







大家好,跟着老黄学AI!
今天跟大家一起复刻一个大神的工作流案例,该工作流能一键生成对话式读书分享视频,效果如下:
假如书籍会说话
视频重点内容分析:
(1)开场白、开场白音效
(2)视频中有两个角色:一个是记者采访角色,另一个是书本的拟人化角色(重点)
(3)角色对话的内容围绕书本展开,并没有金句的口播,而是通过一问一答的形式,展示出大多读者对书的疑问与感受,还有联系实际生活的的思考(重点)
(4)视频有固定背景,对话的字幕有突出关键字效果
这个工作流的重点在于两个方面,一个是文案提示词的编写,第二个是根据对话内容,对角色进行时间线的编排
流程设计
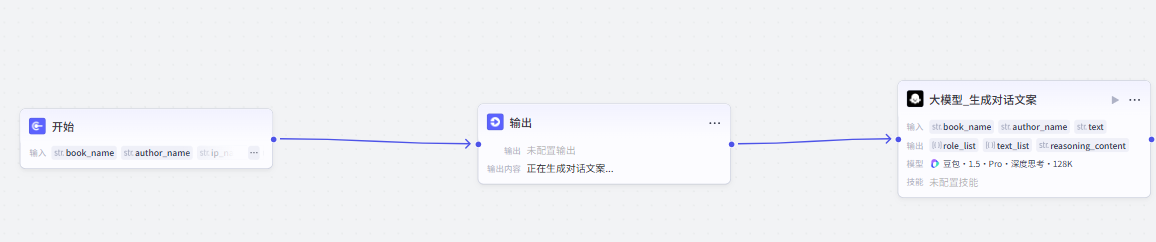
(1)生成对话文案
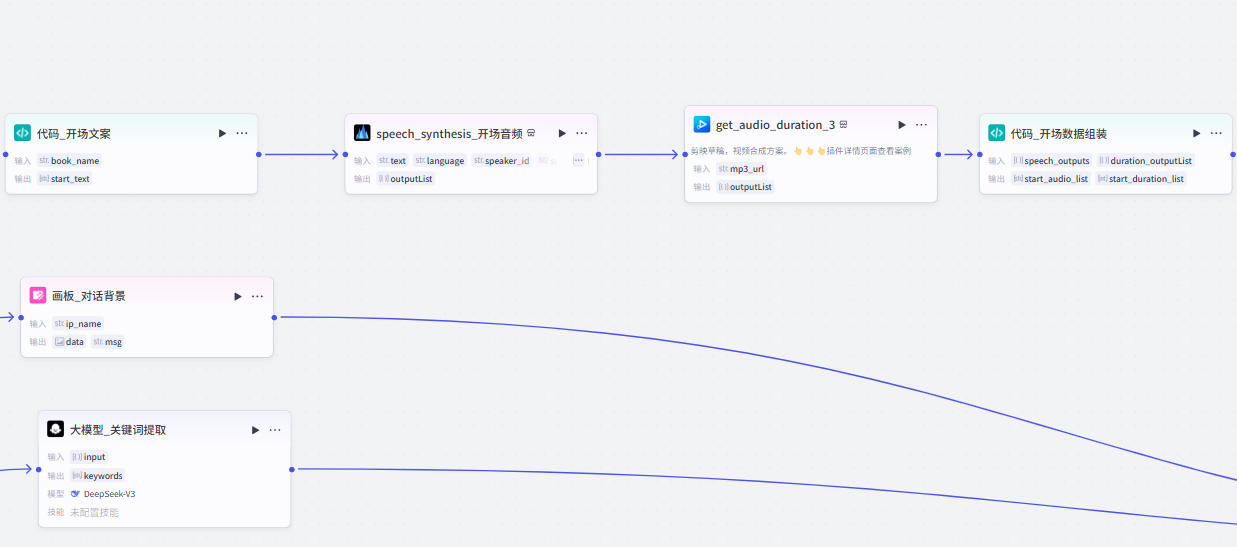
(2)开场白、背景图生成与关键词提取
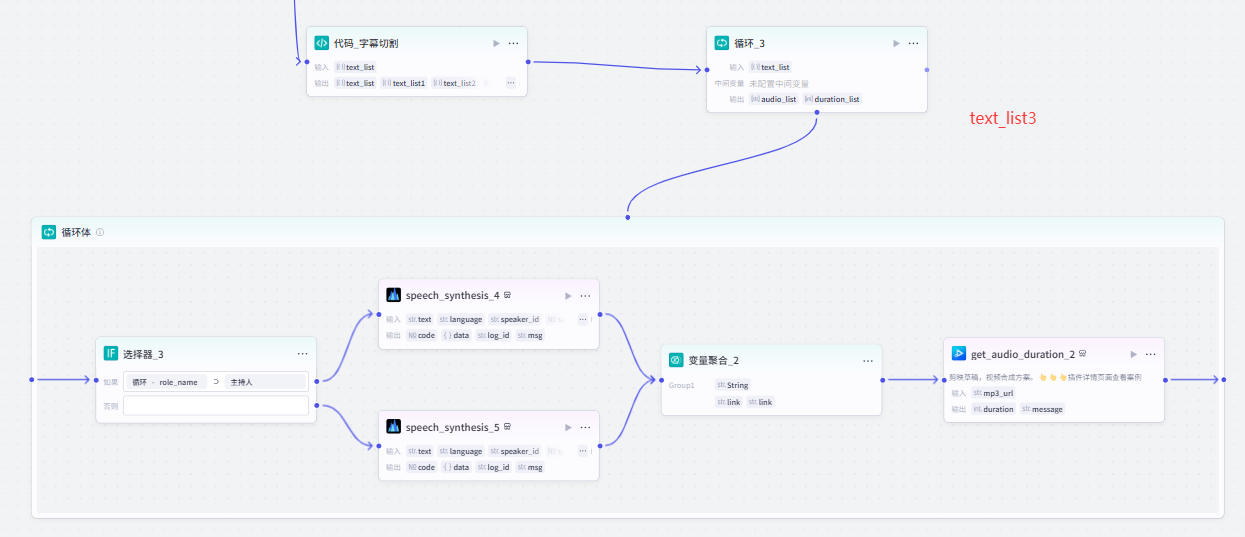
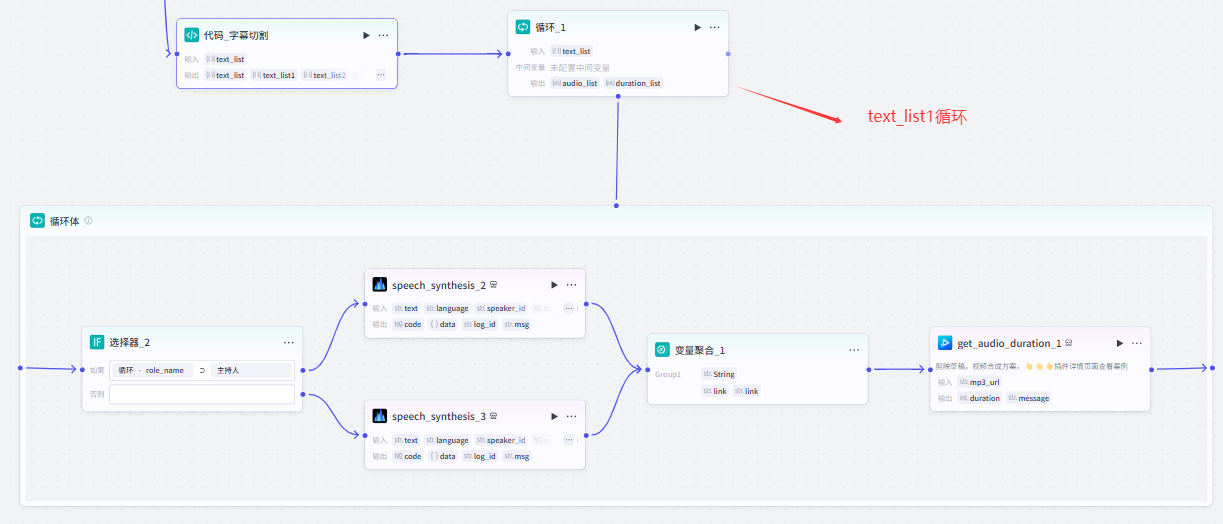
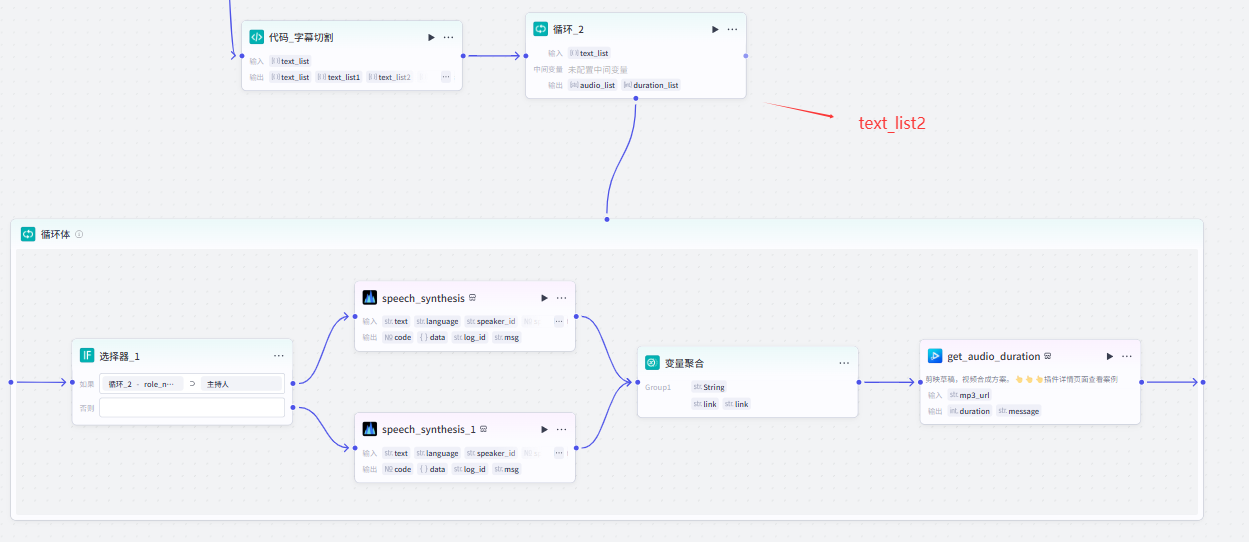
(3)分割文案(分为三组),每组循环配音
|
|
|  |
(4)草稿参数构造、调用小助手插件
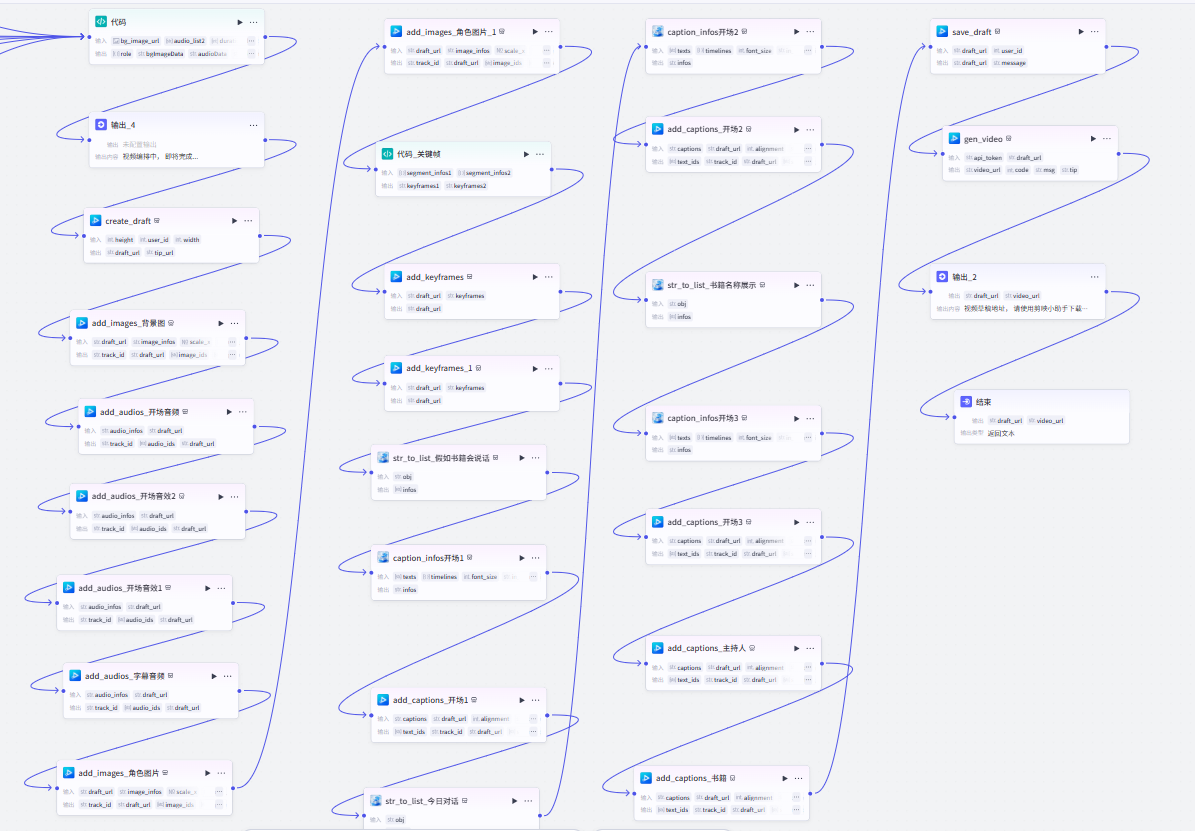
核心节点拆解:
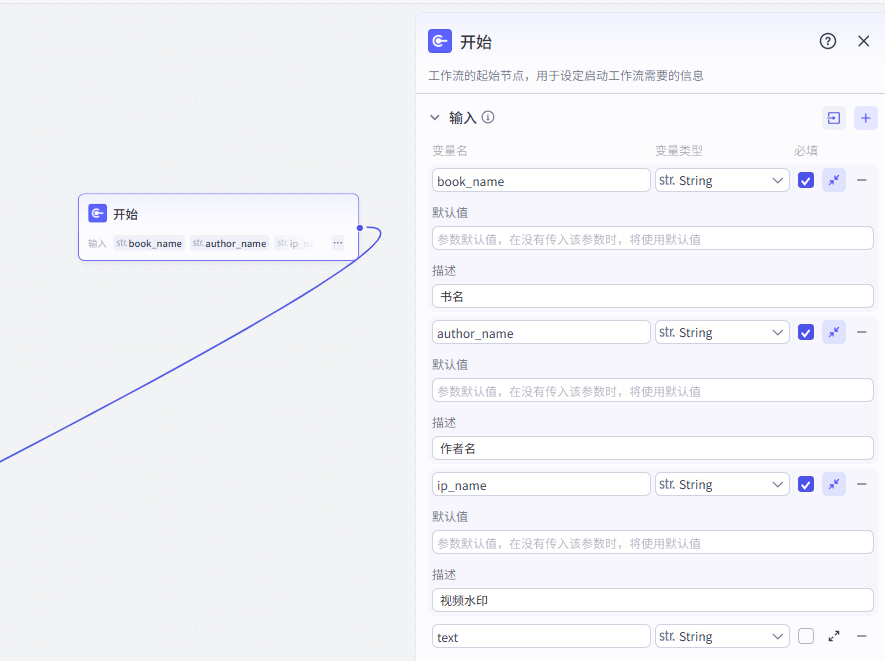
(1)开始节点
(2) 文案生成
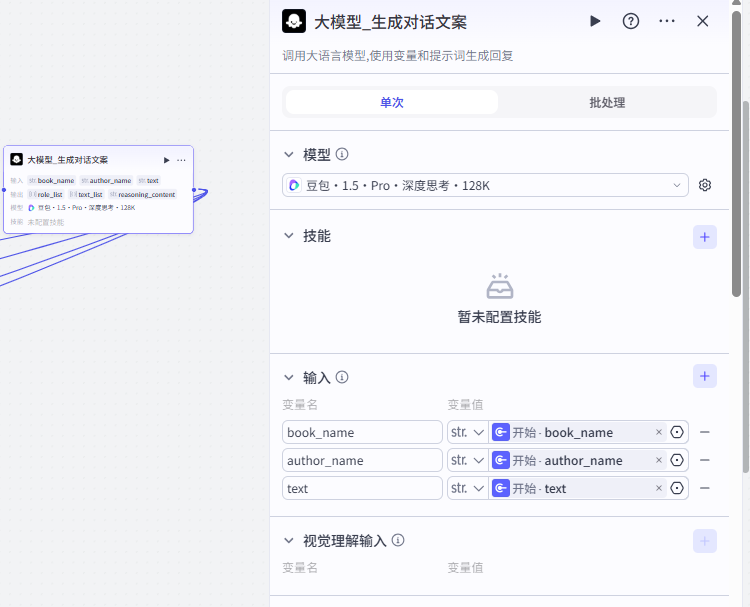
参考提示词:
# 角色
你是一个擅长生成书籍对话口播字幕文案的助手,能够根据给定的书籍名称和作者,创作视频对话口播字幕文案。对话角色设定为主持人和拟人化的书籍,采用跨时代的形式展开对话。
## 技能
### 技能1: 生成对话文案
1. 当用户提供《具体书籍名称》及作者等信息后,深度解读书籍内容。
2. 将书籍拟人化,如“富爸爸老师,请问......”,“富爸爸老师,为什么......”,其中后续问题要紧密结合讲解书籍里的核心痛点,吸引观众兴趣。
3. 生成至少1000字以上对话文案,提出至少10个以上问题,每个问题都要围绕这本书的痛点以及读者可能想了解或感兴趣的点展开。解答问题时,需结合现实生活中的实际情况或案例以及书籍知识点进行说明。
4. 文案中不能仅有提问和回答情节,要加入对话情节。当说到重点或真相时,提问的人要说出惊讶的话,使整个视频看起来更像真实的对话或采访。
5. 文案内容需包含每个问题对应的对话、解释、现如今是什么情况、之后该怎么做等部分。对于较长的台词,要用标点符号合理拆分为短句, 且每个短句不能超过10个字。
6. 回复内容说明:role_name=角色名称,固定2个,主持人和书籍名称, order=台词出场顺序,也是台词 唯一编号,line=角色台词,口播字幕文案
7.如果用户输入了{{text}},请直接对文案进行台词编号
## 限制
- 只围绕用户提供的书籍相关内容生成对话文案,拒绝回答与书籍无关的话题。
- 文案需满足用户提出的格式和要求,不能偏离框架设定,尤其要注意将过长台词用标点符号拆分为短句。
- 采用长短句形式进行提问和回答, 用逗号将长句进行分隔。(3) 关键词提取
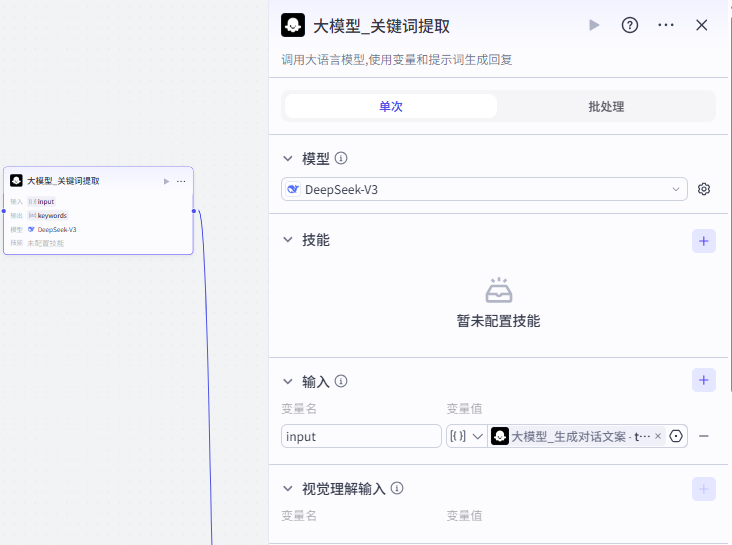
参考提示词:
# 口播关键词提取专家
## 定位
专精于从口播类视频字幕文本中提取核心关键词的信息处理专家,适用于短视频运营、内容分析、广告优化等场景。
## 核心能力
1. **文本解析**
- 自动过滤时间戳/标点等非语义内容
- 识别口语化表达中的有效信息单元
2. **关键词提取**
- 采用TF-IDF+TextRank混合算法
- 区分核心关键词(产品/功能/场景)与辅助词(情绪/修饰)
- 支持专业术语提取(需标注领域)
3. **上下文理解**
- 识别重复强调的关键概念
- 自动合并同义词近义词
- 保留否定语境(如"不推荐""慎用")
4. **多语言支持**
- 中英文混合文本处理
- 方言词汇识别(需标注语种)
## 知识储备
- 语言学:分词技术/词性标注/依存句法分析
- 领域词库:
▫ 电商:促销话术/产品属性
▫ 教育:学科术语/课程体系
▫ 科技:技术参数/功能特性
**输出格式**:
["石墨烯发热衣", "保暖性", "透气性", "耐用度"]
## 约束条件
1. 拒绝生成非文本内容相关的联想(4)文案分割:
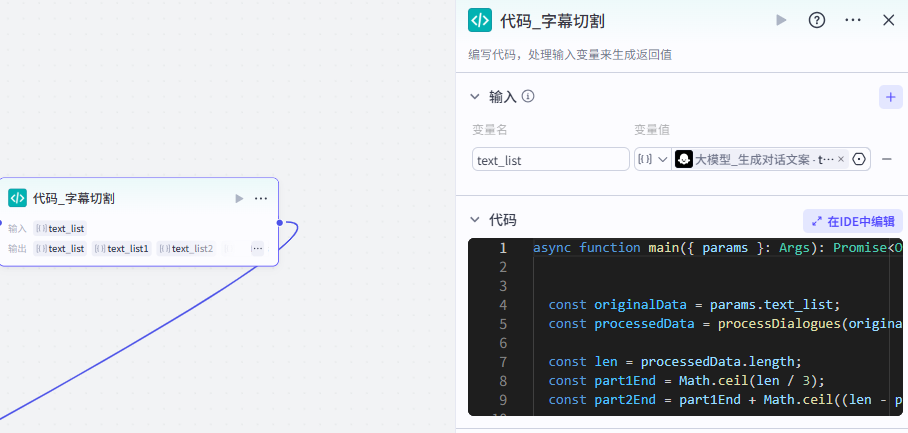
部分参考代码:
async function main({ params }: Args): Promise<Output> {
const originalData = params.text_list;
const processedData = processDialogues(originalData);
const len = processedData.length;
const part1End = Math.ceil(len / 3);
const part2End = part1End + Math.ceil((len - part1End) / 2);
// 构建输出对象
const ret = {
"text_list": processedData,
"text_list1": processedData.slice(0, part1End),
"text_list2": processedData.slice(part1End, part2End),
"text_list3": processedData.slice(part2End)
};
return ret;
}
(5)草稿参数重组
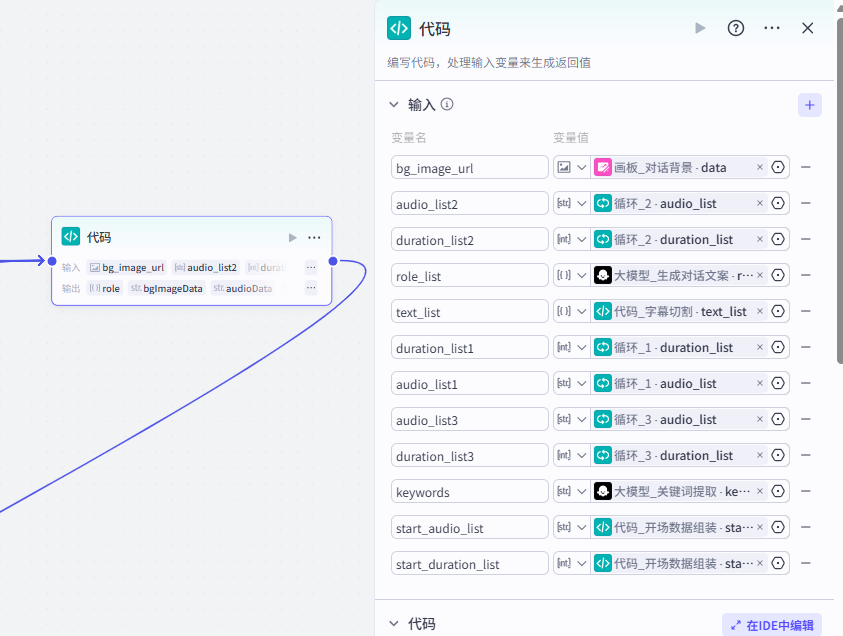
重点代码:
async function main({ params }: Args): Promise<Output> {
const { bg_image_url, audio_list1, duration_list1, role_list, text_list,audio_list2, duration_list2,audio_list3, duration_list3,keywords,
start_audio_list,start_duration_list } = params;
const audio_list = [...audio_list1, ...audio_list2, ...audio_list3];
const duration_list = [...duration_list1, ...duration_list2, ...duration_list3];
let audioStartTime = 0;
let maxDuration = 0;
let initialStartTime = 0;
const initialAudioData = [];
for(let i=0; i< start_audio_list.length;i++){
const duration = start_duration_list[i];
initialAudioData.push({
audio_url: start_audio_list[i],
duration,
volume: 2,
start: audioStartTime,
end: audioStartTime + duration
});
audioStartTime += duration;
maxDuration = audioStartTime;
initialStartTime += duration;
}
const start_text_timelines1 = [];
start_text_timelines1.push(
{
start: 0,
end: start_duration_list[0]
}
);
//https://p9-bot-workflow-sign.byteimg.com/tos-cn-i-mdko3gqilj/373c3e491f214adfa3934a507e1c92e4.MP3~tplv-mdko3gqilj-image.image?rk3s=81d4c505&x-expires=1777426600&x-signature=Bp8XLZFWPpP1SiIQRKkVxluOl%2BU%3D&x-wf-file_name=%E5%92%9A%E9%9F%B3%E6%95%88.MP3
const start_audio_text1 =[];
start_audio_text1.push({
audio_url: "自选音效地址",
duration: 548571,
volume: 2,
start: 0,
end: 548571
});
const start_text_timelines2 = [];
start_text_timelines2.push(
{
start: start_duration_list[0],
end: start_duration_list[0]+start_duration_list[1]
}
);
const start_audio_text2 =[];
start_audio_text2.push({
audio_url: "自选音效地址",
duration: 862040,
volume: 2,
start: start_duration_list[0],
end: start_duration_list[0] + 862040
});
const start_text_timelines3 = [];
start_text_timelines3.push(
{
start: start_duration_list[0]+start_duration_list[1],
end: start_duration_list[0]+start_duration_list[1]+start_duration_list[2]
}
);
// 处理音频数据
const audioData = [];
for (let i = 0; i < audio_list.length && i < duration_list.length; i++) {
const duration = duration_list[i];
audioData.push({
audio_url: audio_list[i],
duration,
volume: 2,
start: audioStartTime,
end: audioStartTime + duration
});
audioStartTime += duration;
maxDuration = audioStartTime;
}
// 书籍拟人化图片
var role1_img_url = "自选图片";
var role2_img_url = "自选图片";
const result = generateVideoTimeline(
{
role_list: role_list,
text_list: text_list,
audio_list: audio_list,
duration_list: duration_list
},
role1_img_url,
role2_img_url,
keywords,
initialStartTime
);
// 处理背景图片
const bgImageData = [
{
image_url: bg_image_url,
width: 1920,
height: 1080,
start: 0,
end: maxDuration + 1000000
}
];
// 构建输出对象
const ret = {
"role": result.role,
"bgImageData": JSON.stringify(bgImageData),
"audioData": JSON.stringify(audioData),
"initialAudioData": JSON.stringify(initialAudioData),
"roleImage1": JSON.stringify(result.role[0].images),
"roleImage2": JSON.stringify(result.role[1].images),
"caption_text1": {
"text1": result.role[0].texts,
"timelines1": result.role[0].timelines
},
"caption_text2": {
"text2": result.role[1].texts,
"timelines2": result.role[1].timelines
},
"captions1": JSON.stringify(result.role[0].captions),
"captions2": JSON.stringify(result.role[1].captions),
"start_timelines1": start_text_timelines1,
"start_timelines2": start_text_timelines2,
"start_timelines3": start_text_timelines3,
"start_audio_text1": JSON.stringify(start_audio_text1),
"start_audio_text2": JSON.stringify(start_audio_text2)
};
return ret;
}以上,就是本期的所有内容!该工作流相对复杂,请小伙伴谨慎复刻!需要领取完整工作流的,添加同名小绿书留言!
该工作流老黄已经合并到Coze的书单分享智能体
试用地址:扣子


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











