







转载,原文地址:(39条消息) 理解dropout_雨石-CSDN博客_dropout
原文写的很棒很详细,大家可以去读一下,这里只是简短的摘录和理解。
一、理解dropout
开篇明义,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于梯度下降来说,由于是随即丢弃,故而每一个mini-batch都是在训练不同的网络。
dropout是CNN中防止过拟合提高网络效果的一个大杀器。
二、观点
1. 组合派
在Hinton的《A simple way to prevent neural networks from overfitting》一文中,提出了如下观点。
大规模的神经网络有两个缺点:(1)费时;(2)容易过拟合。
过拟合是很多机器学习的通病,过拟合了,得到的模型基本就废了。为了解决过拟合问题,一般会采用ensemble方法,即训练多个模型做组合。此时费时就成了一个大问题,不仅训练起来费时,测试多个模型也很费时。总之,几乎形成一个死锁。
dropout的出现很好的解决了这个问题。每次做完dropout,相当于从原始网络中找到了一个更瘦的网络,如下图:
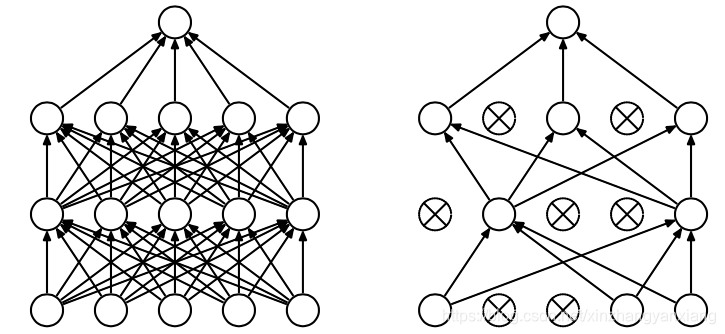
因而,对于一个N各节点的神经网络,有了dropout后,就可以看作是个模型的集合了,但此时要训练的参数数目是不变的,这就解决了费时的问题。
2. 动机论
虽然直观上看dropout是ensemble在分类性能上的一个近似,然而在实际中,dropout毕竟还是在神经网络上进行的,只训练出一套模型参数,那么它到底因何有效呢?这就要从动机上分析了。论文中作者对其做了精彩的类比:
在自然界中,在中大型动物中,一般是有性繁殖,有性繁殖是指后代的基因从父母两方各继承一半。但是从直观上看,似乎无性繁殖更加合理,因为无性繁殖可以保留大段大段的优秀基因。而有性繁殖则将基因随机拆了又拆,破坏了大段基因的联合适应性。
但是自然选择中毕竟没有选择无性繁殖,而选择了有性繁殖,须知物竞天择,适者生存。我们先做一个假设,那就是基因的力量在于混合的能力而非单个基因的能力。不管是有性繁殖还是无性繁殖都得遵循这个假设。为了证明有性繁殖的强大,我们先看一个概率学小知识。
比如要搞一次恐怖袭击,两种方式:
集中50人,让这50个人密切精准分工,搞一次大爆破。
将50人分成10组,每组5人,分头行事,去随便什么地方搞点动作,成功一次就算。
哪一个成功的概率比较大? 显然是后者。因为将一个大团队作战变成了游击战。
那么,类比过来,有性繁殖的方式不仅仅可以将优秀的基因传下来,还可以降低基因之间的联合适应性,使得复杂的大段大段基因联合适应性变成比较小的一个一个小段基因的联合适应性。
dropout同样能达到相同的效果。它强迫一个神经元,和随机挑出来的神经元共同工作,达到好的效果。消除减弱了神经元节点之间的联合适应性,增强了泛化能力。
3. 论文中其他的技术点
(1)dropout率的选择
——经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候随机生成的网络结构最多(2^n);
——dropout也可以被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数,使得输入变化不会太大(0.8)。
(2)数据量小的时候,dropout效果不好,数据量大的时候,dropout效果好;
4. 噪声观点
此处简单叙述一下,详细可去看原文。
观点十分明确,就是对每一个dropout后的网络,进行训练时,相当于做了Data Augmentation,即数据增强,因为总可以找到一个样本,使得在原始网络是也能达到dropout单元后的效果,即每一次dropout其实都相当于增加了样本。
三、实现
1. dropout带来的模型的变化
为了达到ensemble的特性,有了dropout后,神经网络的训练和预测会发生一些变化。
——训练层面
无可避免的,训练网络的每个单元要添加一道概率流程。
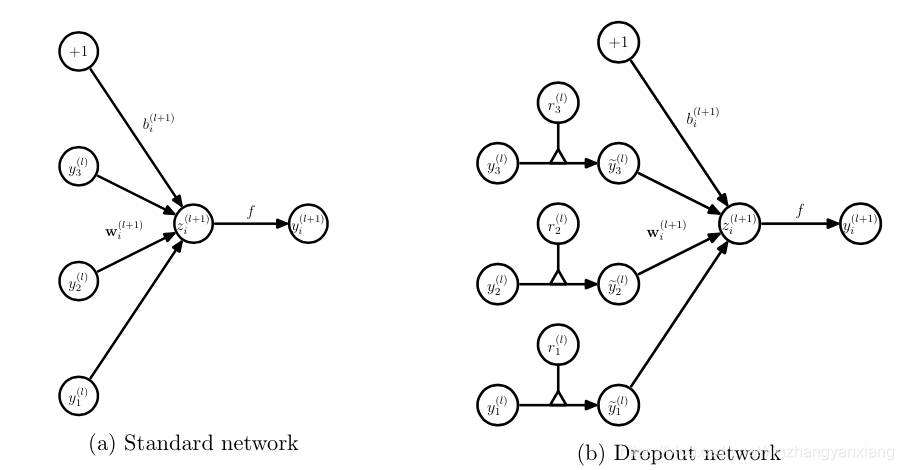
对应的公式变化如下:
——没有dropout的神经网络:
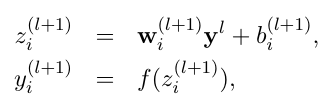
——有dropout的神经网络:
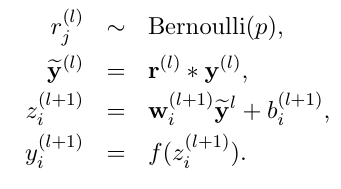
即在训练时,每个神经元都以概率p被保留(即丢弃概率为1-p),在预测阶段,每个神经单元都是存在的,权重参数w要乘以p,输出是pw。
——测试层面
预测的时候,每个单元的参数要预乘以p。

预测阶段乘以p的原因:前一层隐藏层的一个神经元在dropout之前的输出是x,训练时dropout之后的期望值是E=px+(1-p)*0;在预测阶段该层神经元总是激活,为了保持同样的输出期望值并使下一层也得到同样的结果,需要调整x->px,其中p为Bernoulli分布(0-1分布)中值为1的概率。
2. 代码实现
代码如下:
import numpy as np
p = 0.5 # 神经元激活概率
def train_step(X):
""" X contains the data """
# 三层神经网络前向传播为例
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
out = np.dot(W3, H2) + b3 具体实现方式为:用U1=(np.random.rand(*H1.shape)<p)/p得到一个mask,再用神经元输出的激活值乘以这个mask,这里numpy.random.rand得到的是一个满足0到1的均匀分布的数组,。np.random.rand(*H1.shape)<p 得到的是一个布尔值数组当其元素值小于p时是True,大于p时是False,这样就实现了以0.5的概率随机去掉一些神经元。














 2793
2793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









