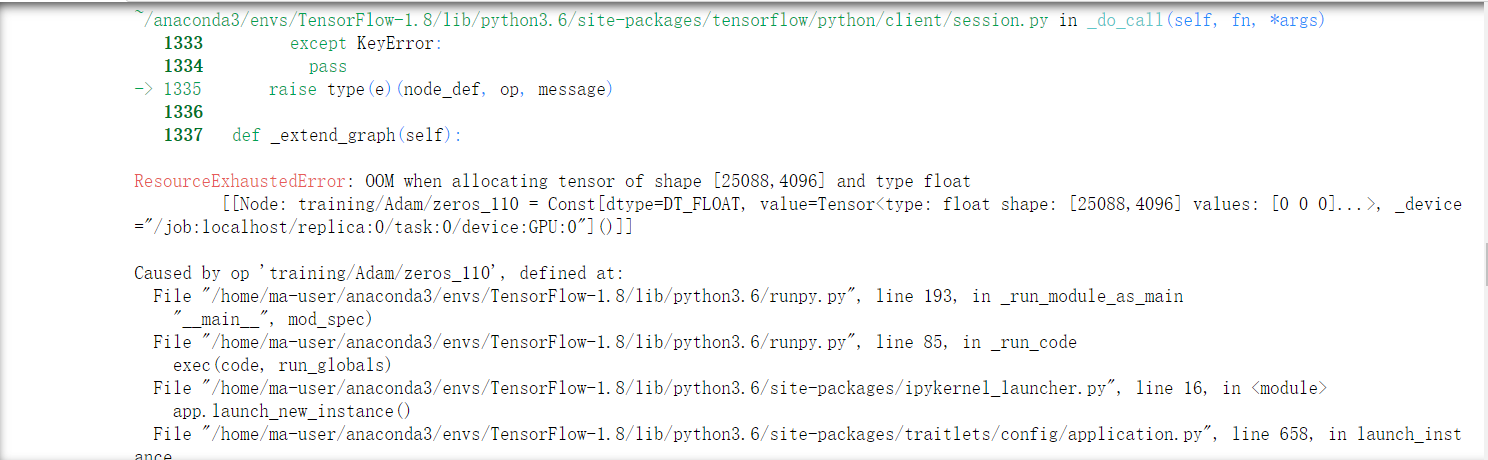
当向模型中添加了若干个BatchNormalization层之后,训练提示内存不足,原作者在论文中提出,添加BN层不会显著提高精度,反而会导致计算开销增加和速度降低,所以还是别用BN层好了。
重点总结
VGG16基本上是在Alexnet网络架构的架构上进行改进,但是层数显著提升(翻了几倍),这个阶段,主要是没有解决网络太深梯度反向传播消失的问题。
- VGG 你会觉得就是在 AlexNet 网络上没一层进行了改造,5个 stage 对应 AlexNet 中的5层卷积,3层全连接仍然不变。
- 图片输入的大小还是沿用了 224x224x3
- 网络更深,训练出来的效果确实比 AlexNet 有所提升
调优策略
- 采用早停策略,有利于抑制过拟合
- 学习率要设置比较低,一般是
1
e
−
5
1e^{-5}
1e−5左右,还可以设置学习率衰减。
参考链接:
https://zhuanlan.zhihu.com/p/60235326
https://blog.csdn.net/u014453898/article/details/97785190?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-13&spm=1001.2101.3001.4242等


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











