







1. 分类
- 固定输入最短边大小为256(训练使用多尺度缩放)
- 提取5个随机剪裁和水平翻转的231 × 231图片
- batchSize 128
- 权重初始化均值0,标准差0.01的均匀分布,
- momentum 0.6
- 惩罚系数1e-5
- 学习率0.05,(30, 50, 60, 70, 80) epochs分别降低0.5
- 全连接层dropout 0.5
- 不使用局部响应归一化
- 池化操作非重叠
注意: 训练过程中输出是没有空间性的(输出特征图1 × 1),但是预测过程中是有空间性的。在空间性上全连接层可以看作1 × 1卷积层。
| 操作 | 结果 |
|---|---|
| 输入训练集 | (batchSize,3,231,231) |
| 卷积层(96,3,11,11)stride(4,4)无pad | (batchSize,96,56,56) |
| 最大池化(2,2) | (batchSize,96,28,28) |
| 卷积层(256,96,5,5)stride(1,1)无pad | (batchSize,256,24,24) |
| 最大池化(2,2) | (batchSize,256,12,12) |
| 卷积层(512,256,3,3)stride(1,1)pad(1,1) | (batchSize,512,12,12) |
| 卷积层(1024,512,3,3)stride(1,1)pad(1,1) | (batchSize,1024,12,12) |
| 卷积层(1024,1024,3,3)stride(1,1)pad(1,1) | (batchSize,1024,12,12) |
| 最大池化(2,2) | (batchSize,1024,6,6) |
| 展开 | (batchSize,1024 × 6 × 6 = 36864) |
| 全连接层(36864,3072) | (batchSize,3072) |
| 全连接层(3072,4096) | (batchSize,4096) |
| softmax层(4096,1000) | (batchSize,1000) |
| 测试全连接层权重 | 转化的卷积层权重 |
|---|---|
| (50176,3072) | (3072,1024,7,7) |
| (3072,4096) | (4096,3072,1,1) |
| (4096,1000) | (1000,4096,1,1) |
多尺度分类
在ImageNet Classification论文中使用的4个角落和中心的5个区域以及水平翻转对应的区域共10个区域,采用的是单尺度,忽略了很多区域且有冗余计算。对一个固定尺度的图像在第五层特征图(例如20 × 20)的增强操作如下:- 对一个固定尺度的单张图像,从第五层的未池化20 × 20特征图开始
- 每一个未池化特征图,在水平、垂直偏置分别为{0,1,2}的9种情况下做3 × 3的最大非重叠池化,得到9张池化后的6 × 6特征图
- 后3全连接层转化的卷积层有固定的5 × 5的输入大小,分别对9张池化后的特征图使用移动窗口的模式进行操作,得到1000个类别每个类别9张2 × 2特征图
- 将每个类别9张特征图组合成为1张6 × 6特征图,从而结果为3维(1000,6,6)
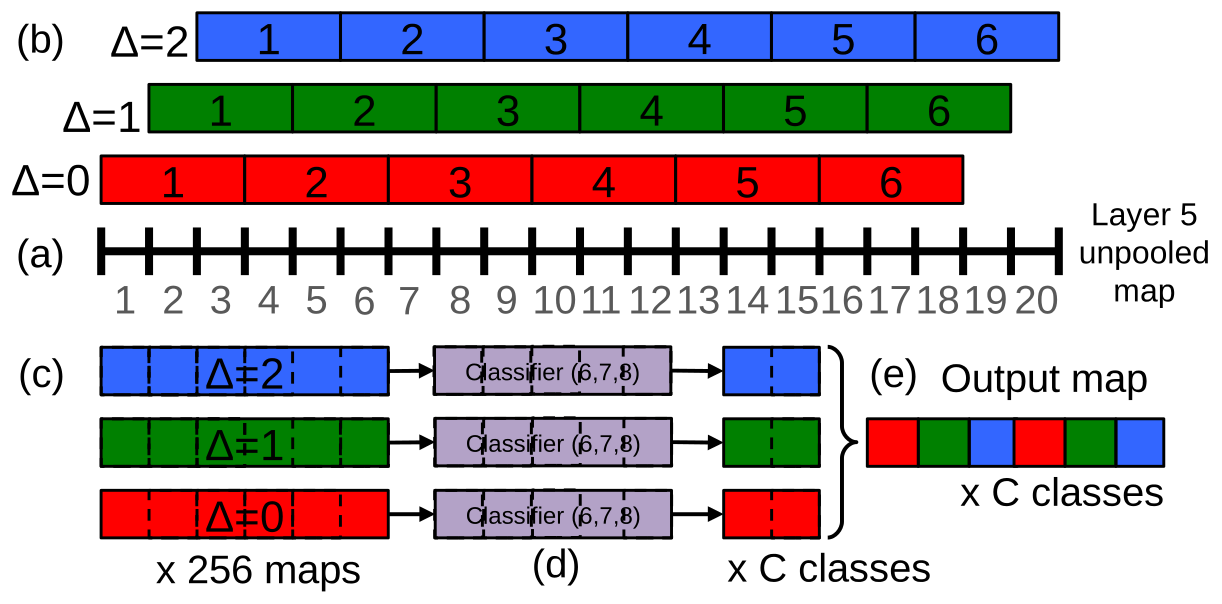
操作流程的1维展示
对于一个固定尺度的图像的水平翻转也做同样的操作。再对多个尺度的图像(本文一共有6个)进行操作,最终分类结果为:分别取一个类别中尺度和翻转结果中最大值(平均值)作为该类别的预测分数。
- 卷积网络具有内在的移动窗口模式
训练时保持全连接层不变,而在测试时将网络全连接层转化为1 × 1的卷积层得到一个全卷积网络,如果输入更大的图片,就可以将输出1 × 1的点扩展为一张类别预测图,该图中每一个点对应于输入的一个窗口。因为在测试时所有的层都是卷积层,那么网络就只有一系列的卷积、池化和阈值操作了。
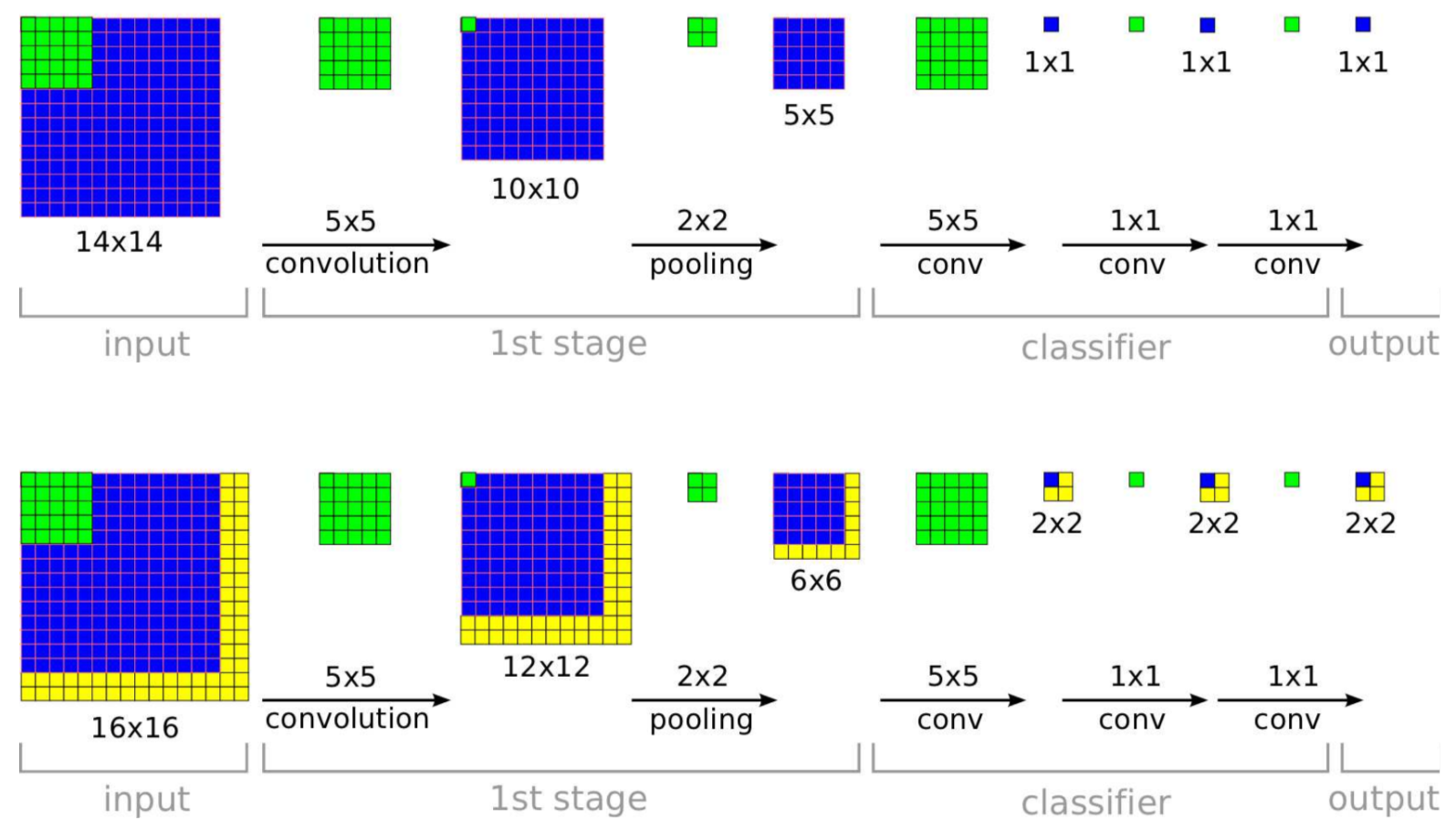
移动窗口
2. 定位
将训练好的分类网络最后3层分类器替代为一个回归网络,训练它来预测物体每个位置和尺度的边界框,然后结合每个位置的回归结果和分类结果。
生成物体边界框的预测
在所有位置和尺度上同时训练共享卷积层的分类器和回归器(在训练好卷积层和分类器之后,只需要重新计算回归器)。每个位置上对某个类别的分类概率都是这个类别的物体在该位置上出现(不是完全包含)的置信分数。我们可以把每个边界边框都赋予一个置信分数。回归网络使用预测与实际边界的 L2 损失,回归输出是与类别有关的(有1000个版本,对每个类别都有一个回归结果)。回归训练
回归网络的输入是第五层池化后的特征图,前两层为4096和1024个神经元,输出有4个神经元确定边界框的边界坐标。假设对于9个偏移情况中任意一个第五层池化后的特征图为256个6 × 7,第一层输入大小为5 × 5,卷积得到第一层4096个2 × 3,第二层则是全连接的,结果为1024个2 × 3,输出为4个2 × 3。
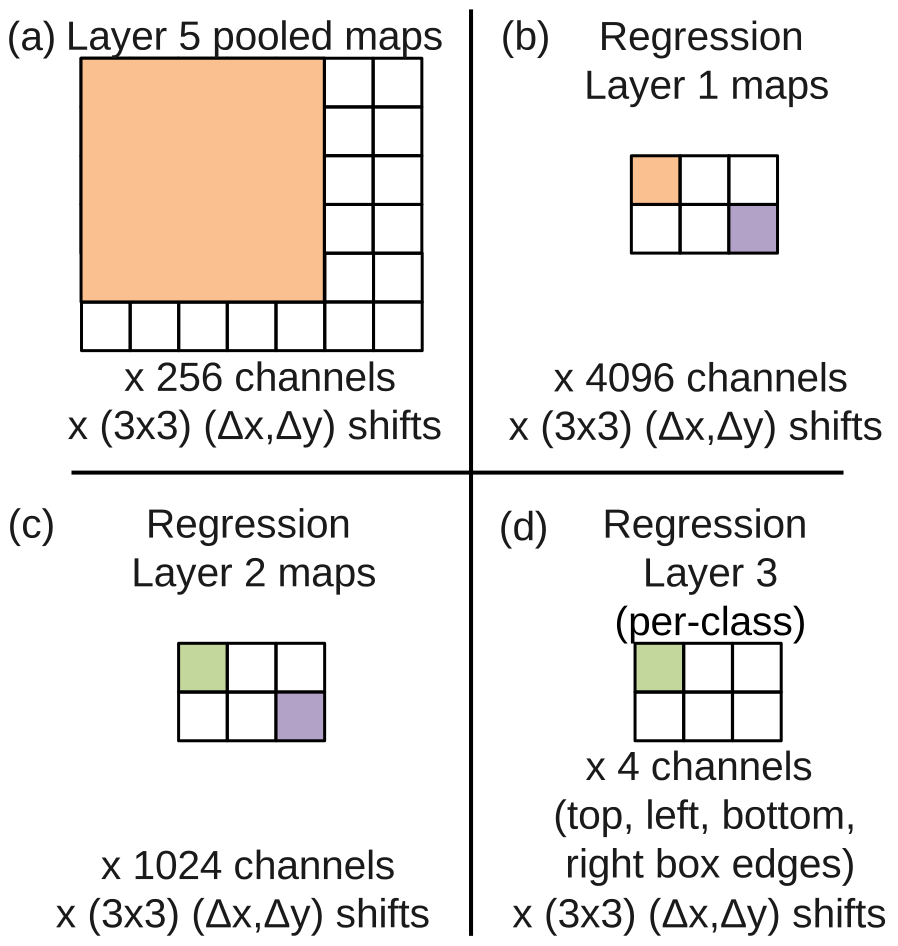
回归网络
- 合并预测结果
最终预测结果是合并具有最大类别分数的边界框,即通过累加定位的类别输出,这些类别输出是与预测边界框时使用的窗口有关的。
3. 检测
与定位不同的是在没有物体的使用需要预测一个背景类别,传统做法中负样本是随机选取的,而我们则是选取每张图片有意思的负样本。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









