






代码内容参考:08 线性回归 + 基础优化算法【动手学深度学习v2】;
最近在看李沐老师的【动手学深度学习 v2】,在线性回归部分,由于本人知识储备有限,对with torch.no_grad()不是很理解,在结合一些相关博文解释和自己不断运行代码的情况下,认为with torch.no_grad()主要可以在两种情况下使用。
1. 优化参数时用来更新参数
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params: # param 是一个list,如果模型是y=Xw+b,则param=[w,b]
param -= lr * param.grad / batch_size
param.grad.zero_()可以看到上图中with torch.no_grad()用在了对参数param(这里是线性回归,参数表示的就是w和b)更新的时候,我们可以尝试将with torch.no_grad()去掉再去运行代码:
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
# with torch.no_grad():
for param in params: # param 是一个list
param -= lr * param.grad / batch_size
param.grad.zero_()
-------------------------------------------------------------------------------------------
# 报错内容:
Cell In[98], line 5, in sgd(params, lr, batch_size)
3 # with torch.no_grad():
4 for param in params: # param 是一个list
----> 5 param -= lr * param.grad / batch_size
6 param.grad.zero_()
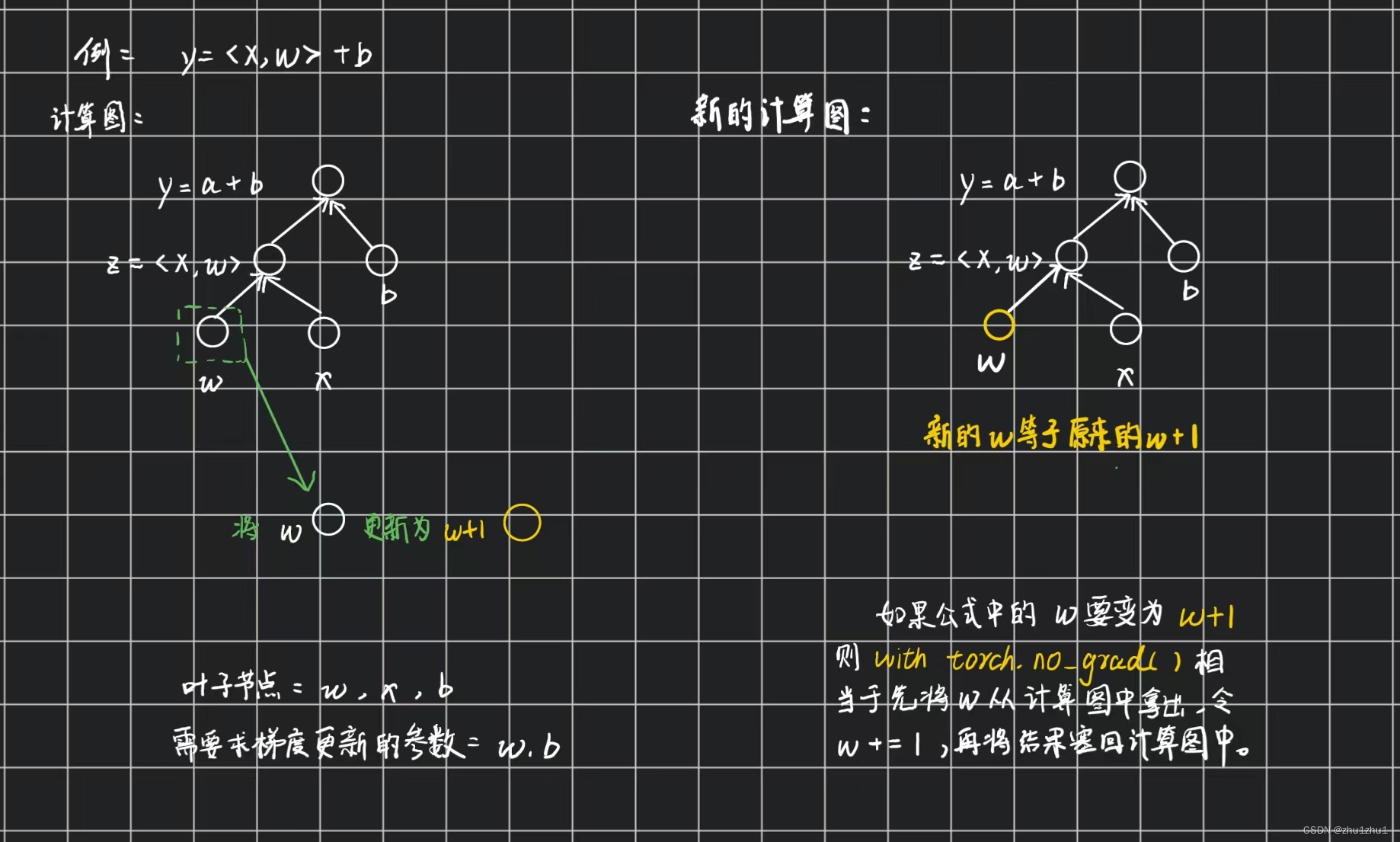
RuntimeError: a leaf Variable that requires grad is being used in an in-place operation.可以看到运行到最后调用优化参数函数sgd时报错(上图只放了定义sgd函数和报错的内容,没有放调用函数的代码)。报错原因是由于参数param,即w和b在计算图中是叶子节点,而计算图中的叶子节点是不能直接进行运算,所以这里的with torch.no_grad()我认为可以理解为让参数param暂时脱离出计算图,将其修改后的内容当作param再塞到计算图中。
2.模型评估
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')对于模型评估,很多博客对于使用使用with torch.no_grad()原因的解释大致为:在模型评估的时候,只需要计算loss,而不再需要更新参数,所以使用with torch.no_grad()的原因是为了减少计算梯度造成的内存消耗。
这里我有个问题是这里的loss没有.backward()进行反向传播,那不就不会计算梯度吗?
后面查了很多博客,找到一个我认为相对比较合理的理由,那就是虽然没有进行反向传播,但前向传播的时候会构建计算图,由于参数的requires_grad=True,所以会不断存储反向传播中需要用到的前向传播中算出的中间值,如果使用with torch.no_grad()就不会生成计算图,也就可以避免不必要的内存消耗。















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









