







1、大数据项目处理流程和步骤
第一步:需求:
数据的输入和数据的产出,大数据技术项目好比一台榨汁机,数据输入相当于例如苹果、柠檬等,然后通过榨汁机产出果汁;
第二步:数据量、处理效率、可靠性、维护性、简洁性
第三步:数据建模
第四步:架构设计:数据怎么进来,输出怎么展示,最最重要的是处理流出的架构;
第五步:我会再次思考大数据系统和企业IT系统的交互;
第六步:最终确定的技术(例如Spark、Kafka、Flume、HBase)选择、规范等
第七步:基于数据建模写基础服务代码
第八步:正式编写第一个模块!编码、测试、调试、改进等等
第九步:实现其它的模块,并完成测试和调试等
第十步:测试和验收
2、大数据项目的技术架构流程图
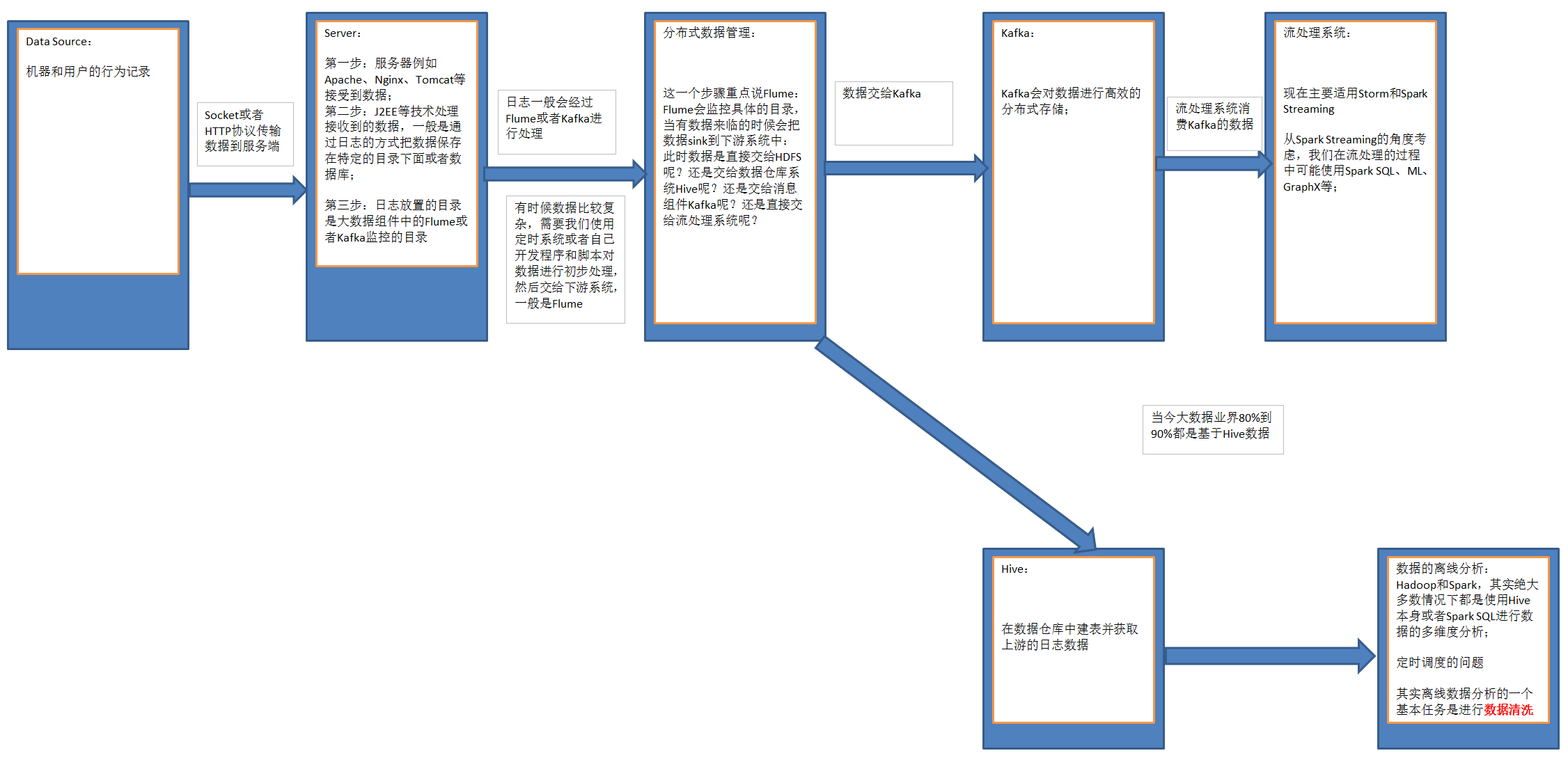
1)后台系统产生数据:机器或者用户的行为数据。
2)通过Socket或者HTTP协议,传输数据到服务端。
第一步:在服务器端,例如Apache、Nginx、Tomcat等WEB系统负责接收到数据;
第二步:WEB系统由J2EE等技术实现,负责处理接收到的数据,一般是通过日志的方式把数据保存在特定的目录下面或者数据库;
第三步:日志放置的目录是大数据组件中的Flume或者Kafka监控的目录。
3)日志一般会经过Flume或者Kafka进行处理,有时候数据比较复杂,需要使用定时系统或者开发程序对数据进行初步处理,然后交给下游系统,一般是Flume。
4)这一个步骤重点说Flume:
Flume会监控具体的目录,当有数据来临的时候会把数据sink到下游系统中:
- 此时数据是直接交给HDFS呢?
- 还是交给数据仓库系统Hive呢?
- 还是交给消息组件Kafka呢?
- 还是直接交给流处理系统呢?
4.1) 方案1:数据交给Kafka
Kafka会对数据进行高效的分布式存储, 流处理系统消费Kafka的数据, 流处理系统:现在主要适用Storm和Spark Streaming,从Spark Streaming的角度考虑,我们在流处理的过程中可能使用Spark SQL、ML、GraphX等;
4.2) 方案2:Flume把数据交给Hive,在Hive中建表并获取上游的日志数据。
然后基于Hive,进行数据的离线分析:
Hadoop和Spark,其实绝大多数情况下都是使用Hive本身或者Spark SQL进行数据的多维度分析。
其实离线数据分析的一个基本任务是进行数据清洗。
当今大数据业界80%到90%都是基于Hive数据仓库的数据分析。
3、附录
flume和kafka有什么区别及联系
这两个差别很大,使用场景区别也很大。
1) flume:日志采集。
线上数据一般主要是落地文件或者通过socket传输给另外一个系统。
这种情况下,很难让线上已有的应用去修改接口,直接向kafka里写数据。
这时候就需要flume这样的系统帮你去做传输。
2) Kafka:更应该定位为中间件系统。
LinkedIn开发这个东西目的也是这个初衷。可以理解为一个cache系统。
甚至可以把它理解为一个广义意义的数据库,里面可以存放一定时间的数据。
kafka设计使用了硬盘append方式,获得了非常好的效果。我觉得这是kafka最大的亮点。
不同系统之间融合往往数据生产/消费速率不同,这时候你可以在这些系统之间加上kafka。
例如线上数据需要入HDFS,线上数据生产快且具有突发性,如果直接上HDFS(kafka-consumer)
可能会使得高峰时间hdfs数据写失败,这种情况你可以把数据先写到kafka,然后从kafka导入到hdfs上。
3) Kafka+flume 典型用法:
线上数据 ==> flume ==> kafka ==> hdfs ==>MR离线计算
或者
线上数据 ==> flume ==> kafka ==> Spark Streaming / storm















 2293
2293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









